 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison Between Traditional Machine Learning Models And Neural Network Models For Vietnamese Hate Speech Detection
Jan 31, 2020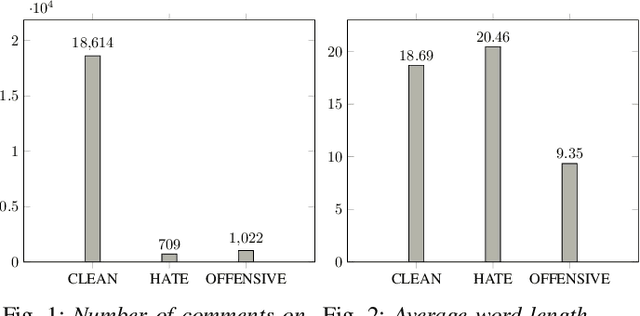
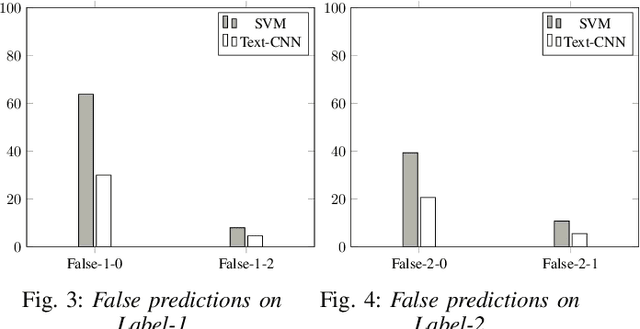
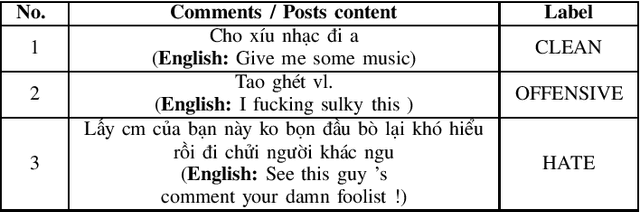

Hate-speech detection on social network language has become one of the main researching fields recently due to the spreading of social networks like Facebook and Twitter. In Vietnam, the threat of offensive and harassment cause bad impacts for online user. The VLSP - Shared task about Hate Speech Detection on social networks showed many proposed approaches for detecting whatever comment is clean or not. However, this problem still needs further researching. Consequently, we compare traditional machine learning and deep learning on a large dataset about the user's comments on social network in Vietnamese and find out what is the advantage and disadvantage of each model by comparing their accuracy on F1-score, then we pick two models in which has highest accuracy in traditional machine learning models and deep neural models respectively. Next, we compare these two models capable of predicting the right label by referencing their confusion matrices and considering the advantages and disadvantages of each model. Finally, from the comparison result, we propose our ensemble method that concentrates the abilities of traditional methods and deep learning methods.
A Pilot Study on Multiple Choice Machine Reading Comprehension for Vietnamese Texts
Jan 16, 2020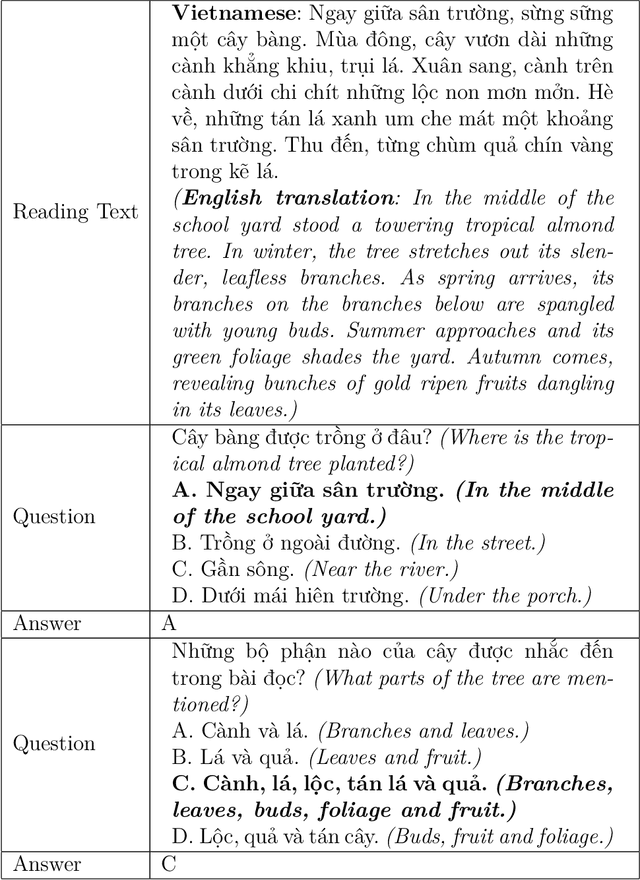
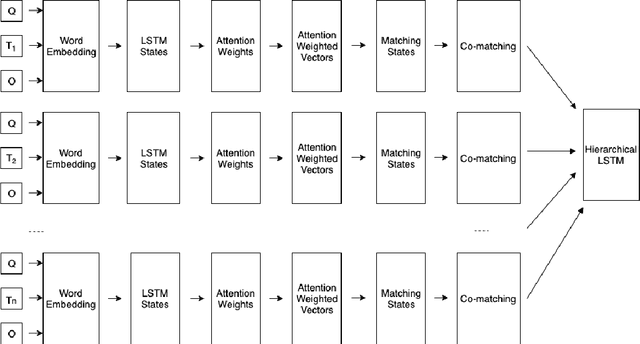
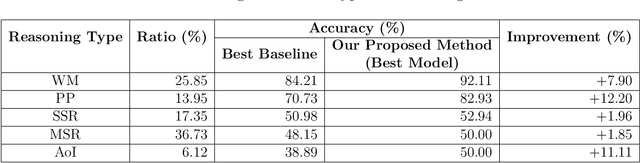

