 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Performance Sequence-to-Sequence Model for Streaming Speech Recognition
Mar 22, 2020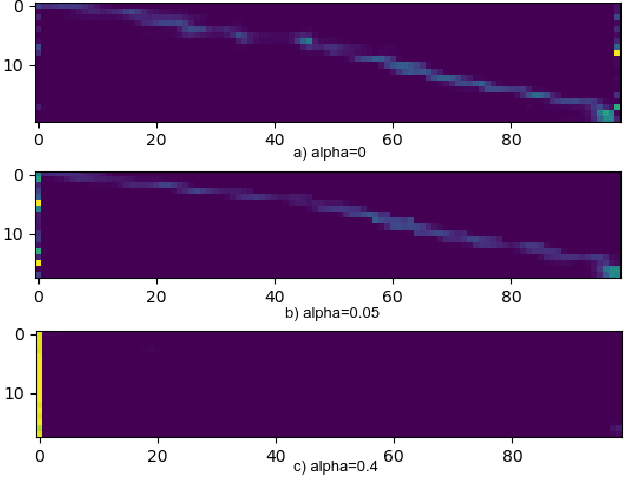
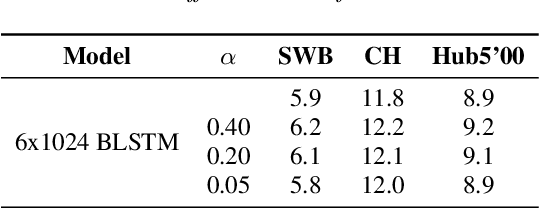
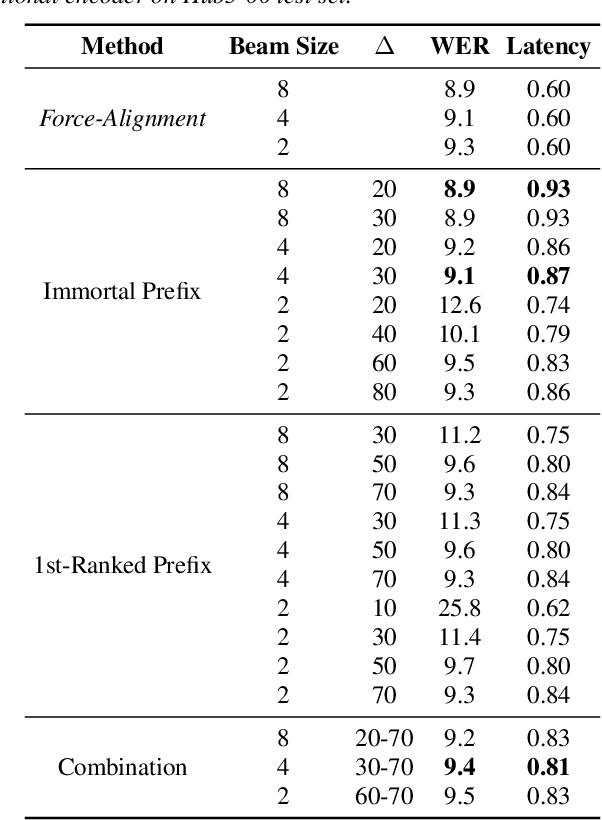
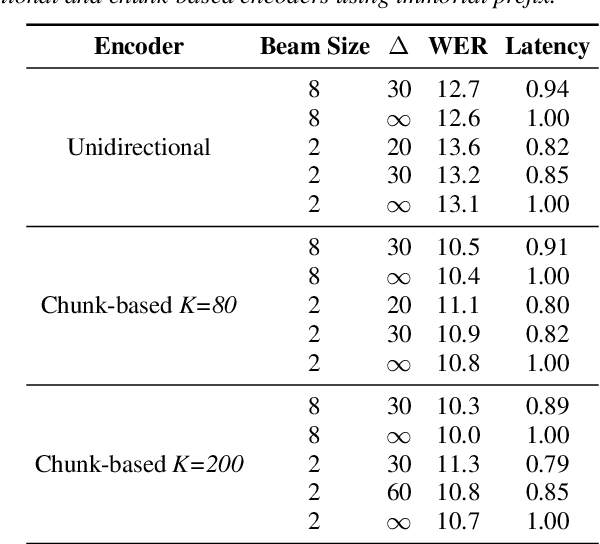
Recently sequence-to-sequence models have started to achieve state-of-the art performance on standard speech recognition tasks when processing audio data in batch mode, i.e., the complete audio data is available when starting processing. However, when it comes to perform run-on recognition on an input stream of audio data while producing recognition results in real-time and with a low word-based latency, these models face several challenges. For many techniques, the whole audio sequence to be decoded needs to be available at the start of the processing, e.g., for the attention mechanism or for the bidirectional LSTM (BLSTM). In this paper we propose several techniques to mitigate these problems. We introduce an additional loss function controlling the uncertainty of the attention mechanism, a modified beam search identifying partial, stable hypotheses, ways of working with BLSTM in the encoder, and the use of chunked BLSTM. Our experiments show that with the right combination of these techniques it is possible to perform run-on speech recognition with a low word-based latency without sacrificing performance in terms of word error rate.
