 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Recipe for Watermarking Diffusion Models
Mar 17, 2023



Recently, diffusion models (DMs) have demonstrated their advantageous potential for generative tasks. Widespread interest exists in incorporating DMs into downstream applications, such as producing or editing photorealistic images. However, practical deployment and unprecedented power of DMs raise legal issues, including copyright protection and monitoring of generated content. In this regard, watermarking has been a proven solution for copyright protection and content monitoring, but it is underexplored in the DMs literature. Specifically, DMs generate samples from longer tracks and may have newly designed multimodal structures, necessitating the modification of conventional watermarking pipelines. To this end, we conduct comprehensive analyses and derive a recipe for efficiently watermarking state-of-the-art DMs (e.g., Stable Diffusion), via training from scratch or finetuning. Our recipe is straightforward but involves empirically ablated implementation details, providing a solid foundation for future research on watermarking DMs. Our Code: https://github.com/yunqing-me/WatermarkDM.
Fair Generative Models via Transfer Learning
Dec 02, 2022



This work addresses fair generative models. Dataset biases have been a major cause of unfairness in deep generative models. Previous work had proposed to augment large, biased datasets with small, unbiased reference datasets. Under this setup, a weakly-supervised approach has been proposed, which achieves state-of-the-art quality and fairness in generated samples. In our work, based on this setup, we propose a simple yet effective approach. Specifically, first, we propose fairTL, a transfer learning approach to learn fair generative models. Under fairTL, we pre-train the generative model with the available large, biased datasets and subsequently adapt the model using the small, unbiased reference dataset. We find that our fairTL can learn expressive sample generation during pre-training, thanks to the large (biased) dataset. This knowledge is then transferred to the target model during adaptation, which also learns to capture the underlying fair distribution of the small reference dataset. Second, we propose fairTL++, where we introduce two additional innovations to improve upon fairTL: (i) multiple feedback and (ii) Linear-Probing followed by Fine-Tuning (LP-FT). Taking one step further, we consider an alternative, challenging setup when only a pre-trained (potentially biased) model is available but the dataset that was used to pre-train the model is inaccessible. We demonstrate that our proposed fairTL and fairTL++ remain very effective under this setup. We note that previous work requires access to the large, biased datasets and is incapable of handling this more challenging setup. Extensive experiments show that fairTL and fairTL++ achieve state-of-the-art in both quality and fairness of generated samples. The code and additional resources can be found at bearwithchris.github.io/fairTL/.
Few-shot Image Generation via Adaptation-Aware Kernel Modulation
Nov 13, 2022Few-shot image generation (FSIG) aims to learn to generate new and diverse samples given an extremely limited number of samples from a domain, e.g., 10 training samples. Recent work has addressed the problem using transfer learning approach, leveraging a GAN pretrained on a large-scale source domain dataset and adapting that model to the target domain based on very limited target domain samples. Central to recent FSIG methods are knowledge preserving criteria, which aim to select a subset of source model's knowledge to be preserved into the adapted model. However, a major limitation of existing methods is that their knowledge preserving criteria consider only source domain/source task, and they fail to consider target domain/adaptation task in selecting source model's knowledge, casting doubt on their suitability for setups of different proximity between