 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Semantic Information into Sketchy Reading Module of Retro-Reader for Vietnamese Machine Reading Comprehension
Jan 01, 2023



Machine Reading Comprehension has become one of the most advanced and popular research topics in the fields of Natural Language Processing in recent years. The classification of answerability questions is a relatively significant sub-task in machine reading comprehension; however, there haven't been many studies. Retro-Reader is one of the studies that has solved this problem effectively. However, the encoders of most traditional machine reading comprehension models in general and Retro-Reader, in particular, have not been able to exploit the contextual semantic information of the context completely. Inspired by SemBERT, we use semantic role labels from the SRL task to add semantics to pre-trained language models such as mBERT, XLM-R, PhoBERT. This experiment was conducted to compare the influence of semantics on the classification of answerability for the Vietnamese machine reading comprehension. Additionally, we hope this experiment will enhance the encoder for the Retro-Reader model's Sketchy Reading Module. The improved Retro-Reader model's encoder with semantics was first applied to the Vietnamese Machine Reading Comprehension task and obtained positive results.
Is word segmentation necessary for Vietnamese sentiment classification?
Jan 01, 2023



To the best of our knowledge, this paper made the first attempt to answer whether word segmentation is necessary for Vietnamese sentiment classification. To do this, we presented five pre-trained monolingual S4- based language models for Vietnamese, including one model without word segmentation, and four models using RDRsegmenter, uitnlp, pyvi, or underthesea toolkits in the pre-processing data phase. According to comprehensive experimental results on two corpora, including the VLSP2016-SA corpus of technical article reviews from the news and social media and the UIT-VSFC corpus of the educational survey, we have two suggestions. Firstly, using traditional classifiers like Naive Bayes or Support Vector Machines, word segmentation maybe not be necessary for the Vietnamese sentiment classification corpus, which comes from the social domain. Secondly, word segmentation is necessary for Vietnamese sentiment classification when word segmentation is used before using the BPE method and feeding into the deep learning model. In this way, the RDRsegmenter is the stable toolkit for word segmentation among the uitnlp, pyvi, and underthesea toolkits.
Leveraging Semantic Representations Combined with Contextual Word Representations for Recognizing Textual Entailment in Vietnamese
Jan 01, 2023



RTE is a significant problem and is a reasonably active research community. The proposed research works on the approach to this problem are pretty diverse with many different directions. For Vietnamese, the RTE problem is moderately new, but this problem plays a vital role in natural language understanding systems. Currently, methods to solve this problem based on contextual word representation learning models have given outstanding results. However, Vietnamese is a semantically rich language. Therefore, in this paper, we want to present an experiment combining semantic word representation through the SRL task with context representation of BERT relative models for the RTE problem. The experimental results give conclusions about the influence and role of semantic representation on Vietnamese in understanding natural language. The experimental results show that the semantic-aware contextual representation model has about 1% higher performance than the model that does not incorporate semantic representation. In addition, the effects on the data domain in Vietnamese are also higher than those in English. This result also shows the positive influence of SRL on RTE problem in Vietnamese.
A Comparative Study of Question Answering over Knowledge Bases
Nov 15, 2022



Question answering over knowledge bases (KBQA) has become a popular approach to help users extract information from knowledge bases. Although several systems exist, choosing one suitable for a particular application scenario is difficult. In this article, we provide a comparative study of six representative KBQA systems on eight benchmark datasets. In that, we study various question types, properties, languages, and domains to provide insights on where existing systems struggle. On top of that, we propose an advanced mapping algorithm to aid existing models in achieving superior results. Moreover, we also develop a multilingual corpus COVID-KGQA, which encourages COVID-19 research and multilingualism for the diversity of future AI. Finally, we discuss the key findings and their implications as well as performance guidelines and some future improvements. Our source code is available at \url{https://github.com/tamlhp/kbqa}.