Modeling Confidence in Sequence-to-Sequence Models
Oct 04, 2019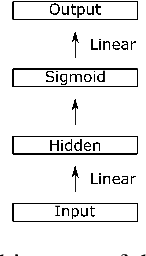
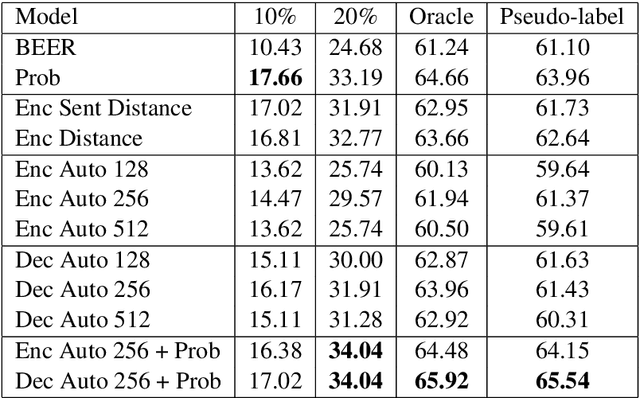
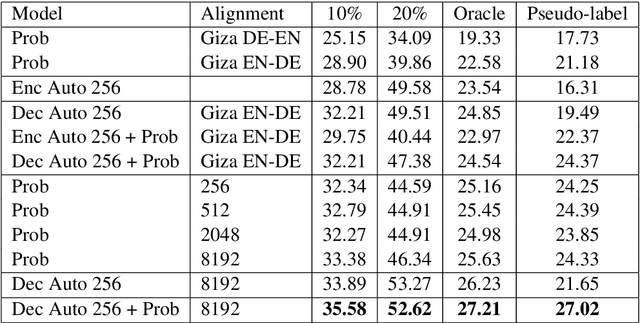
Recently, significant improvements have been achieved in various natural language processing tasks using neural sequence-to-sequence models. While aiming for the best generation quality is important, ultimately it is also necessary to develop models that can assess the quality of their output. In this work, we propose to use the similarity between training and test conditions as a measure for models' confidence. We investigate methods solely using the similarity as well as methods combining it with the posterior probability. While traditionally only target tokens are annotated with confidence measures, we also investigate methods to annotate source tokens with confidence. By learning an internal alignment model, we can significantly improve confidence projection over using state-of-the-art external alignment tools. We evaluate the proposed methods on downstream confidence estimation for machine translation (MT). We show improvements on segment-level confidence estimation as well as on confidence estimation for source tokens. In addition, we show that the same methods can also be applied to other tasks using sequence-to-sequence models. On the automatic speech recognition (ASR) task, we are able to find 60% of the errors by looking at 20% of the data.
