 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoose Wisely and Privately: Proactive Client Selection for Fair and Efficient Federated Learning
May 21, 2026Federated Learning enables collaborative model training across decentralized data sources without data transfer. Averaging-based FL is limited by the presence of non-IID data, which negatively impacts convergence speed and final model accuracy. Conventional alternatives suffer from significant inefficiency. Clients with noisy or highly heterogeneous data contribute expensive gradient computations that are either discarded or heavily down-weighted before aggregation. These reactive approaches waste computational resources, require more communication rounds and result in unnecessary privacy exposure. In this paper, we propose a proactive client selection framework that aims to find an optimal federation of clients whose combined data match utility and fairness requirements before training begins. Our method relies on mutual information computed from differentially private contingency tables to quantify the relevance of cross-feature correlations in the union dataset. We introduce a Potential Federation Loss (PFL) over the set of fixed-size federations, which balances two objectives. Maximizing collective data utility while ensuring fair cross-features correlations to prevent group unfairness. Client selection is expressed as an optimal subset search problem over the PFL objective, which we solve using simulated annealing under strong differential privacy guarantees for clients' local statistics. Experimental results on four benchmarks show faster, fairer, and more accurate models trained on optimally found federations, compared to uniform sampling, even when state-of-the-art adaptive aggregation or sampling strategies are employed.
Robust Federated Learning via Byzantine Filtering over Encrypted Updates
Feb 05, 2026Federated Learning (FL) aims to train a collaborative model while preserving data privacy. However, the distributed nature of this approach still raises privacy and security issues, such as the exposure of sensitive data due to inference attacks and the influence of Byzantine behaviors on the trained model. In particular, achieving both secure aggregation and Byzantine resilience remains challenging, as existing solutions often address these aspects independently. In this work, we propose to address these challenges through a novel approach that combines homomorphic encryption for privacy-preserving aggregation with property-inference-inspired meta-classifiers for Byzantine filtering. First, following the property-inference attacks blueprint, we train a set of filtering meta-classifiers on labeled shadow updates, reproducing a diverse ensemble of Byzantine misbehaviors in FL, including backdoor, gradient-inversion, label-flipping and shuffling attacks. The outputs of these meta-classifiers are then used to cancel the Byzantine encrypted updates by reweighting. Second, we propose an automated method for selecting the optimal kernel and the dimensionality hyperparameters with respect to homomorphic inference, aggregation constraints and efficiency over the CKKS cryptosystem. Finally, we demonstrate through extensive experiments the effectiveness of our approach against Byzantine participants on the FEMNIST, CIFAR10, GTSRB, and acsincome benchmarks. More precisely, our SVM filtering achieves accuracies between $90$% and $94$% for identifying Byzantine updates at the cost of marginal losses in model utility and encrypted inference runtimes ranging from $6$ to $24$ seconds and from $9$ to $26$ seconds for an overall aggregation.
Fair Play for Individuals, Foul Play for Groups? Auditing Anonymization's Impact on ML Fairness
May 12, 2025Machine learning (ML) algorithms are heavily based on the availability of training data, which, depending on the domain, often includes sensitive information about data providers. This raises critical privacy concerns. Anonymization techniques have emerged as a practical solution to address these issues by generalizing features or suppressing data to make it more difficult to accurately identify individuals. Although recent studies have shown that privacy-enhancing technologies can influence ML predictions across different subgroups, thus affecting fair decision-making, the specific effects of anonymization techniques, such as $k$-anonymity, $\ell$-diversity, and $t$-closeness, on ML fairness remain largely unexplored. In this work, we systematically audit the impact of anonymization techniques on ML fairness, evaluating both individual and group fairness. Our quantitative study reveals that anonymization can degrade group fairness metrics by up to four orders of magnitude. Conversely, similarity-based individual fairness metrics tend to improve under stronger anonymization, largely as a result of increased input homogeneity. By analyzing varying levels of anonymization across diverse privacy settings and data distributions, this study provides critical insights into the trade-offs between privacy, fairness, and utility, offering actionable guidelines for responsible AI development. Our code is publicly available at: https://github.com/hharcolezi/anonymity-impact-fairness.
Label-GCN: An Effective Method for Adding Label Propagation to Graph Convolutional Networks
Apr 05, 2021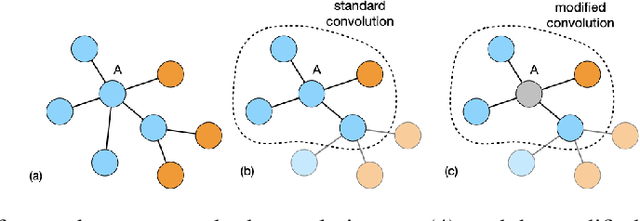

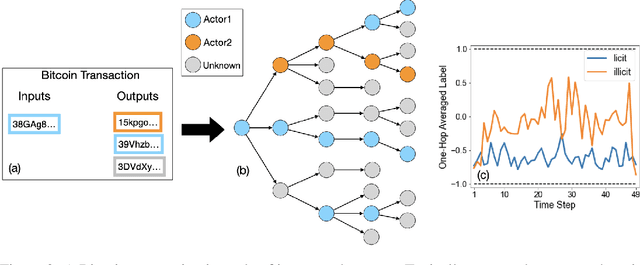
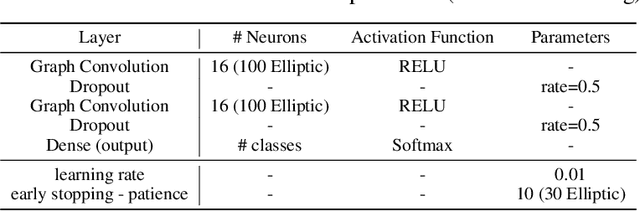
We show that a modification of the first layer of a Graph Convolutional Network (GCN) can be used to effectively propagate label information across neighbor nodes, for binary and multi-class classification problems. This is done by selectively eliminating self-loops for the label features during the training phase of a GCN. The GCN architecture is otherwise unchanged, without any extra hyper-parameters, and can be used in both a transductive and inductive setting. We show through several experiments that, depending on how many labels are available during the inference phase, this strategy can lead to a substantial improvement in the model performance compared to a standard GCN approach, including with imbalanced datasets.