 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Transductive Transfer Learning for Automatic Target Recognition
May 23, 2023One of the major obstacles in designing an automatic target recognition (ATR) algorithm, is that there are often labeled images in one domain (i.e., infrared source domain) but no annotated images in the other target domains (i.e., visible, SAR, LIDAR). Therefore, automatically annotating these images is essential to build a robust classifier in the target domain based on the labeled images of the source domain. Transductive transfer learning is an effective way to adapt a network to a new target domain by utilizing a pretrained ATR network in the source domain. We propose an unpaired transductive transfer learning framework where a CycleGAN model and a well-trained ATR classifier in the source domain are used to construct an ATR classifier in the target domain without having any labeled data in the target domain. We employ a CycleGAN model to transfer the mid-wave infrared (MWIR) images to visible (VIS) domain images (or visible to MWIR domain). To train the transductive CycleGAN, we optimize a cost function consisting of the adversarial, identity, cycle-consistency, and categorical cross-entropy loss for both the source and target classifiers. In this paper, we perform a detailed experimental analysis on the challenging DSIAC ATR dataset. The dataset consists of ten classes of vehicles at different poses and distances ranging from 1-5 kilometers on both the MWIR and VIS domains. In our experiment, we assume that the images in the VIS domain are the unlabeled target dataset. We first detect and crop the vehicles from the raw images and then project them into a common distance of 2 kilometers. Our proposed transductive CycleGAN achieves 71.56% accuracy in classifying the visible domain vehicles in the DSIAC ATR dataset.
* 10 pages, 5 figures
Landmark Enforcement and Style Manipulation for Generative Morphing
Oct 18, 2022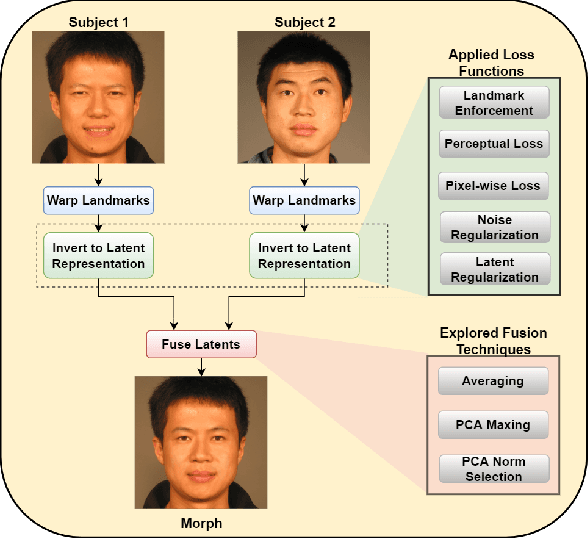
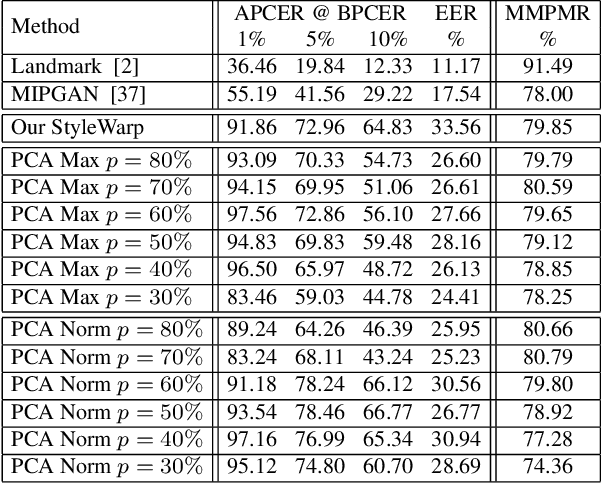

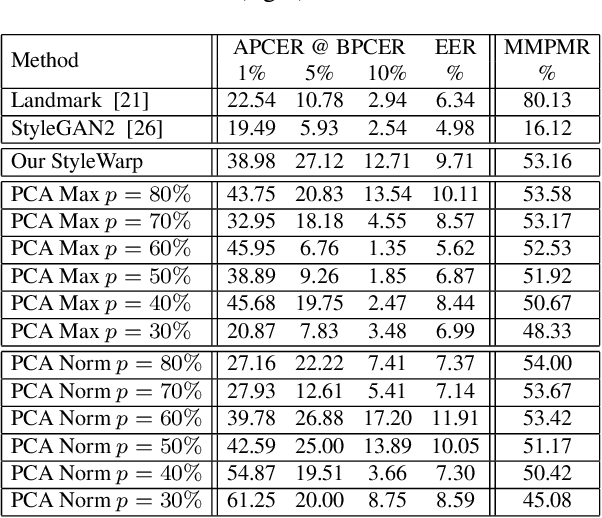
Morph images threaten Facial Recognition Systems (FRS) by presenting as multiple individuals, allowing an adversary to swap identities with another subject. Morph generation using generative adversarial networks (GANs) results in high-quality morphs unaffected by the spatial artifacts caused by landmark-based methods, but there is an apparent loss in identity with standard GAN-based morphing methods. In this paper, we propose a novel StyleGAN morph generation technique by introducing a landmark enforcement method to resolve this issue. Considering this method, we aim to enforce the landmarks of the morph image to represent the spatial average of the landmarks of the bona fide faces and subsequently the morph images to inherit the geometric identity of both bona fide faces. Exploration of the latent space of our model is conducted using Principal Component Analysis (PCA) to accentuate the effect of both the bona fide faces on the morphed latent representation and address the identity loss issue with latent domain averaging. Additionally, to improve high frequency reconstruction in the morphs, we study the train-ability of the noise input for the StyleGAN2 model.