Improving Zero-shot Translation with Language-Independent Constraints
Jun 20, 2019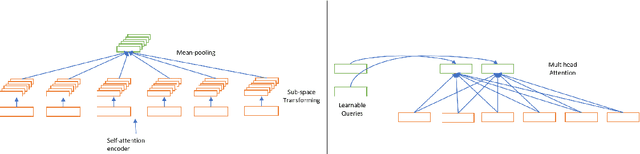
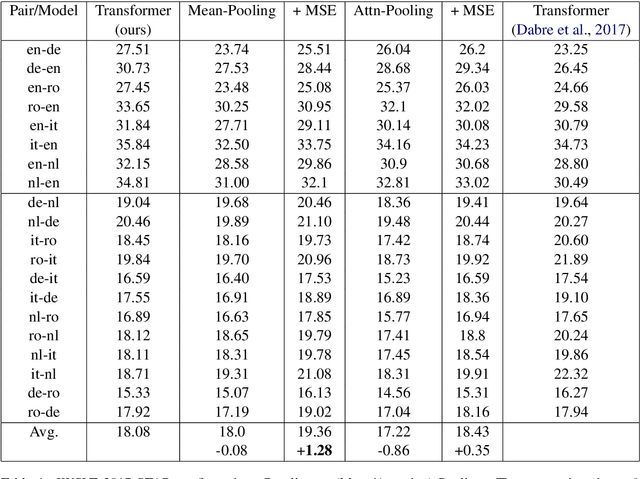
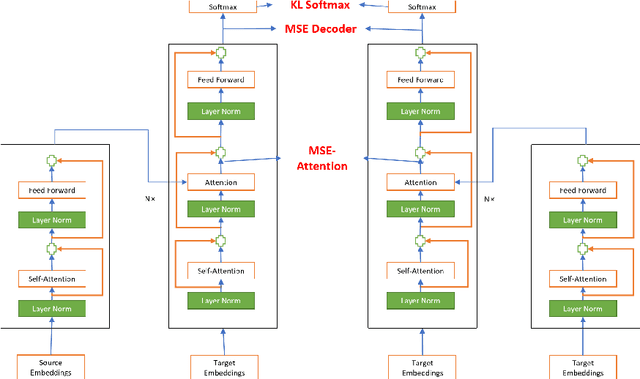
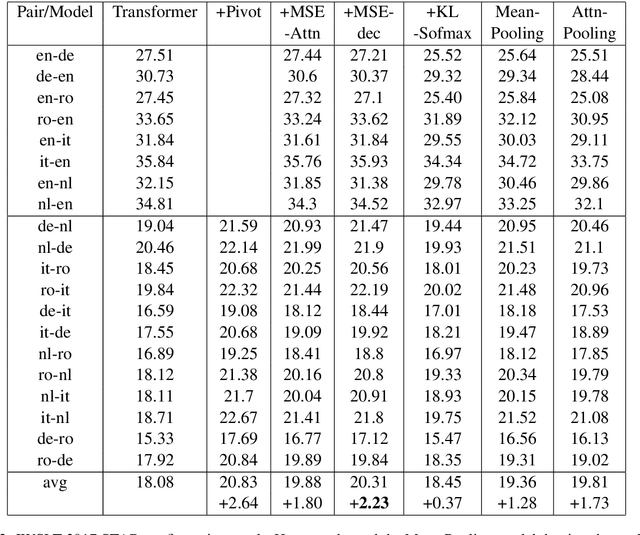
An important concern in training multilingual neural machine translation (NMT) is to translate between language pairs unseen during training, i.e zero-shot translation. Improving this ability kills two birds with one stone by providing an alternative to pivot translation which also allows us to better understand how the model captures information between languages. In this work, we carried out an investigation on this capability of the multilingual NMT models. First, we intentionally create an encoder architecture which is independent with respect to the source language. Such experiments shed light on the ability of NMT encoders to learn multilingual representations, in general. Based on such proof of concept, we were able to design regularization methods into the standard Transformer model, so that the whole architecture becomes more robust in zero-shot conditions. We investigated the behaviour of such models on the standard IWSLT 2017 multilingual dataset. We achieved an average improvement of 2.23 BLEU points across 12 language pairs compared to the zero-shot performance of a state-of-the-art multilingual system. Additionally, we carry out further experiments in which the effect is confirmed even for language pairs with multiple intermediate pivots.