Machine Reading Comprehension (MRC) is the task of natural language processing which studies the ability to read and understand unstructured texts and then find the correct answers for questions. Until now, we have not yet had any MRC dataset for such a low-resource language as Vietnamese. In this paper, we introduce ViMMRC, a challenging machine comprehension corpus with multiple-choice questions, intended for research on the machine comprehension of Vietnamese text. This corpus includes 2,783 multiple-choice questions and answers based on a set of 417 Vietnamese texts used for teaching reading comprehension for 1st to 5th graders. Answers may be extracted from the contents of single or multiple sentences in the corresponding reading text. A thorough analysis of the corpus and experimental results in this paper illustrate that our corpus ViMMRC demands reasoning abilities beyond simple word matching. We proposed the method of Boosted Sliding Window (BSW) that improves 5.51% in accuracy over the best baseline method. We also measured human performance on the corpus and compared it to our MRC models. The performance gap between humans and our best experimental model indicates that significant progress can be made on Vietnamese machine reading comprehension in further research. The corpus is freely available at our website for research purposes.
Hate Speech Detection on Vietnamese Social Media Text using the Bi-GRU-LSTM-CNN Model
Dec 22, 2019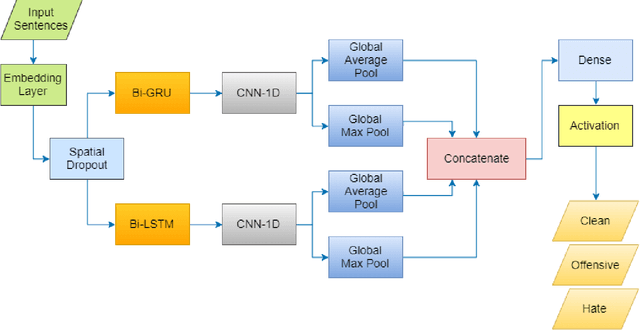
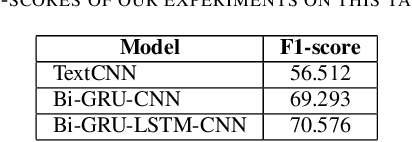
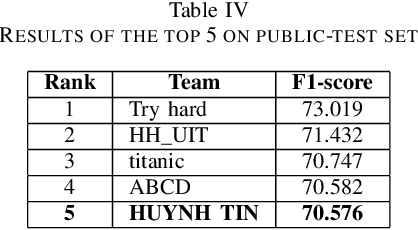
In recent years, Hate Speech Detection has become one of the interesting fields in natural language processing or computational linguistics. In this paper, we present the description of our system to solve this problem at the VLSP shared task 2019: Hate Speech Detection on Social Networks with the corpus which contains 20,345 human-labeled comments/posts for training and 5,086 for public-testing. We implement a deep learning method based on the Bi-GRU-LSTM-CNN classifier into this task. Our result in this task is 70.576% of F1-score, ranking the 5th of performance on public-test set.
