 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
AI-Assisted Fixes to Code Review Comments at Scale
Jul 17, 2025Aim. There are 10s of thousands of code review comments each week at Meta. We developed Metamate for Code Review (MetaMateCR) that provides AI-assisted fixes for reviewer comments in production at scale. Method. We developed an internal benchmark of 64k <review comment, patch> data points to fine-tune Llama models. Once our models achieve reasonable offline results, we roll them into production. To ensure that our AI-assisted fixes do not negatively impact the time it takes to do code reviews, we conduct randomized controlled safety trials as well as full production experiments. Offline Results. As a baseline, we compare GPT-4o to our small and large Llama models. In offline results, our LargeLSFT model creates an exact match patch 68% of the time outperforming GPT-4o by 9 percentage points (pp). The internal models also use more modern Hack functions when compared to the PHP functions suggested by GPT-4o. Safety Trial. When we roll MetaMateCR into production in a safety trial that compares no AI patches with AI patch suggestions, we see a large regression with reviewers taking over 5% longer to conduct reviews. After investigation, we modify the UX to only show authors the AI patches, and see no regressions in the time for reviews. Production. When we roll LargeLSFT into production, we see an ActionableToApplied rate of 19.7%, which is a 9.2pp improvement over GPT-4o. Our results illustrate the importance of safety trials in ensuring that AI does not inadvertently slow down engineers, and a successful review comment to AI patch product running at scale.
CodeCompose: A Large-Scale Industrial Deployment of AI-assisted Code Authoring
May 20, 2023



The rise of large language models (LLMs) has unlocked various applications of this technology in software development. In particular, generative LLMs have been shown to effectively power AI-based code authoring tools that can suggest entire statements or blocks of code during code authoring. In this paper we present CodeCompose, an AI-assisted code authoring tool developed and deployed at Meta internally. CodeCompose is based on the InCoder LLM that merges generative capabilities with bi-directionality. We have scaled up CodeCompose to serve tens of thousands of developers at Meta, across 10+ programming languages and several coding surfaces. We discuss unique challenges in terms of user experience and metrics that arise when deploying such tools in large-scale industrial settings. We present our experience in making design decisions about the model and system architecture for CodeCompose that addresses these challenges. Finally, we present metrics from our large-scale deployment of CodeCompose that shows its impact on Meta's internal code authoring experience over a 15-day time window, where 4.5 million suggestions were made by CodeCompose. Quantitative metrics reveal that (i) CodeCompose has an acceptance rate of 22% across several languages, and (ii) 8% of the code typed by users of CodeCompose is through accepting code suggestions from CodeCompose. Qualitative feedback indicates an overwhelming 91.5% positive reception for CodeCompose. In addition to assisting with code authoring, CodeCompose is also introducing other positive side effects such as encouraging developers to generate more in-code documentation, helping them with the discovery of new APIs, etc.
MergeBERT: Program Merge Conflict Resolution via Neural Transformers
Sep 08, 2021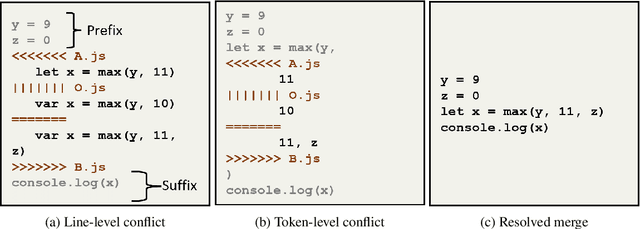
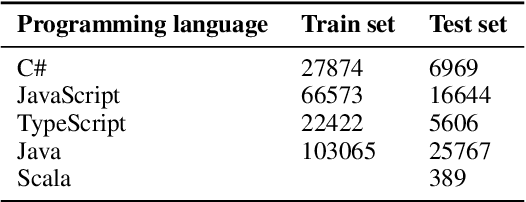

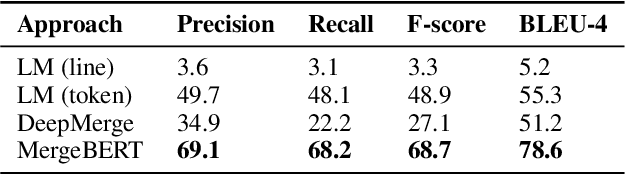
Collaborative software development is an integral part of the modern software development life cycle, essential to the success of large-scale software projects. When multiple developers make concurrent changes around the same lines of code, a merge conflict may occur. Such conflicts stall pull requests and continuous integration pipelines for hours to several days, seriously hurting developer productivity. In this paper, we introduce MergeBERT, a novel neural program merge framework based on the token-level three-way differencing and a transformer encoder model. Exploiting restricted nature of merge conflict resolutions, we reformulate the task of generating the resolution sequence as a classification task over a set of primitive merge patterns extracted from real-world merge commit data. Our model achieves 64--69% precision of merge resolution synthesis, yielding nearly a 2x performance improvement over existing structured and neural program merge tools. Finally, we demonstrate versatility of our model, which is able to perform program merge in a multilingual setting with Java, JavaScript, TypeScript, and C# programming languages, generalizing zero-shot to unseen languages.