 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing of Quantitative Values in Abstractive Summarization Models
Oct 03, 2022
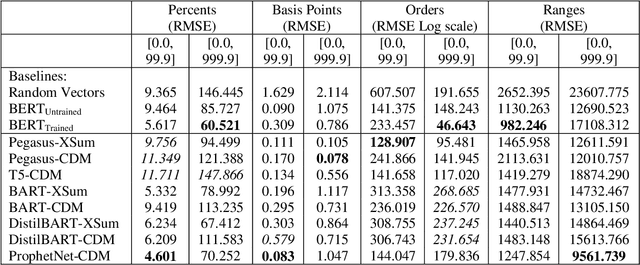
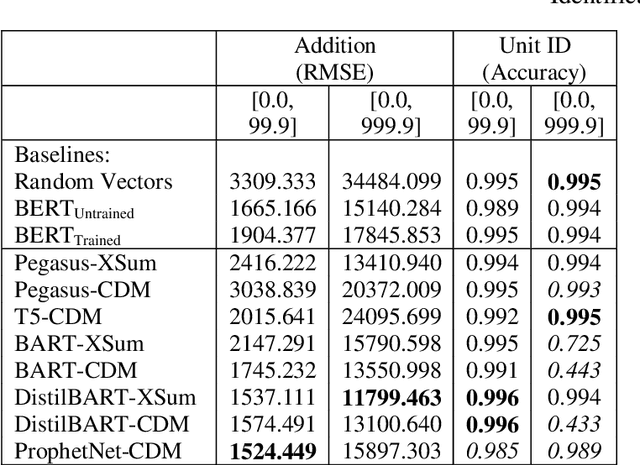
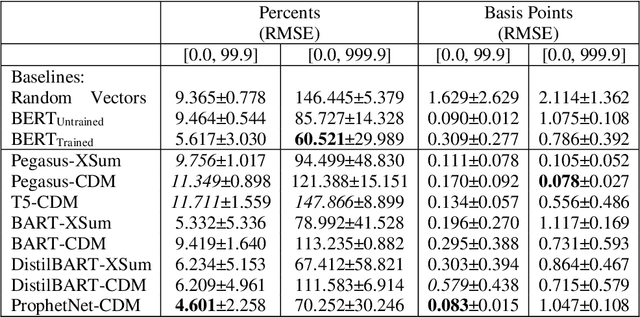
Abstractive text summarization has recently become a popular approach, but data hallucination remains a serious problem, including with quantitative data. We propose a set of probing tests to evaluate the efficacy of abstract summarization models' modeling of quantitative values found in the input text. Our results show that in most cases, the encoders of recent SOTA-performing models struggle to provide embeddings that adequately represent quantitative values in the input compared to baselines, and in particular, they outperform random representations in some, but surprisingly not all, cases. Under our assumptions, this suggests that the encoder's performance contributes to the quantity hallucination problem. One model type in particular, DistilBART-CDM, was observed to underperform randomly initialized representations for several experiments, and performance versus BERT suggests that standard pretraining and fine-tuning approaches for the summarization task may play a role in underperformance for some encoders.
The Harrington Yowlumne Narrative Corpus
Feb 01, 2021
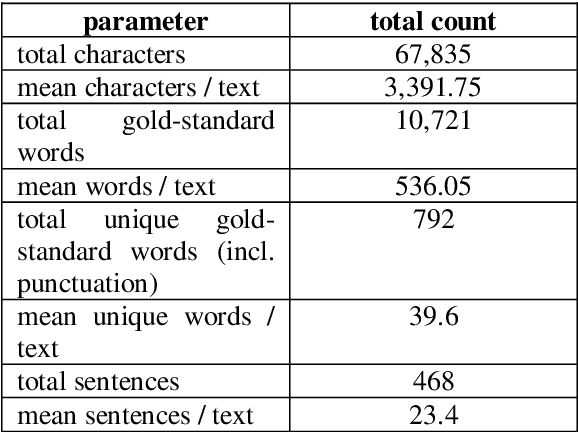
Minority languages continue to lack adequate resources for their development, especially in the technological domain. Likewise, the J.P. Harrington Papers collection at the Smithsonian Institution are difficult to access in practical terms for community members and researchers due to its handwritten and disorganized format. Our current work seeks to make a portion of this publicly-available yet problematic material practically accessible for natural language processing use. Here, we present the Harrington Yowlumne Narrative Corpus, a corpus of 20 narrative texts that derive from the Tejone\~no Yowlumne community of the Tinliw rancheria in Kern County, California between 1910 and 1925. We digitally transcribe the texts and provide gold-standard aligned lexeme-based normalized text with these texts. Altogether, the text contains 67,835 transcribed characters aligned with 10,721 gold standard text-normalized words.