* Technical Report, VLSP Workshop 2019
Emotion Recognition for Vietnamese Social Media Text
Nov 21, 2019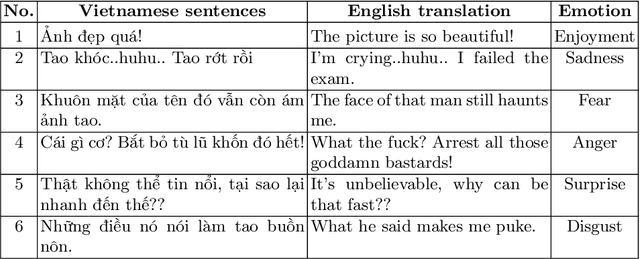
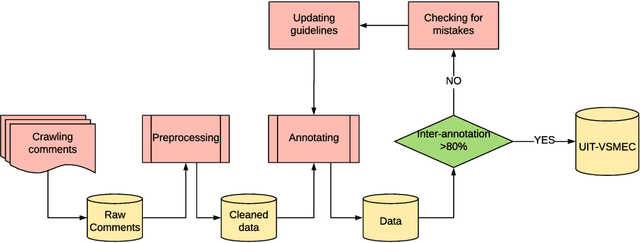
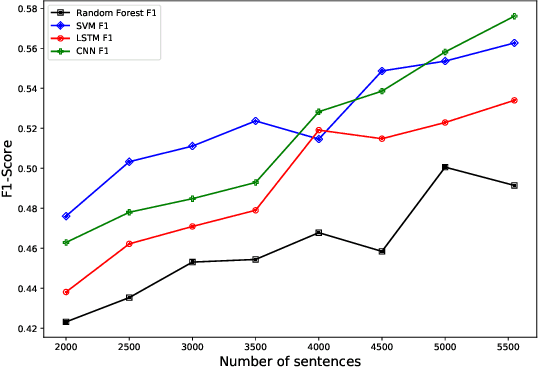
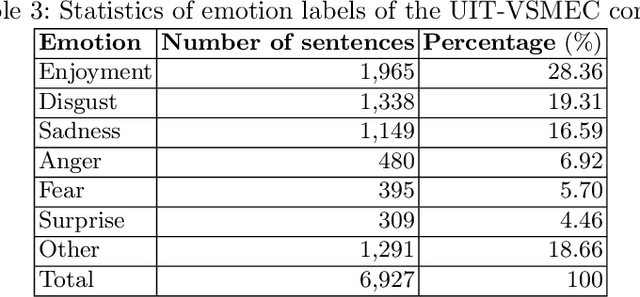
Emotion recognition or emotion prediction is a higher approach or a special case of sentiment analysis. In this task, the result is not produced in terms of either polarity: positive or negative or in the form of rating (from 1 to 5) but of a more detailed level of analysis in which the results are depicted in more expressions like sadness, enjoyment, anger, disgust, fear, and surprise. Emotion recognition plays a critical role in measuring the brand value of a product by recognizing specific emotions of customers' comments. In this study, we have achieved two targets. First and foremost, we built a standard Vietnamese Social Media Emotion Corpus (UIT-VSMEC) with exactly 6,927 emotion-annotated sentences, contributing to emotion recognition research in Vietnamese which is a low-resource language in natural language processing (NLP). Secondly, we assessed and measured machine learning and deep neural network models on our UIT-VSMEC corpus. As a result, the CNN model achieved the highest performance with the weighted F1-score of 59.74%. Our corpus is available at our research website.