source and target domain. Our work makes two contributions. As our first contribution, we re-visit recent FSIG works and their experiments. Our important finding is that, under setups which assumption of close proximity between source and target domains is relaxed, existing state-of-the-art (SOTA) methods which consider only source domain/source task in knowledge preserving perform no better than a baseline fine-tuning method. To address the limitation of existing methods, as our second contribution, we propose Adaptation-Aware kernel Modulation (AdAM) to address general FSIG of different source-target domain proximity. Extensive experimental results show that the proposed method consistently achieves SOTA performance across source/target domains of different proximity, including challenging setups when source and target domains are more apart. Project Page: https://yunqing-me.github.io/AdAM/
Discovering Transferable Forensic Features for CNN-generated Images Detection
Aug 24, 2022
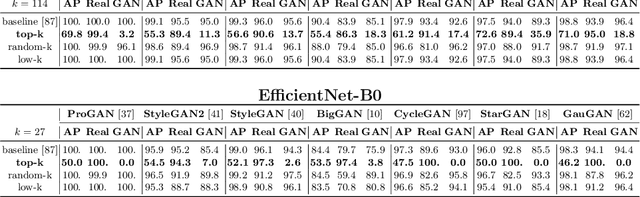


Visual counterfeits are increasingly causing an existential conundrum in mainstream media with rapid evolution in neural image synthesis methods. Though detection of such counterfeits has been a taxing problem in the image forensics community, a recent class of forensic detectors -- universal detectors -- are able to surprisingly spot counterfeit images regardless of generator architectures, loss functions, training datasets, and resolutions. This intriguing property suggests the possible existence of transferable forensic features (T-FF) in universal detectors. In this work, we conduct the first analytical study to discover and understand T-FF in universal detectors. Our contributions are 2-fold: 1) We propose a novel forensic feature relevance statistic (FF-RS) to quantify and discover T-FF in universal detectors and, 2) Our qualitative and quantitative investigations uncover an unexpected finding: color is a critical T-FF in universal detectors. Code and models are available at https://keshik6.github.io/transferable-forensic-features/
FS-BAN: Born-Again Networks for Domain Generalization Few-Shot Classification
Aug 24, 2022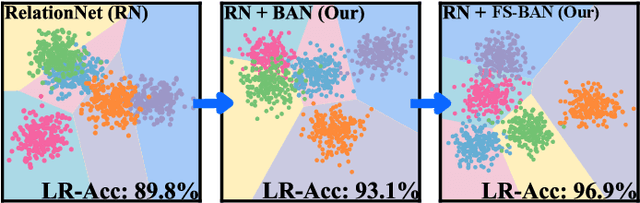
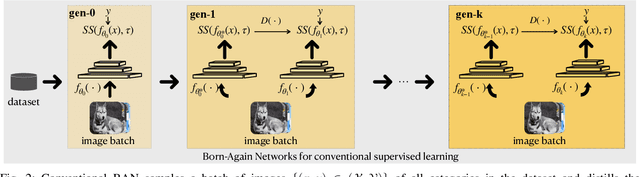
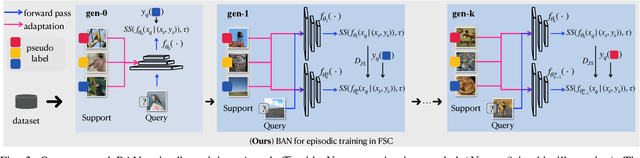
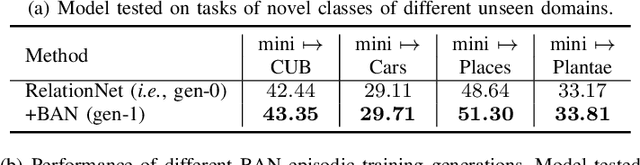
Conventional Few-shot classification (FSC) aims to recognize samples from novel classes given limited labeled data. Recently, domain generalization FSC (DG-FSC) has been proposed with the goal to recognize novel class samples from unseen domains. DG-FSC poses considerable challenges to many models due to the domain shift between base classes (used in training) and novel classes (encountered in evaluation). In this work, we make two novel contributions to tackle DG-FSC. Our first contribution is to propose Born-Again Network (BAN) episodic training and comprehensively investigate its effectiveness for DG-FSC. As a specific form of knowledge distillation, BAN has been shown to achieve improved generalization in conventional supervised classification with a closed-set setup. This improved generalization motivates us to study BAN for DG-FSC, and we show that BAN is promising to address the domain shift encountered in DG-FSC. Building on the encouraging finding, our second (major) contribution is to propose few-shot BAN, FS-BAN, a novel BAN approach for DG-FSC. Our proposed FS-BAN includes novel multi-task learning objectives: Mutual Regularization, Mismatched Teacher and Meta-Control Temperature, each of these is specifically designed to overcome central and unique challenges in DG-FSC, namely overfitting and domain discrepancy. We analyze different design choices of these techniques. We conduct comprehensive quantitative and qualitative analysis and evaluation using six datasets and three baseline models. The results suggest that our proposed FS-BAN consistently improves the generalization performance of baseline models and achieves state-of-the-art accuracy for DG-FSC.