SMTCE: A Social Media Text Classification Evaluation Benchmark and BERTology Models for Vietnamese
Sep 21, 2022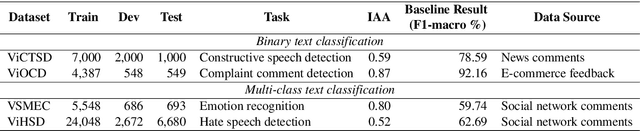
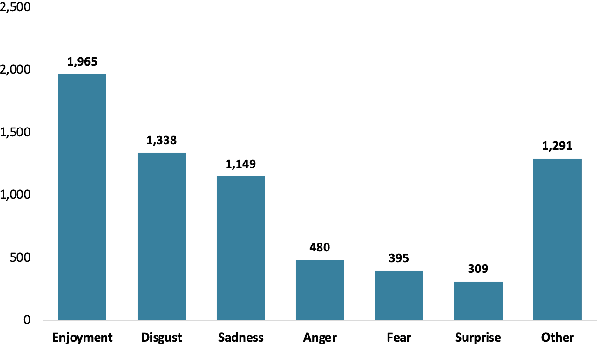
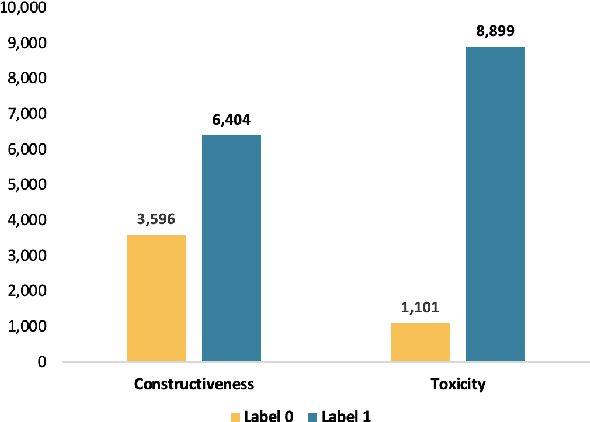
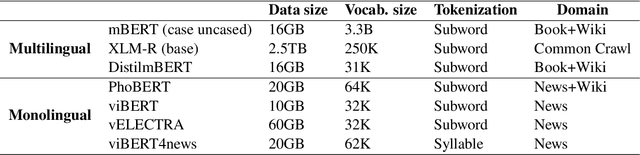
Text classification is a typical natural language processing or computational linguistics task with various interesting applications. As the number of users on social media platforms increases, data acceleration promotes emerging studies on Social Media Text Classification (SMTC) or social media text mining on these valuable resources. In contrast to English, Vietnamese, one of the low-resource languages, is still not concentrated on and exploited thoroughly. Inspired by the success of the GLUE, we introduce the Social Media Text Classification Evaluation (SMTCE) benchmark, as a collection of datasets and models across a diverse set of SMTC tasks. With the proposed benchmark, we implement and analyze the effectiveness of a variety of multilingual BERT-based models (mBERT, XLM-R, and DistilmBERT) and monolingual BERT-based models (PhoBERT, viBERT, vELECTRA, and viBERT4news) for tasks in the SMTCE benchmark. Monolingual models outperform multilingual models and achieve state-of-the-art results on all text classification tasks. It provides an objective assessment of multilingual and monolingual BERT-based models on the benchmark, which will benefit future studies about BERTology in the Vietnamese language.
SPBERTQA: A Two-Stage Question Answering System Based on Sentence Transformers for Medical Texts
Jun 20, 2022

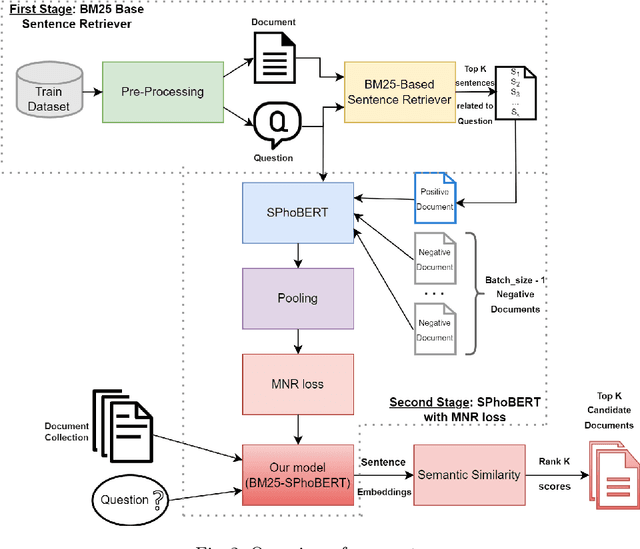
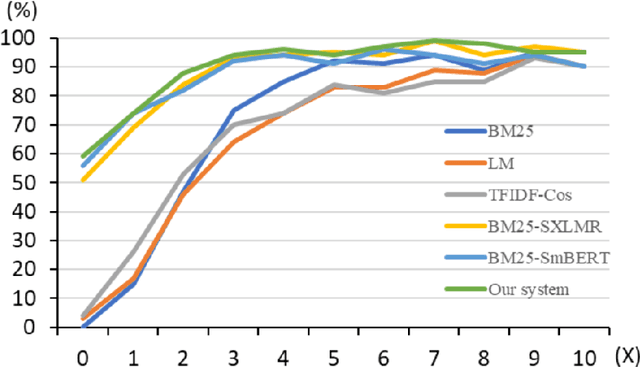
Question answering (QA) systems have gained explosive attention in recent years. However, QA tasks in Vietnamese do not have many datasets. Significantly, there is mostly no dataset in the medical domain. Therefore, we built a Vietnamese Healthcare Question Answering dataset (ViHealthQA), including 10,015 question-answer passage pairs for this task, in which questions from health-interested users were asked on prestigious health websites and answers from highly qualified experts. This paper proposes a two-stage QA system based on Sentence-BERT (SBERT) using multiple negatives ranking (MNR) loss combined with BM25. Then, we conduct diverse experiments with many bag-of-words models to assess our system's performance. With the obtained results, this system achieves better performance than traditional methods.