* PACLING 2019
Error Analysis for Vietnamese Named Entity Recognition on Deep Neural Network Models
Nov 19, 2019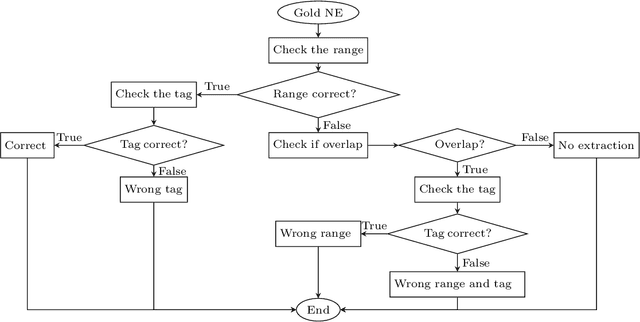
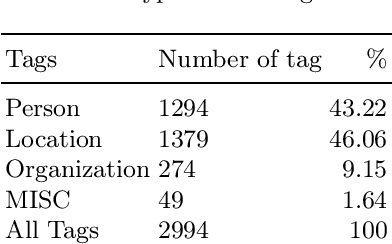
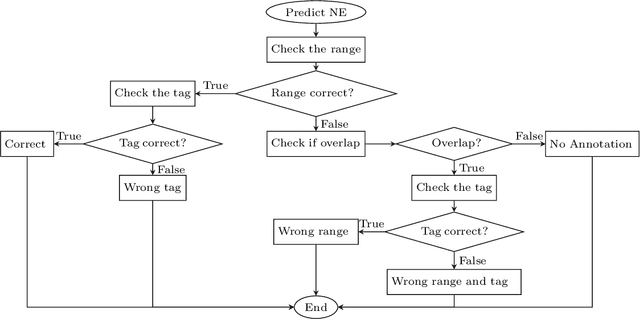

In recent years, Vietnamese Named Entity Recognition (NER) systems have had a great breakthrough when using Deep Neural Network methods. This paper describes the primary errors of the state-of-the-art NER systems on Vietnamese language. After conducting experiments on BLSTM-CNN-CRF and BLSTM-CRF models with different word embeddings on the Vietnamese NER dataset. This dataset is provided by VLSP in 2016 and used to evaluate most of the current Vietnamese NER systems. We noticed that BLSTM-CNN-CRF gives better results, therefore, we analyze the errors on this model in detail. Our error-analysis results provide us thorough insights in order to increase the performance of NER for the Vietnamese language and improve the quality of the corpus in the future works.
* 19th International Conference on Computational Linguistics and Intelligent Text Processing (CICLING 2018)
Deep Learning versus Traditional Classifiers on Vietnamese Students' Feedback Corpus
Nov 17, 2019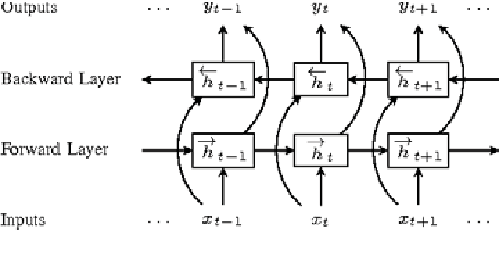
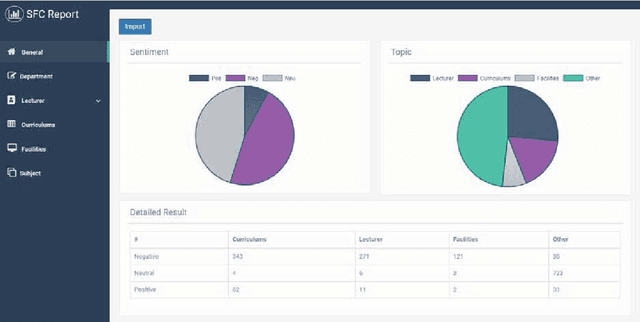
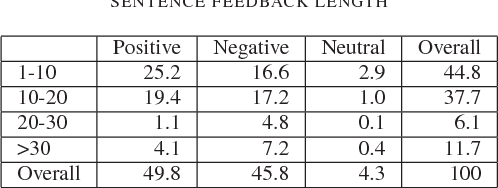
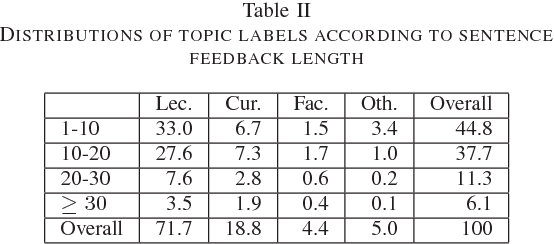
Student's feedback is an important source of collecting students' opinions to improve the quality of training activities. Implementing sentiment analysis into student feedback data, we can determine sentiments polarities which express all problems in the institution since changes necessary will be applied to improve the quality of teaching and learning. This study focused on machine learning and