Attention-Based Generative Neural Image Compression on Solar Dynamics Observatory
Oct 12, 2022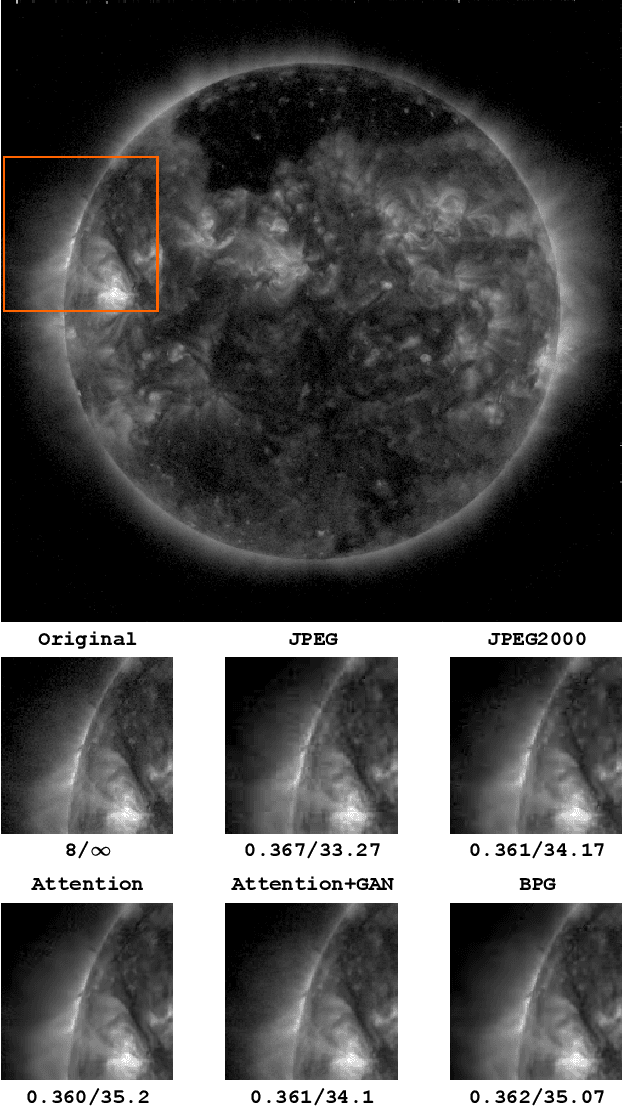
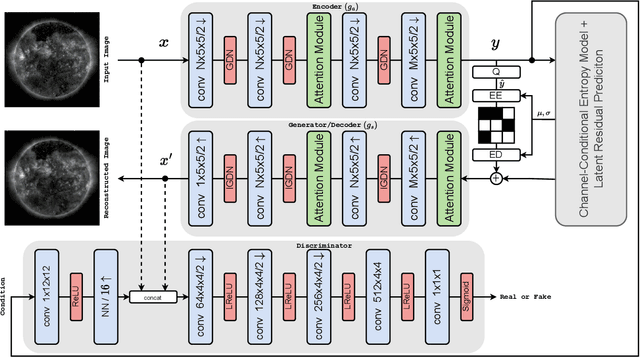
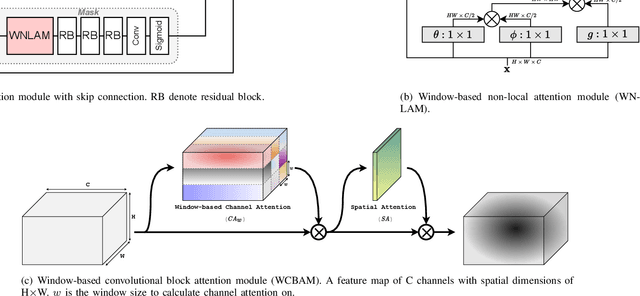
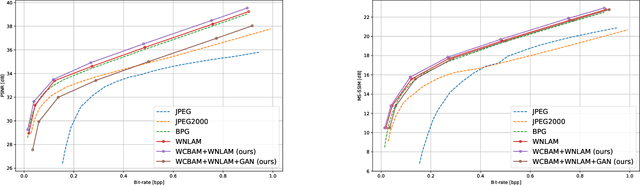
NASA's Solar Dynamics Observatory (SDO) mission gathers 1.4 terabytes of data each day from its geosynchronous orbit in space. SDO data includes images of the Sun captured at different wavelengths, with the primary scientific goal of understanding the dynamic processes governing the Sun. Recently, end-to-end optimized artificial neural networks (ANN) have shown great potential in performing image compression. ANN-based compression schemes have outperformed conventional hand-engineered algorithms for lossy and lossless image compression. We have designed an ad-hoc ANN-based image compression scheme to reduce the amount of data needed to be stored and retrieved on space missions studying solar dynamics. In this work, we propose an attention module to make use of both local and non-local attention mechanisms in an adversarially trained neural image compression network. We have also demonstrated the superior perceptual quality of this neural image compressor. Our proposed algorithm for compressing images downloaded from the SDO spacecraft performs better in rate-distortion trade-off than the popular currently-in-use image compression codecs such as JPEG and JPEG2000. In addition we have shown that the proposed method outperforms state-of-the art lossy transform coding compression codec, i.e., BPG.