XLMRQA: Open-Domain Question Answering on Vietnamese Wikipedia-based Textual Knowledge Source
Apr 14, 2022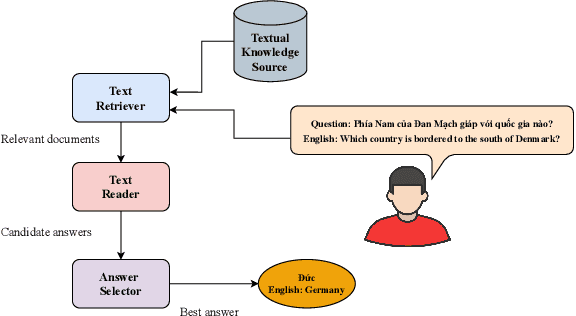
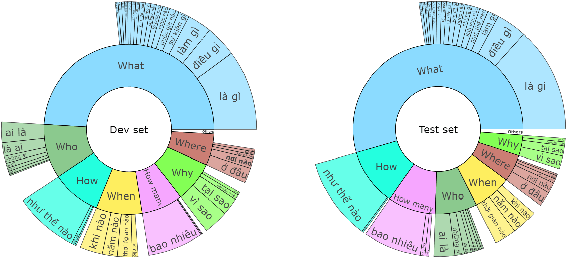
Question answering (QA) is a natural language understanding task within the fields of information retrieval and information extraction that has attracted much attention from the computational linguistics and artificial intelligence research community in recent years because of the strong development of machine reading comprehension-based models. A reader-based QA system is a high-level search engine that can find correct answers to queries or questions in open-domain or domain-specific texts using machine reading comprehension (MRC) techniques. The majority of advancements in data resources and machine-learning approaches in the MRC and QA systems, on the other hand, especially in two resource-rich languages such as English and Chinese. A low-resource language like Vietnamese has witnessed a scarcity of research on QA systems. This paper presents XLMRQA, the first Vietnamese QA system using a supervised transformer-based reader on the Wikipedia-based textual knowledge source (using the UIT-ViQuAD corpus), outperforming the two robust QA systems using deep neural network models: DrQA and BERTserini with 24.46% and 6.28%, respectively. From the results obtained on the three systems, we analyze the influence of question types on the performance of the QA systems.