Neural Correlates of Face Familiarity Perception
Jul 31, 2022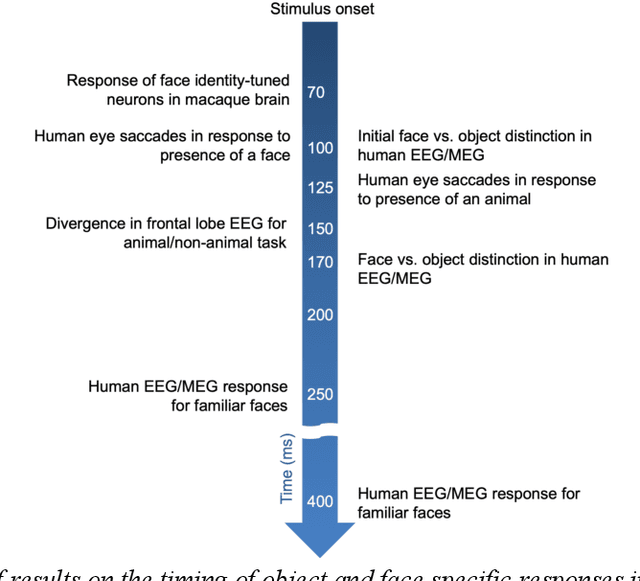
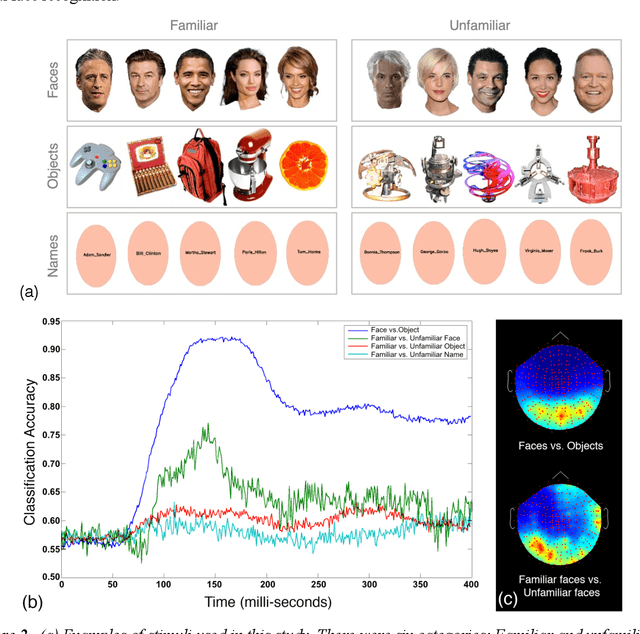
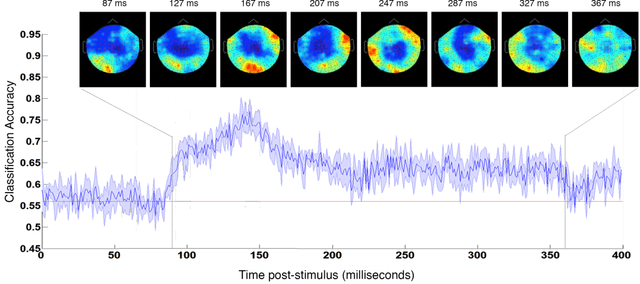
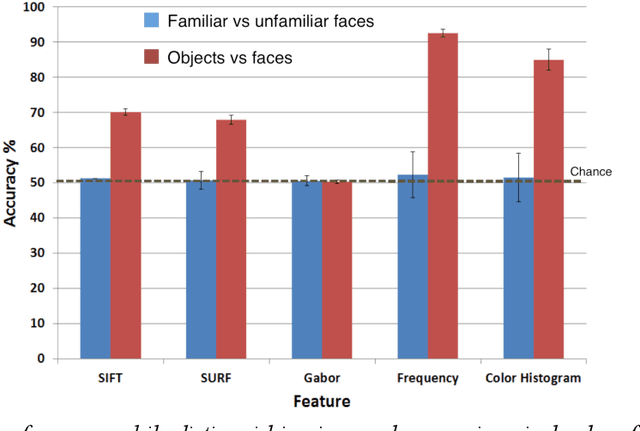
In the domain of face recognition, there exists a puzzling timing discrepancy between results from macaque neurophysiology on the one hand and human electrophysiology on the other. Single unit recordings in macaques have demonstrated face identity specific responses in extra-striate visual cortex within 100 milliseconds of stimulus onset. In EEG and MEG experiments with humans, however, a consistent distinction between neural activity corresponding to unfamiliar and familiar faces has been reported to emerge around 250 ms. This points to the possibility that there may be a hitherto undiscovered early correlate of face familiarity perception in human electrophysiological traces. We report here a successful search for such a correlate in dense MEG recordings using pattern classification techniques. Our analyses reveal markers of face familiarity as early as 85 ms after stimulus onset. Low-level attributes of the images, such as luminance and color distributions, are unable to account for this early emerging response difference. These results help reconcile human and macaque data, and provide clues regarding neural mechanisms underlying familiar face perception.