natural language processing techniques (NaiveBayes, Maximum Entropy, Long Short-Term Memory, Bi-Directional Long Short-Term Memory) on the VietnameseStudents' Feedback Corpus collected from a university. The final results were compared and evaluated to find the most effective model based on different evaluation criteria. The experimental results show that the Bi-Directional LongShort-Term Memory algorithm outperformed than three other algorithms in terms of the F1-score measurement with 92.0% on the sentiment classification task and 89.6% on the topic classification task. In addition, we developed a sentiment analysis application analyzing student feedback. The application will help the institution to recognize students' opinions about a problem and identify shortcomings that still exist. With the use of this application, the institution can propose an appropriate method to improve the quality of training activities in the future.
* In Proceeding of the 5th NAFOSTED Conference on Information and Computer Science (NICS 2018)
Vietnamese transition-based dependency parsing with supertag features
Nov 09, 2019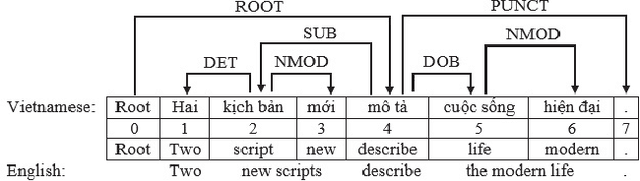
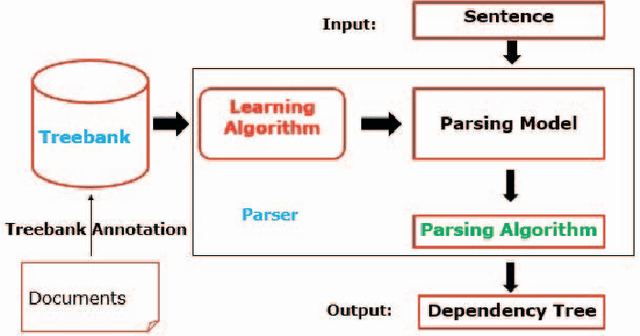
In recent years, dependency parsing is a fascinating research topic and has a lot of applications in natural language processing. In this paper, we present an effective approach to improve dependency parsing by utilizing supertag features. We performed experiments with the transition-based dependency parsing approach because it can take advantage of rich features. Empirical evaluation on Vietnamese Dependency Treebank showed that, we achieved an improvement of 18.92% in labeled attachment score with gold supertags and an improvement of 3.57% with automatic supertags.