Self-Attentional Models for Lattice Inputs
Jun 04, 2019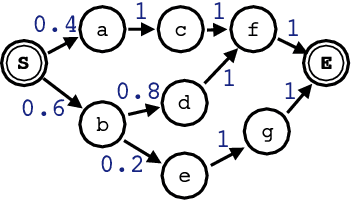
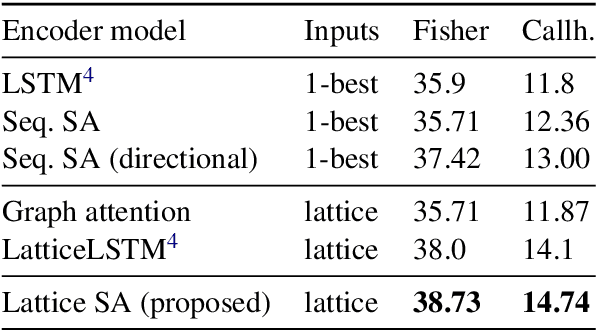
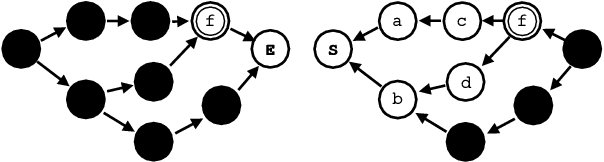
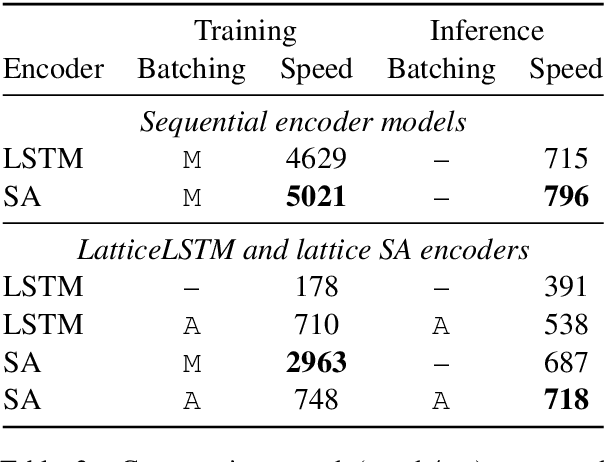
Lattices are an efficient and effective method to encode ambiguity of upstream systems in natural language processing tasks, for example to compactly capture multiple speech recognition hypotheses, or to represent multiple linguistic analyses. Previous work has extended recurrent neural networks to model lattice inputs and achieved improvements in various tasks, but these models suffer from very slow computation speeds. This paper extends the recently proposed paradigm of self-attention to handle lattice inputs. Self-attention is a sequence modeling technique that relates inputs to one another by computing pairwise similarities and has gained popularity for both its strong results and its computational efficiency. To extend such models to handle lattices, we introduce probabilistic reachability masks that incorporate lattice structure into the model and support lattice scores if available. We also propose a method for adapting positional embeddings to lattice structures. We apply the proposed model to a speech translation task and find that it outperforms all examined baselines while being much faster to compute than previous neural lattice models during both training and inference.