Revisiting Label Smoothing and Knowledge Distillation Compatibility: What was Missing?
Jun 29, 2022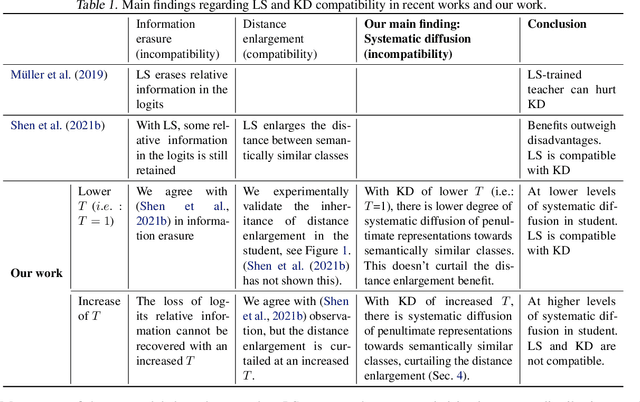
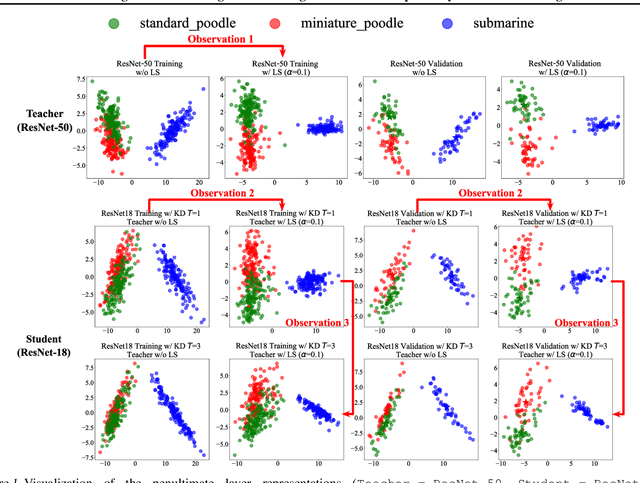
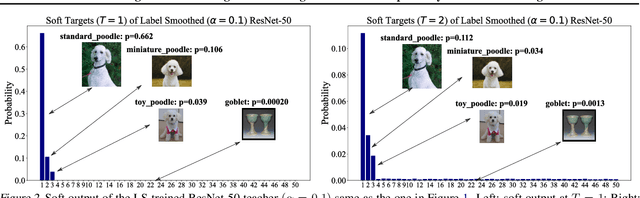
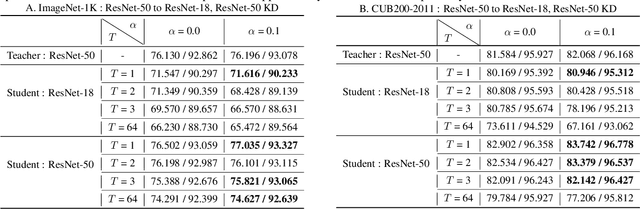
This work investigates the compatibility between label smoothing (LS) and knowledge distillation (KD). Contemporary findings addressing this thesis statement take dichotomous standpoints: Muller et al. (2019) and Shen et al. (2021b). Critically, there is no effort to understand and resolve these contradictory findings, leaving the primal question -- to smooth or not to smooth a teacher network? -- unanswered. The main contributions of our work are the discovery, analysis and validation of systematic diffusion as the missing concept which is instrumental in understanding and resolving these contradictory findings. This systematic diffusion essentially curtails the benefits of distilling from an LS-trained teacher, thereby rendering KD at increased temperatures ineffective. Our discovery is comprehensively supported by large-scale experiments, analyses and case studies including image classification, neural machine translation and compact student distillation tasks spanning across multiple datasets and teacher-student architectures. Based on our analysis, we suggest practitioners to use an LS-trained teacher with a low-temperature transfer to achieve high performance students. Code and models are available at https://keshik6.github.io/revisiting-ls-kd-compatibility/
A Closer Look at Few-shot Image Generation
May 08, 2022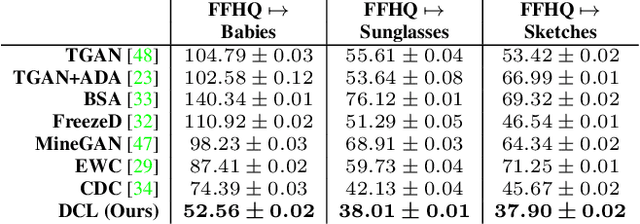
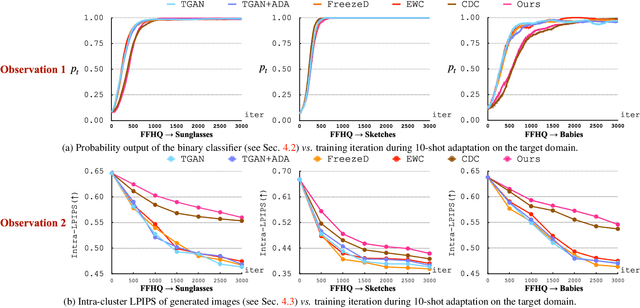