Robust Ensemble Morph Detection with Domain Generalization
Sep 16, 2022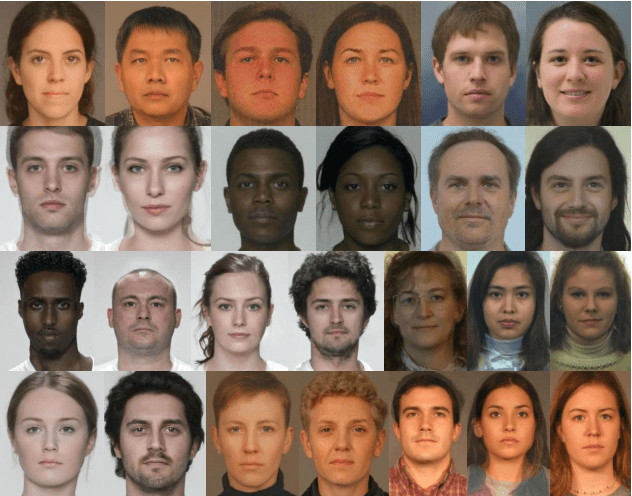
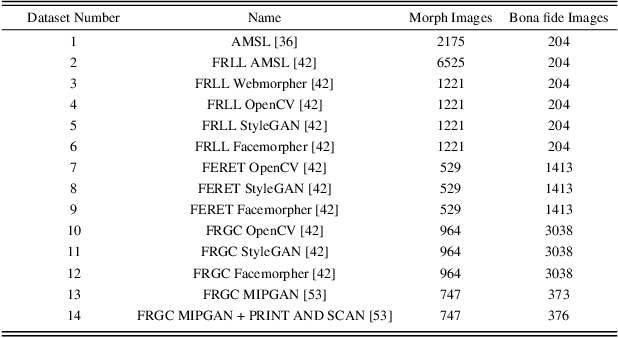
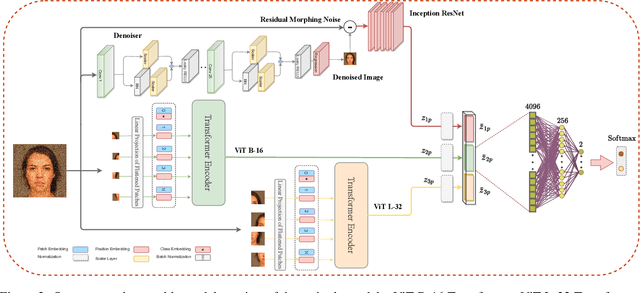
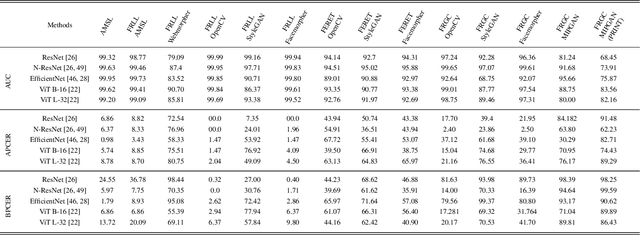
Although a substantial amount of studies is dedicated to morph detection, most of them fail to generalize for morph faces outside of their training paradigm. Moreover, recent morph detection methods are highly vulnerable to adversarial attacks. In this paper, we intend to learn a morph detection model with high generalization to a wide range of morphing attacks and high robustness against different adversarial attacks. To this aim, we develop an ensemble of convolutional neural networks (CNNs) and Transformer models to benefit from their capabilities simultaneously. To improve the robust accuracy of the ensemble model, we employ multi-perturbation adversarial training and generate adversarial examples with high transferability for several single models. Our exhaustive evaluations demonstrate that the proposed robust ensemble model generalizes to several morphing attacks and face datasets. In addition, we validate that our robust ensemble model gain better robustness against several adversarial attacks while outperforming the state-of-the-art studies.