Very Deep Self-Attention Networks for End-to-End Speech Recognition
May 03, 2019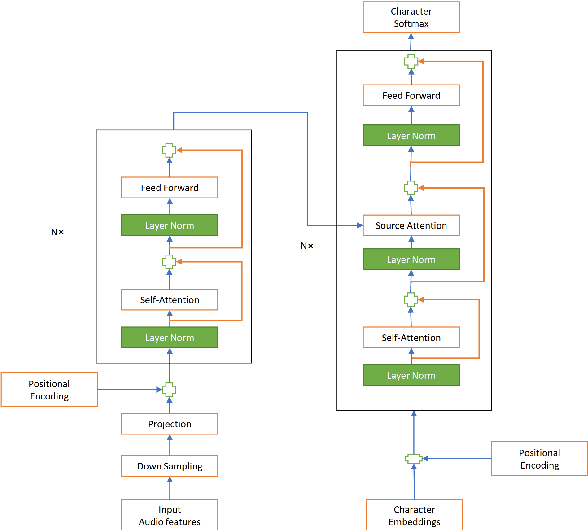
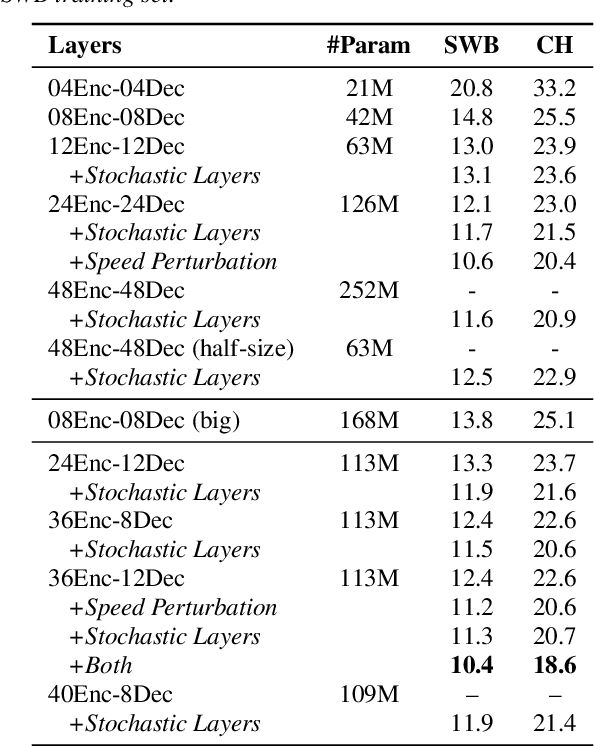
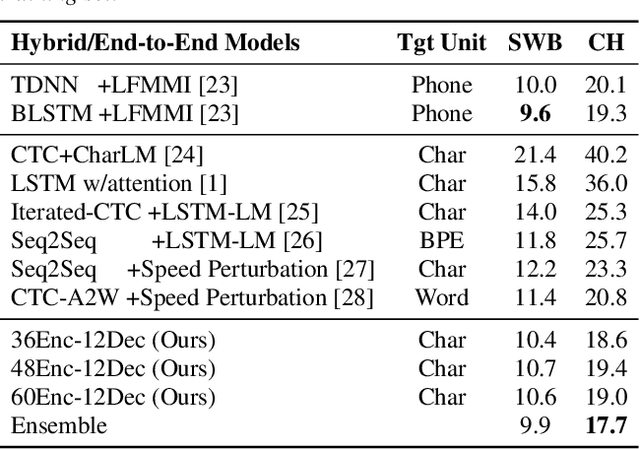

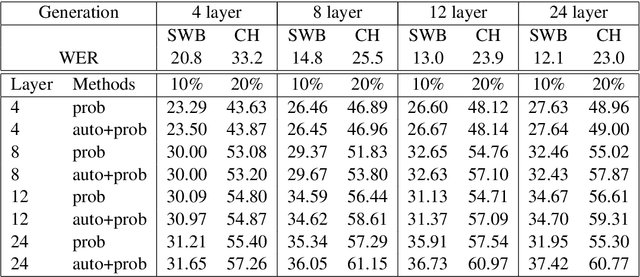
Recently, end-to-end sequence-to-sequence models for speech recognition have gained significant interest in the research community. While previous architecture choices revolve around time-delay neural networks (TDNN) and long short-term memory (LSTM) recurrent neural networks, we propose to use self-attention via the Transformer architecture as an alternative. Our analysis shows that deep Transformer networks with high learning capacity are able to exceed performance from previous end-to-end approaches and even match the conventional hybrid systems. Moreover, we trained very deep models with up to 48 Transformer layers for both encoder and decoders combined with stochastic residual connections, which greatly improve generalizability and training efficiency. The resulting models outperform all previous end-to-end ASR approaches on the Switchboard benchmark. An ensemble of these models achieve 9.9% and 17.7% WER on Switchboard and CallHome test sets respectively. This finding brings our end-to-end models to competitive levels with previous hybrid systems. Further, with model ensembling the Transformers can outperform certain hybrid systems, which are more complicated in terms of both structure and training procedure.