VLSP 2021 - ViMRC Challenge: Vietnamese Machine Reading Comprehension
Apr 04, 2022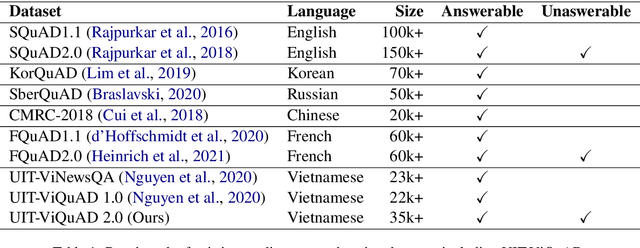
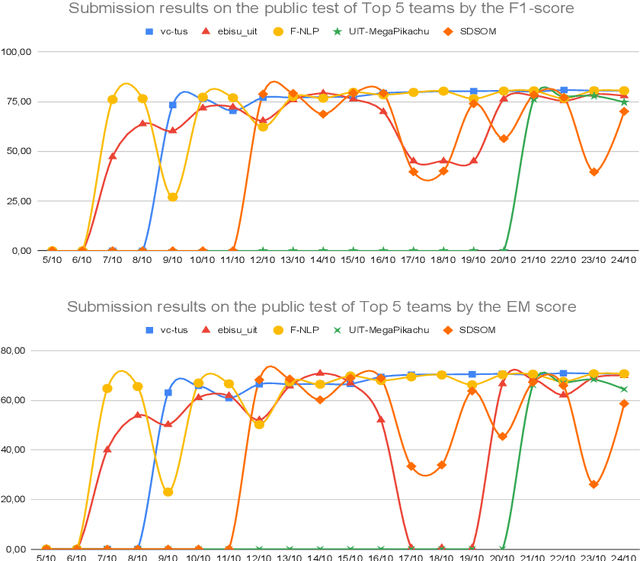

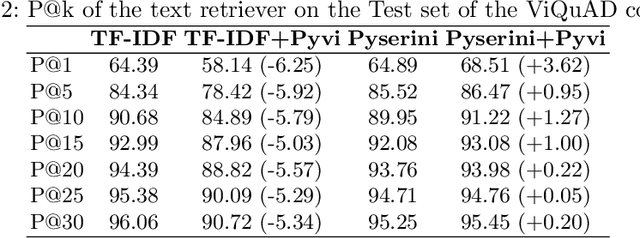
One of the emerging research trends in natural language understanding is machine reading comprehension (MRC) which is the task to find answers to human questions based on textual data. Existing Vietnamese datasets for MRC research concentrate solely on answerable questions. However, in reality, questions can be unanswerable for which the correct answer is not stated in the given textual data. To address the weakness, we provide the research community with a benchmark dataset named UIT-ViQuAD 2.0 for evaluating the MRC task and question answering systems for the Vietnamese language. We use UIT-ViQuAD 2.0 as a benchmark dataset for the challenge on Vietnamese MRC at the Eighth Workshop on Vietnamese Language and Speech Processing (VLSP 2021). This task attracted 77 participant teams from 34 universities and other organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 77.24% in F1-score and 67.43% in Exact Match on the private test set. The Vietnamese MRC systems proposed by the top 3 teams use XLM-RoBERTa, a powerful pre-trained language model based on the transformer architecture. The UIT-ViQuAD 2.0 dataset motivates researchers to further explore the Vietnamese machine reading comprehension task and related tasks such as question answering, question generation, and natural language inference.