Pose Attention-Guided Profile-to-Frontal Face Recognition
Sep 15, 2022
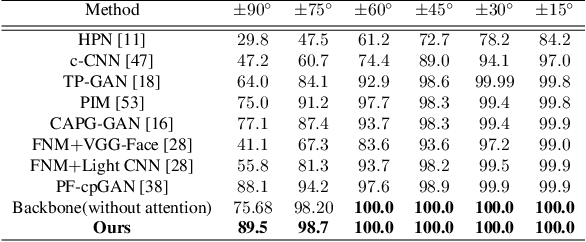
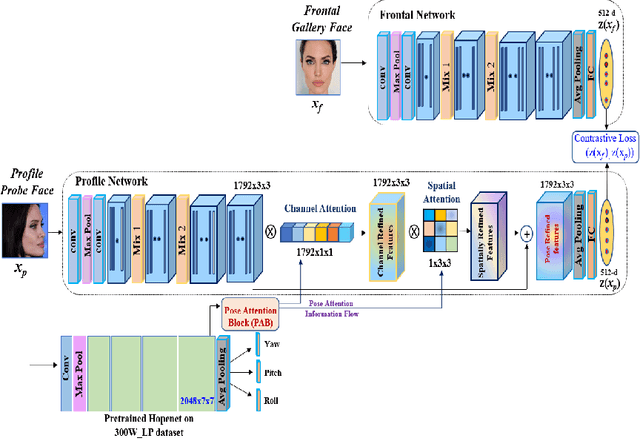
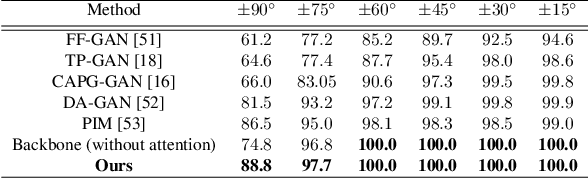
In recent years, face recognition systems have achieved exceptional success due to promising advances in deep learning architectures. However, they still fail to achieve expected accuracy when matching profile images against a gallery of frontal images. Current approaches either perform pose normalization (i.e., frontalization) or disentangle pose information for face recognition. We instead propose a new approach to utilize pose as an auxiliary information via an attention mechanism. In this paper, we hypothesize that pose attended information using an attention mechanism can guide contextual and distinctive feature extraction from profile faces, which further benefits a better representation learning in an embedded domain. To achieve this, first, we design a unified coupled profile-to-frontal face recognition network. It learns the mapping from faces to a compact embedding subspace via a class-specific contrastive loss. Second, we develop a novel pose attention block (PAB) to specially guide the pose-agnostic feature extraction from profile faces. To be more specific, PAB is designed to explicitly help the network to focus on important features along both channel and spatial dimension while learning discriminative yet pose invariant features in an embedding subspace. To validate the effectiveness of our proposed method, we conduct experiments on both controlled and in the wild benchmarks including Multi-PIE, CFP, IJBC, and show superiority over the state of the arts.
Information Maximization for Extreme Pose Face Recognition
Sep 07, 2022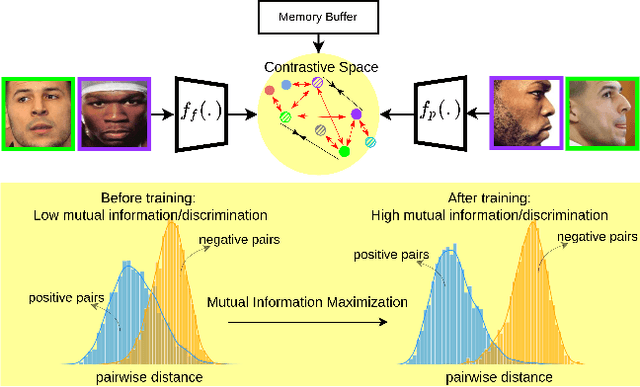
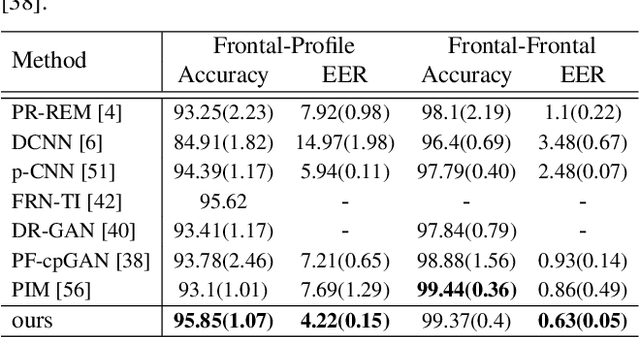
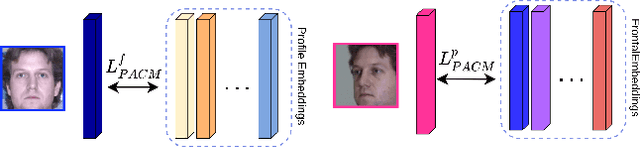
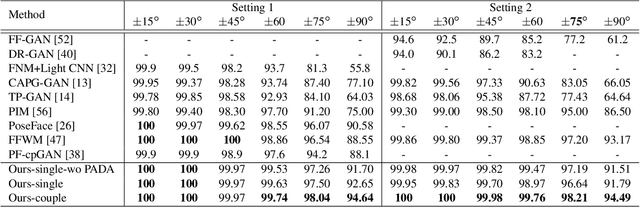
In this paper, we seek to draw connections between the frontal and profile face images in an abstract embedding space. We exploit this connection using a coupled-encoder network to project frontal/profile face images into a common latent embedding space. The proposed model forces the similarity of representations in the embedding space by maximizing the mutual information between two views of the face. The proposed coupled-encoder benefits from three contributions for matching faces with