Towards one-shot learning for rare-word translation with external experts
Sep 10, 2018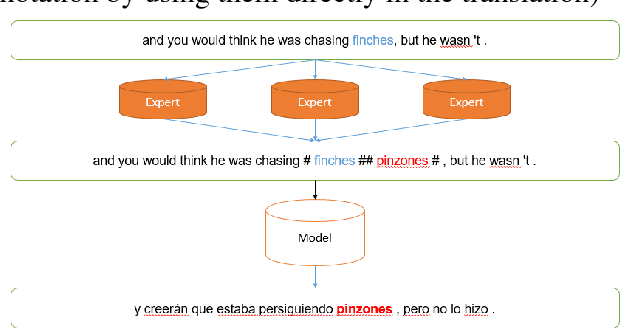
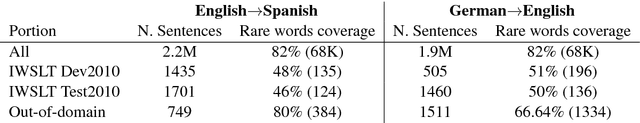
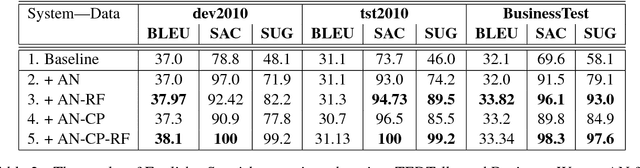

Neural machine translation (NMT) has significantly improved the quality of automatic translation models. One of the main challenges in current systems is the translation of rare words. We present a generic approach to address this weakness by having external models annotate the training data as Experts, and control the model-expert interaction with a pointer network and reinforcement learning. Our experiments using phrase-based models to simulate Experts to complement neural machine translation models show that the model can be trained to copy the annotations into the output consistently. We demonstrate the benefit of our proposed framework in outof-domain translation scenarios with only lexical resources, improving more than 1.0 BLEU point in both translation directions English to Spanish and German to English
Low-Latency Neural Speech Translation
Aug 01, 2018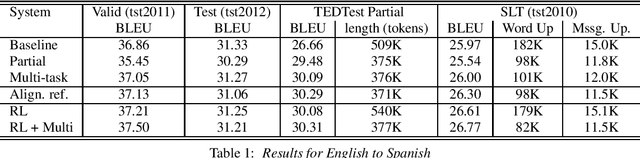
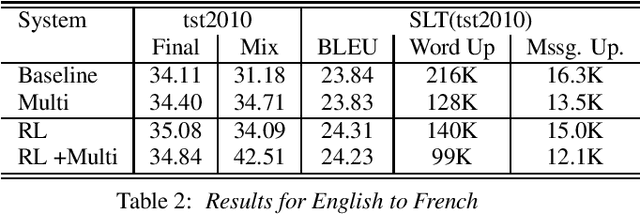
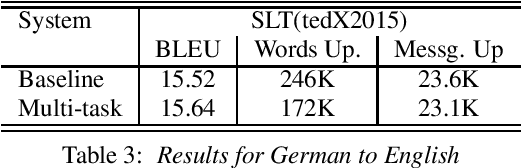
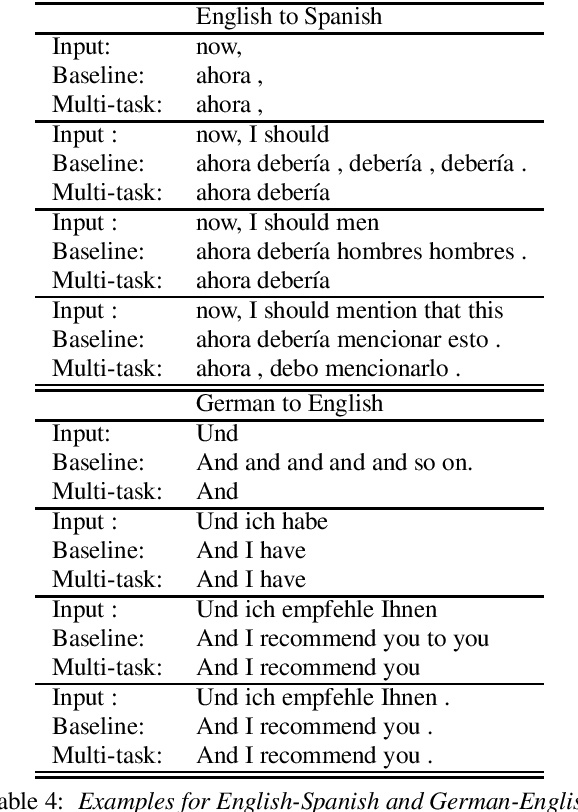
Through the development of neural machine translation, the quality of machine translation systems has been improved significantly. By exploiting advancements in deep learning, systems are now able to better approximate the complex mapping from source sentences to target sentences. But with this ability, new challenges also arise. An example is the translation of partial sentences in low-latency speech translation. Since the model has only seen complete sentences in training, it will always try to generate a complete sentence, though the input may only be a partial sentence. We show that NMT systems can be adapted to scenarios where no task-specific training data is available. Furthermore, this is possible without losing performance on the original training data. We achieve this by creating artificial data and by using multi-task learning. After adaptation, we are able to reduce the number of corrections displayed during incremental output construction by 45%, without a decrease in translation quality.