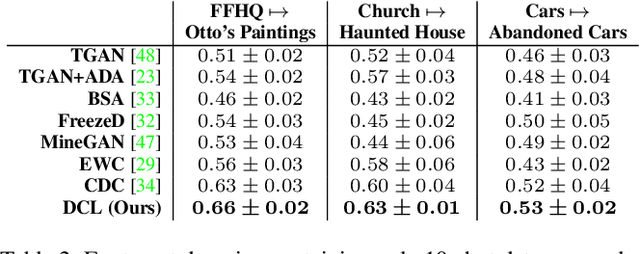
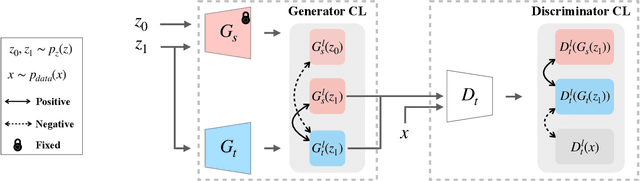
Modern GANs excel at generating high quality and diverse images. However, when transferring the pretrained GANs on small target data (e.g., 10-shot), the generator tends to replicate the training samples. Several methods have been proposed to address this few-shot image generation task, but there is a lack of effort to analyze them under a unified framework. As our first contribution, we propose a framework to analyze existing methods during the adaptation. Our analysis discovers that while some methods have disproportionate focus on diversity preserving which impede quality improvement, all methods achieve similar quality after convergence. Therefore, the better methods are those that can slow down diversity degradation. Furthermore, our analysis reveals that there is still plenty of room to further slow down diversity degradation. Informed by our analysis and to slow down the diversity degradation of the target generator during adaptation, our second contribution proposes to apply mutual information (MI) maximization to retain the source domain's rich multi-level diversity information in the target domain generator. We propose to perform MI maximization by contrastive loss (CL), leverage the generator and discriminator as two feature encoders to extract different multi-level features for computing CL. We refer to our method as Dual Contrastive Learning (DCL). Extensive experiments on several public datasets show that, while leading to a slower diversity-degrading generator during adaptation, our proposed DCL brings visually pleasant quality and state-of-the-art quantitative performance.