extreme pose disparities. First, we leverage our pose-aware contrastive learning to maximize the mutual information between frontal and profile representations of identities. Second, a memory buffer, which consists of latent representations accumulated over past iterations, is integrated into the model so it can refer to relatively much more instances than the mini-batch size. Third, a novel pose-aware adversarial domain adaptation method forces the model to learn an asymmetric mapping from profile to frontal representation. In our framework, the coupled-encoder learns to enlarge the margin between the distribution of genuine and imposter faces, which results in high mutual information between different views of the same identity. The effectiveness of the proposed model is investigated through extensive experiments, evaluations, and ablation studies on four benchmark datasets, and comparison with the compelling state-of-the-art algorithms.
Revisiting Outer Optimization in Adversarial Training
Sep 02, 2022
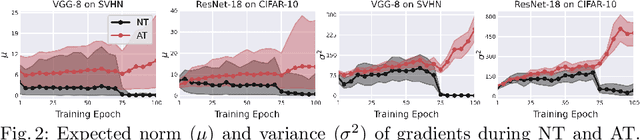
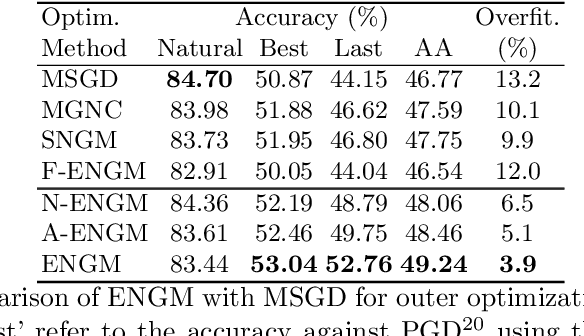

Despite the fundamental distinction between adversarial and natural training (AT and NT), AT methods generally adopt momentum SGD (MSGD) for the outer optimization. This paper aims to analyze this choice by investigating the overlooked role of outer optimization in AT. Our exploratory evaluations reveal that AT induces higher gradient norm and variance compared to NT. This phenomenon hinders the outer optimization in AT since the convergence rate of MSGD is highly dependent on the variance of the gradients. To this end, we propose an optimization method called ENGM which regularizes the contribution of each input example to the average mini-batch gradients. We prove that the convergence rate of ENGM is independent of the variance of the gradients, and thus, it is suitable for AT. We introduce a trick to reduce the computational cost of ENGM using empirical observations on the correlation between the norm of gradients w.r.t. the network parameters and input examples. Our extensive evaluations and ablation studies on CIFAR-10, CIFAR-100, and TinyImageNet demonstrate that ENGM and its variants consistently improve the performance of a wide range of AT methods. Furthermore, ENGM alleviates major shortcomings of AT including robust overfitting and high sensitivity to hyperparameter settings.