Joint Chinese Word Segmentation and Part-of-speech Tagging via Two-stage Span Labeling
Dec 17, 2021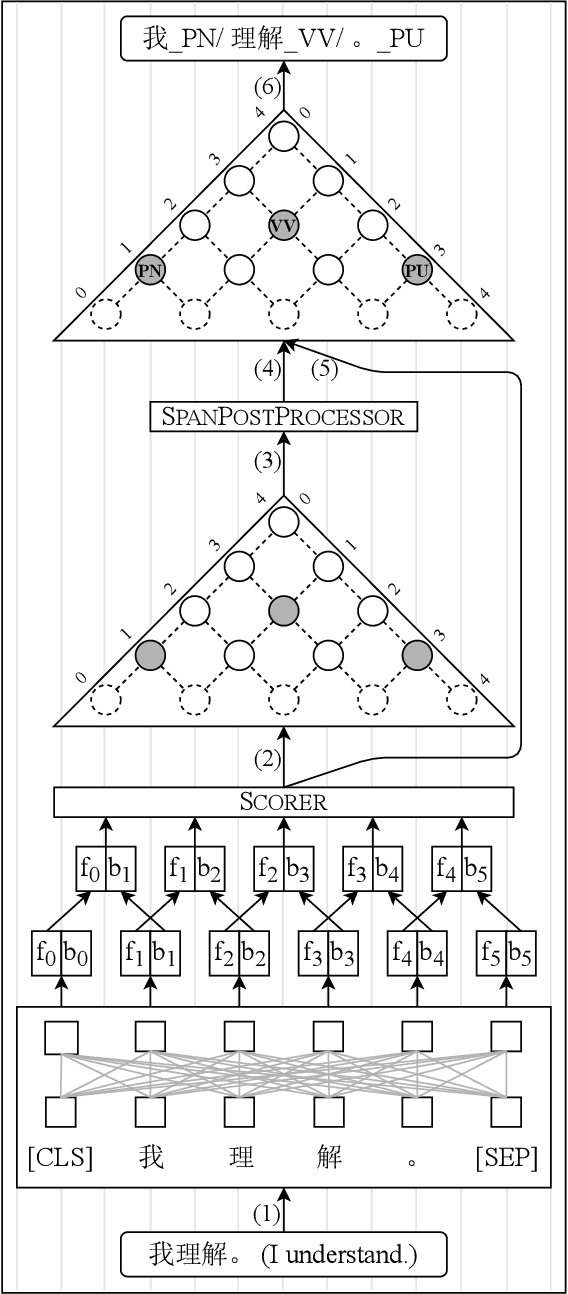
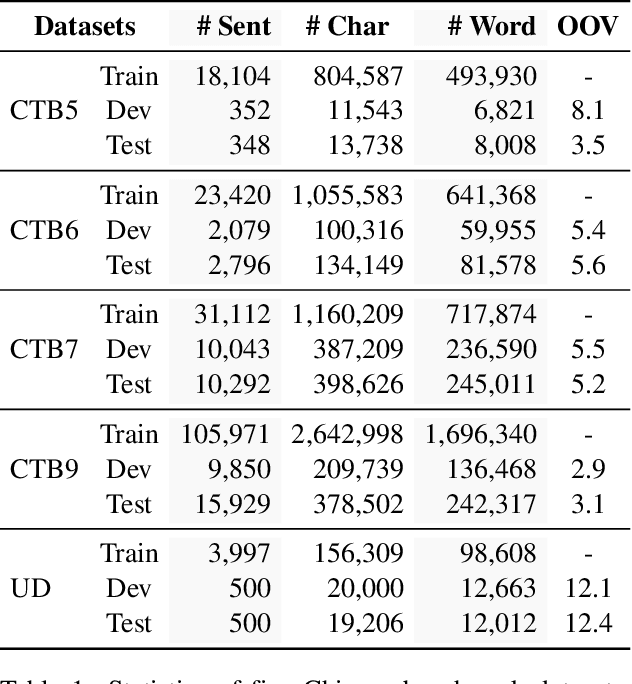
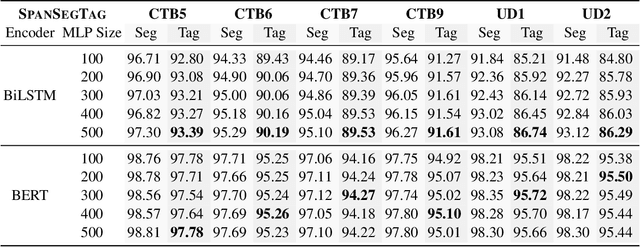
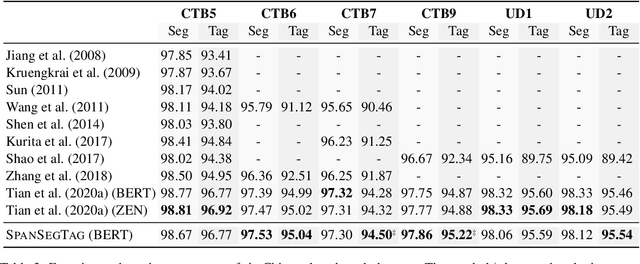
Chinese word segmentation and part-of-speech tagging are necessary tasks in terms of computational linguistics and application of natural language processing. Many re-searchers still debate the demand for Chinese word segmentation and part-of-speech tagging in the deep learning era. Nevertheless, resolving ambiguities and detecting unknown words are challenging problems in this field. Previous studies on joint Chinese word segmentation and part-of-speech tagging mainly follow the character-based tagging model focusing on modeling n-gram features. Unlike previous works, we propose a neural model named SpanSegTag for joint Chinese word segmentation and part-of-speech tagging following the span labeling in which the probability of each n-gram being the word and the part-of-speech tag is the main problem. We use the biaffine operation over the left and right boundary representations of consecutive characters to model the n-grams. Our experiments show that our BERT-based model SpanSegTag achieved competitive performances on the CTB5, CTB6, and UD, or significant improvements on CTB7 and CTB9 benchmark datasets compared with the current state-of-the-art method using BERT or ZEN encoders.