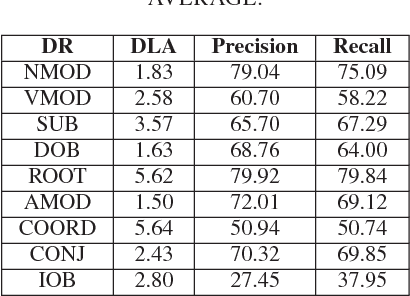
Error Analysis for Vietnamese Dependency Parsing
Nov 09, 2019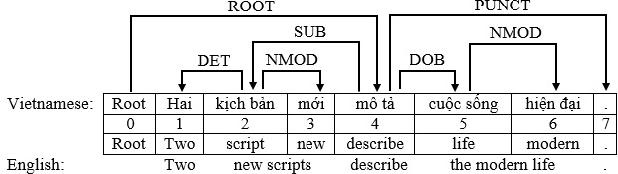
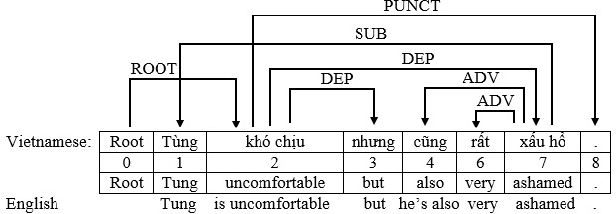

Dependency parsing is needed in different applications of natural language processing. In this paper, we present a thorough error analysis for dependency parsing for the Vietnamese language, using two state-of-the-art parsers: MSTParser and MaltParser. The error analysis results provide us insights in order to improve the performance of dependency parsing for the Vietnamese language.
Hate Speech Detection on Vietnamese Social Media Text using the Bidirectional-LSTM Model
Nov 09, 2019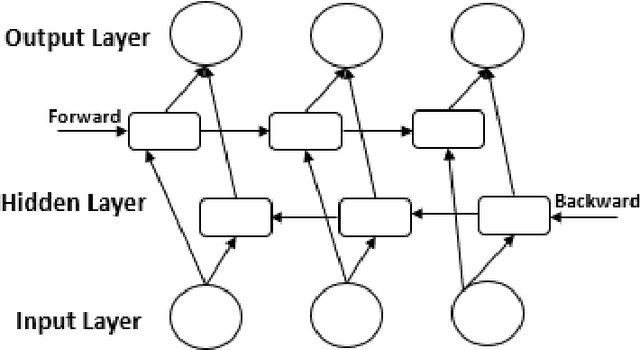

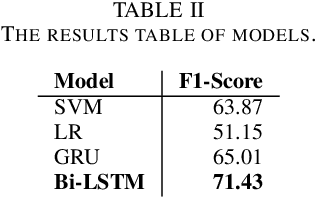
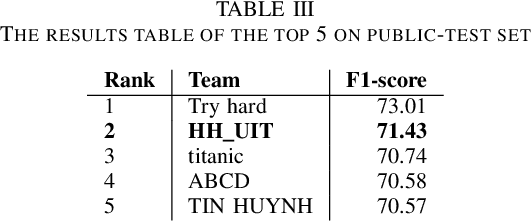
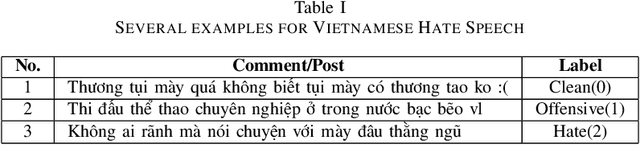
In this paper, we describe our system which participates in the shared task of Hate Speech Detection on Social Networks of VLSP 2019 evaluation campaign. We are provided with the pre-labeled dataset and an unlabeled dataset for social media comments or posts. Our mission is to pre-process and build machine learning models to classify comments/posts. In this report, we use Bidirectional Long Short-Term Memory to build the model that can predict labels for social media text according to Clean, Offensive, Hate. With this system, we achieve comparative results with 71.43% on the public standard test set of VLSP 2019.