GAN-based Super-Resolution and Segmentation of Retinal Layers in Optical coherence tomography Scans
Jun 28, 2022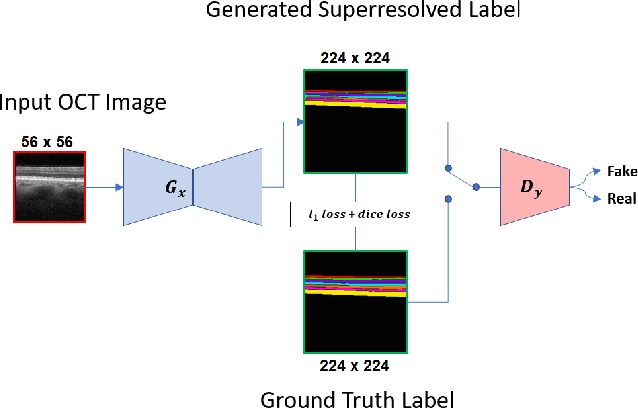
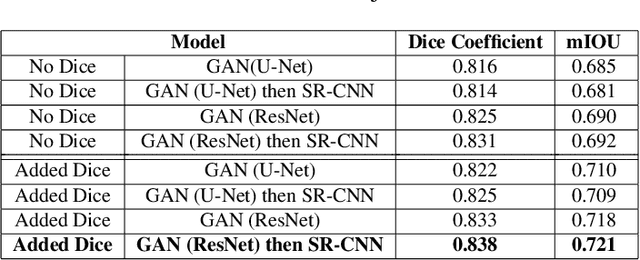
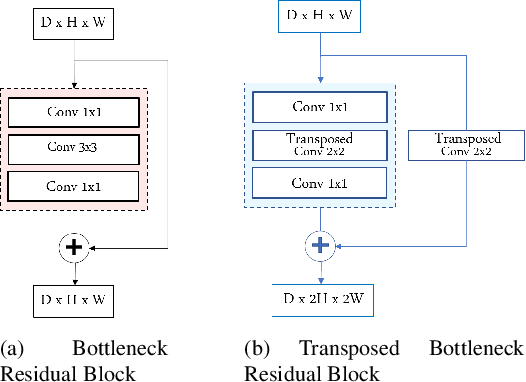
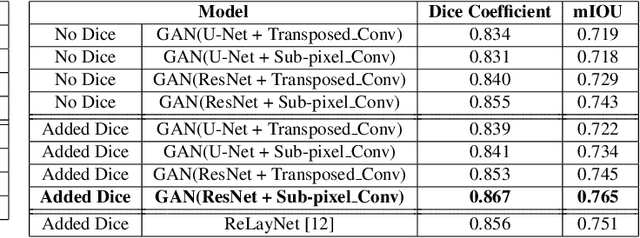
In this paper, we design a Generative Adversarial Network (GAN)-based solution for super-resolution and segmentation of optical coherence tomography (OCT) scans of the retinal layers. OCT has been identified as a non-invasive and inexpensive modality of imaging to discover potential biomarkers for the diagnosis and progress determination of neurodegenerative diseases, such as Alzheimer's Disease (AD). Current hypotheses presume the thickness of the retinal layers, which are analyzable within OCT scans, can be effective biomarkers. As a logical first step, this work concentrates on the challenging task of retinal layer segmentation and also super-resolution for higher clarity and accuracy. We propose a GAN-based segmentation model and evaluate incorporating popular networks, namely, U-Net and ResNet, in the GAN architecture with additional blocks of transposed convolution and sub-pixel convolution for the task of upscaling OCT images from low to high resolution by a factor of four. We also incorporate the Dice loss as an additional reconstruction loss term to improve the performance of this joint optimization task. Our best model configuration empirically achieved the Dice coefficient of 0.867 and mIOU of 0.765.