Graph-wise Common Latent Factor Extraction for Unsupervised Graph Representation Learning
Dec 16, 2021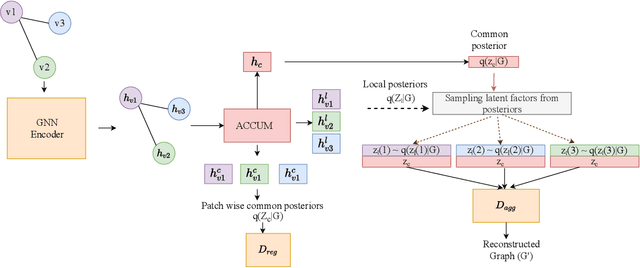
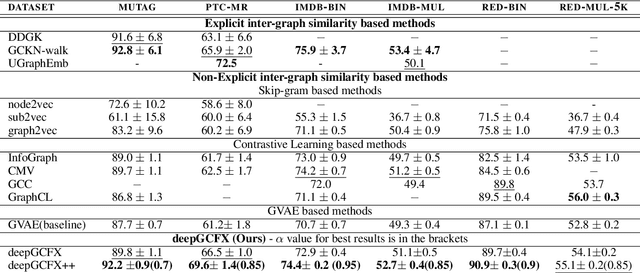
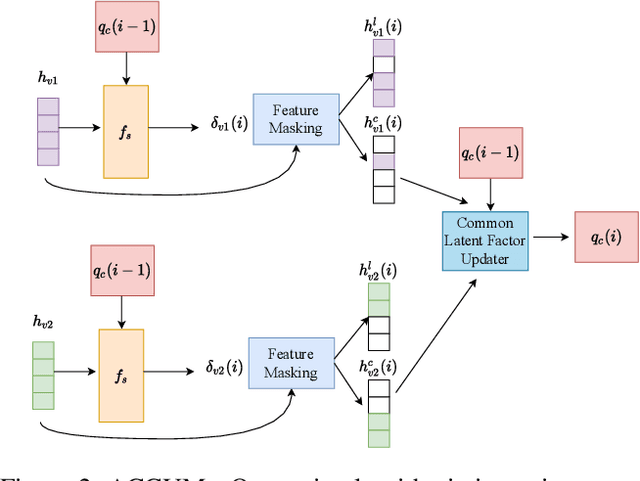
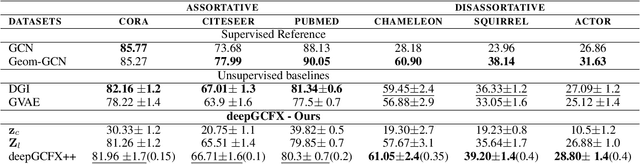
Unsupervised graph-level representation learning plays a crucial role in a variety of tasks such as molecular property prediction and community analysis, especially when data annotation is expensive. Currently, most of the best-performing graph embedding methods are based on Infomax principle. The performance of these methods highly depends on the selection of negative samples and hurt the performance, if the samples were not carefully selected. Inter-graph similarity-based methods also suffer if the selected set of graphs for similarity matching is low in quality. To address this, we focus only on utilizing the current input graph for embedding learning. We are motivated by an observation from real-world graph generation processes where the graphs are formed based on one or more global factors which are common to all elements of the graph (e.g., topic of a discussion thread, solubility level of a molecule). We hypothesize extracting these common factors could be highly beneficial. Hence, this work proposes a new principle for unsupervised graph representation learning: Graph-wise Common latent Factor EXtraction (GCFX). We further propose a deep model for GCFX, deepGCFX, based on the idea of reversing the above-mentioned graph generation process which could explicitly extract common latent factors from an input graph and achieve improved results on downstream tasks to the current state-of-the-art. Through extensive experiments and analysis, we demonstrate that, while extracting common latent factors is beneficial for graph-level tasks to alleviate distractions caused by local variations of individual nodes or local neighbourhoods, it also benefits node-level tasks by enabling long-range node dependencies, especially for disassortative graphs.