LSTM Easy-first Dependency Parsing with Pre-trained Word Embeddings and Character-level Word Embeddings in Vietnamese
Oct 30, 2019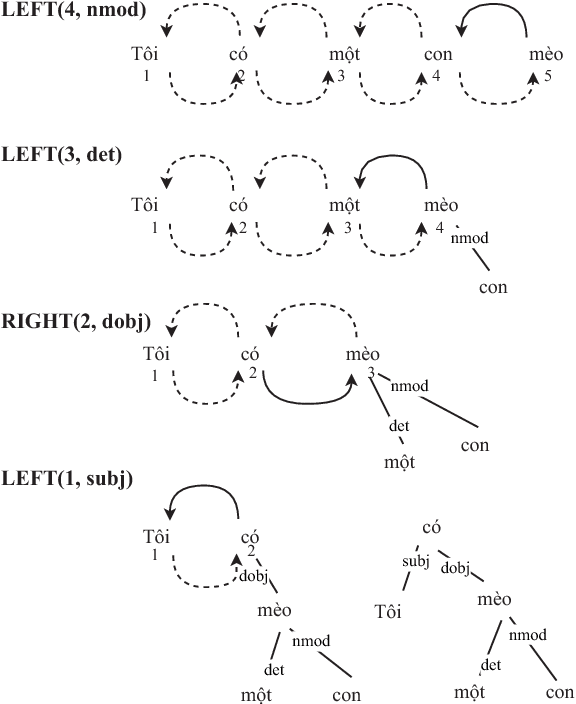
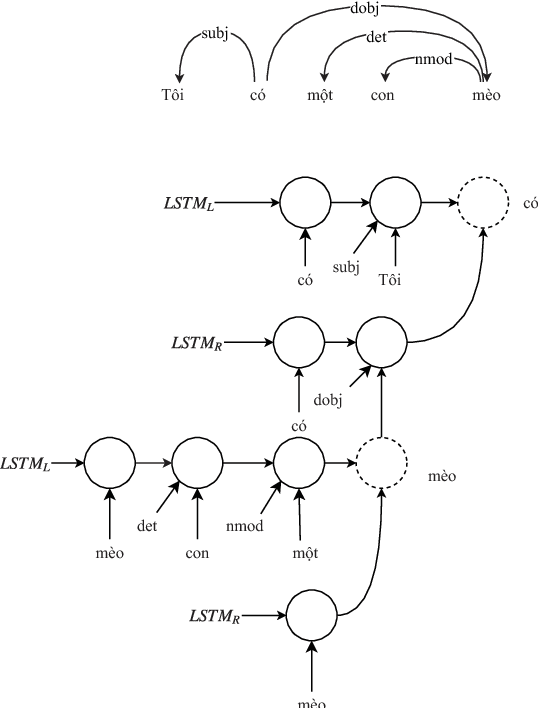
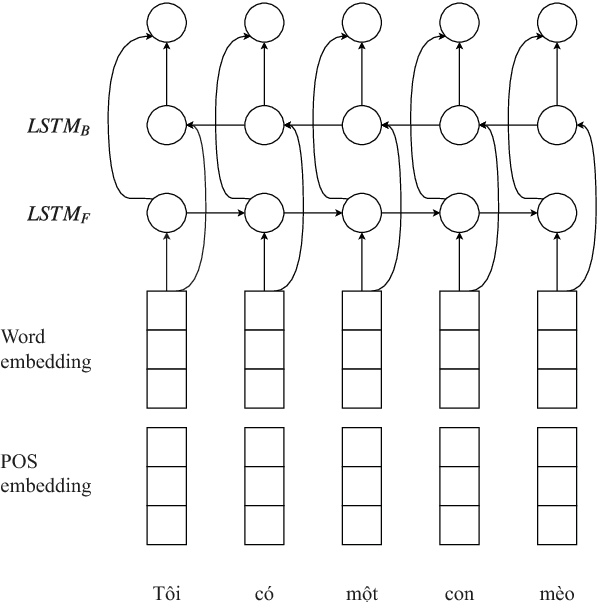
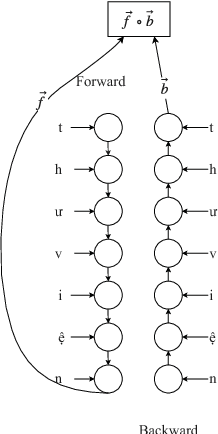
In Vietnamese dependency parsing, several methods have been proposed. Dependency parser which uses deep neural network model has been reported that achieved state-of-the-art results. In this paper, we proposed a new method which applies LSTM easy-first dependency parsing with pre-trained word embeddings and character-level word embeddings. Our method achieves an accuracy of 80.91% of unlabeled attachment score and 72.98% of labeled attachment score on the Vietnamese Dependency Treebank (VnDT).