Span Labeling Approach for Vietnamese and Chinese Word Segmentation
Oct 01, 2021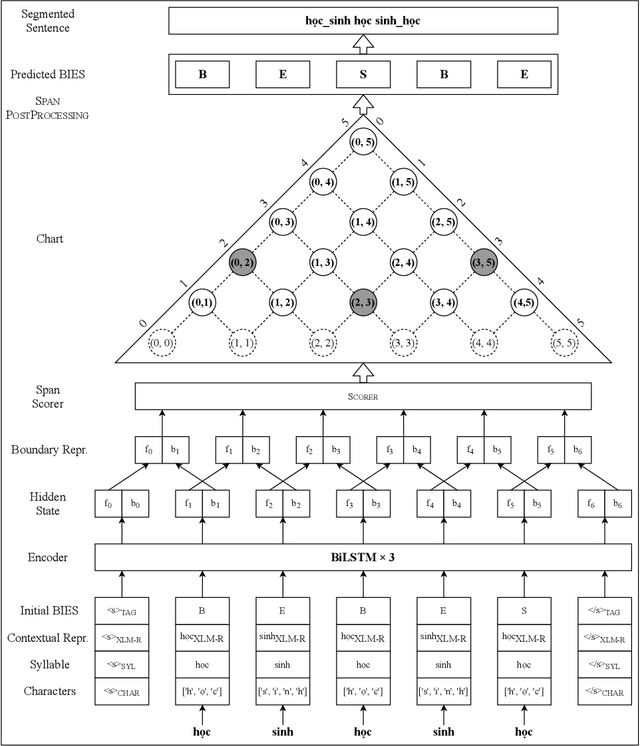
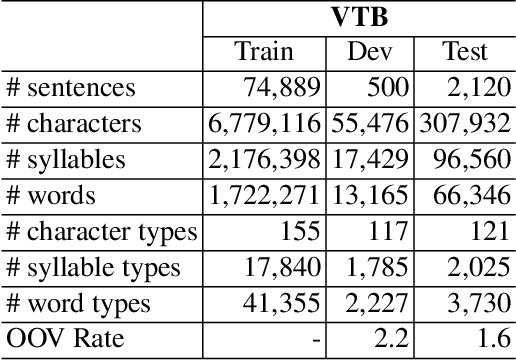
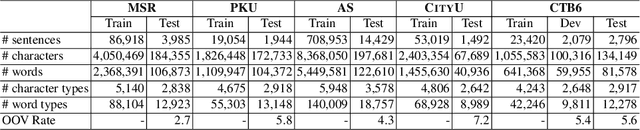
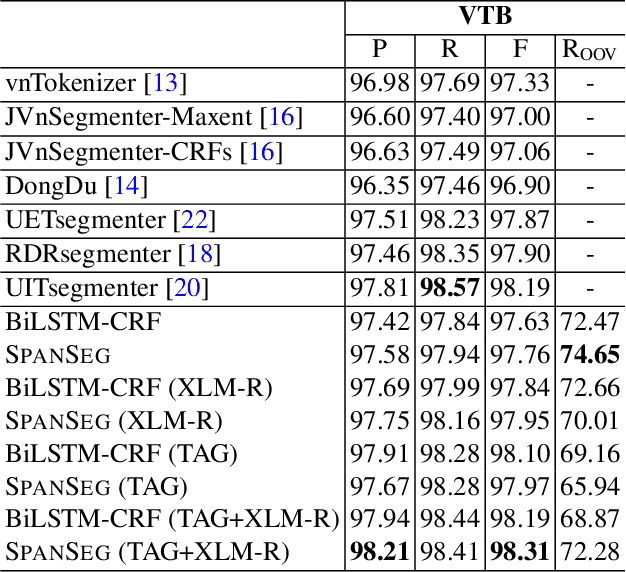
In this paper, we propose a span labeling approach to model n-gram information for Vietnamese word segmentation, namely SPAN SEG. We compare the span labeling approach with the conditional random field by using encoders with the same architecture. Since Vietnamese and Chinese have similar linguistic phenomena, we evaluated the proposed method on the Vietnamese treebank benchmark dataset and five Chinese benchmark datasets. Through our experimental results, the proposed approach SpanSeg achieves higher performance than the sequence tagging approach with the state-of-the-art F-score of 98.31% on the Vietnamese treebank benchmark, when they both apply the contextual pre-trained language model XLM-RoBERTa and the predicted word boundary information. Besides, we do fine-tuning experiments for the span labeling approach on BERT and ZEN pre-trained language model for Chinese with fewer parameters, faster inference time, and competitive or higher F-scores than the previous state-of-the-art approach, word segmentation with word-hood memory networks, on five Chinese benchmarks.