Multi-Modal Mutual Information Maximization: A Novel Approach for Unsupervised Deep Cross-Modal Hashing
Dec 13, 2021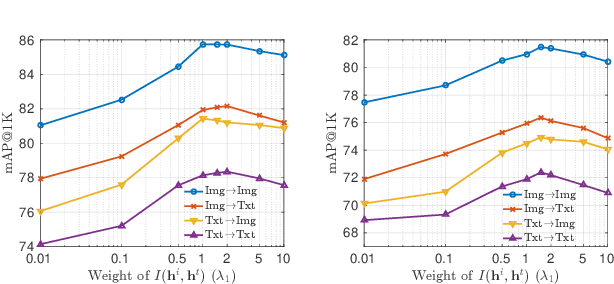
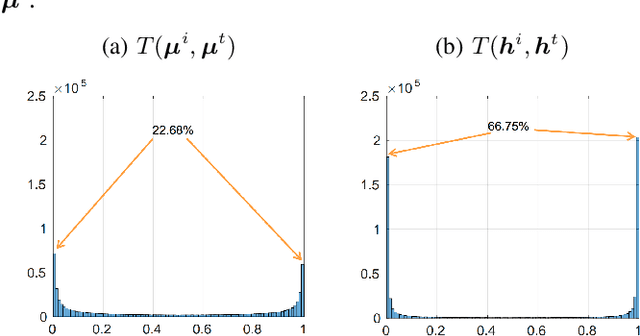
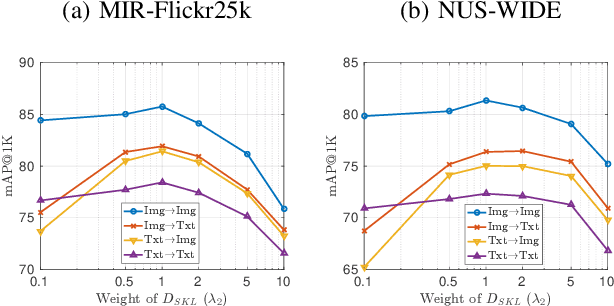
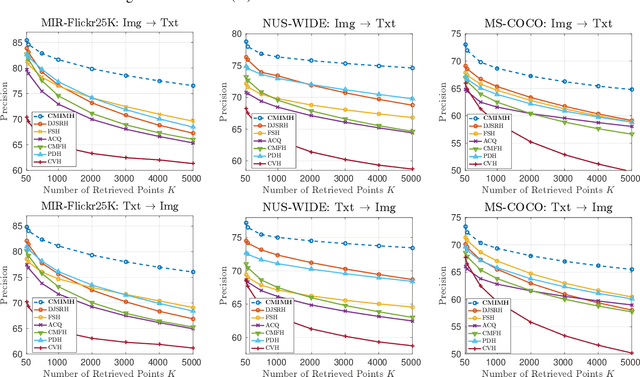
In this paper, we adopt the maximizing mutual information (MI) approach to tackle the problem of unsupervised learning of binary hash codes for efficient cross-modal retrieval. We proposed a novel method, dubbed Cross-Modal Info-Max Hashing (CMIMH). First, to learn informative representations that can preserve both intra- and inter-modal similarities, we leverage the recent advances in estimating variational lower-bound of MI to maximize the MI between the binary representations and input features and between binary representations of different modalities. By jointly maximizing these MIs under the assumption that the binary representations are modelled by multivariate Bernoulli distributions, we can learn binary representations, which can preserve both intra- and inter-modal similarities, effectively in a mini-batch manner with gradient descent. Furthermore, we find out that trying to minimize the modality gap by learning similar binary representations for the same instance from different modalities could result in less informative representations. Hence, balancing between reducing the modality gap and losing modality-private information is important for the cross-modal retrieval tasks. Quantitative evaluations on standard benchmark datasets demonstrate that the proposed method consistently outperforms other state-of-the-art cross-modal retrieval methods.