Superresolution and Segmentation of OCT scans using Multi-Stage adversarial Guided Attention Training
Jun 10, 2022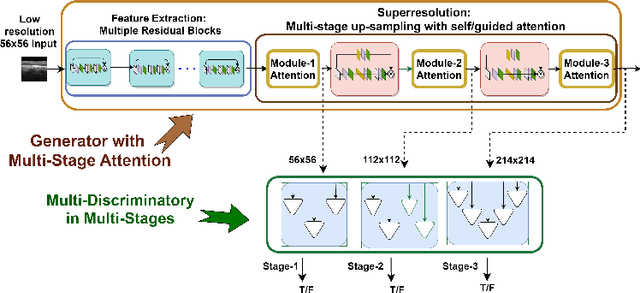

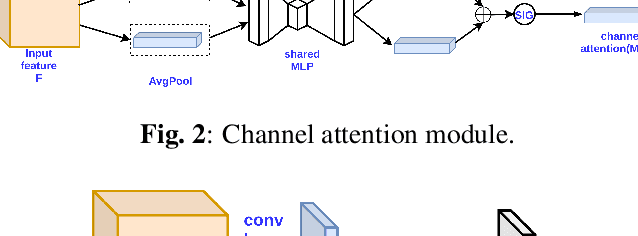
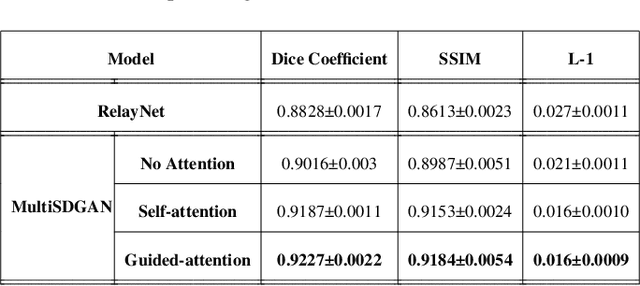
Optical coherence tomography (OCT) is one of the non-invasive and easy-to-acquire biomarkers (the thickness of the retinal layers, which is detectable within OCT scans) being investigated to diagnose Alzheimer's disease (AD). This work aims to segment the OCT images automatically; however, it is a challenging task due to various issues such as the speckle noise, small target region, and unfavorable imaging conditions. In our previous work, we have proposed the multi-stage & multi-discriminatory generative adversarial network (MultiSDGAN) to translate OCT scans in high-resolution segmentation labels. In this investigation, we aim to evaluate and compare various combinations of channel and spatial attention to the MultiSDGAN architecture to extract more powerful feature maps by capturing rich contextual relationships to improve segmentation performance. Moreover, we developed and evaluated a guided mutli-stage attention framework where we incorporated a guided attention mechanism by forcing an L-1 loss between a specifically designed binary mask and the generated attention maps. Our ablation study results on the WVU-OCT data-set in five-fold cross-validation (5-CV) suggest that the proposed MultiSDGAN with a serial attention module provides the most competitive performance, and guiding the spatial attention feature maps by binary masks further improves the performance in our proposed network. Comparing the baseline model with adding the guided-attention, our results demonstrated relative improvements of 21.44% and 19.45% on the Dice coefficient and SSIM, respectively.
Quality-Aware Multimodal Biometric Recognition
Dec 10, 2021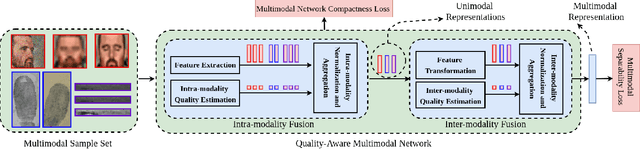
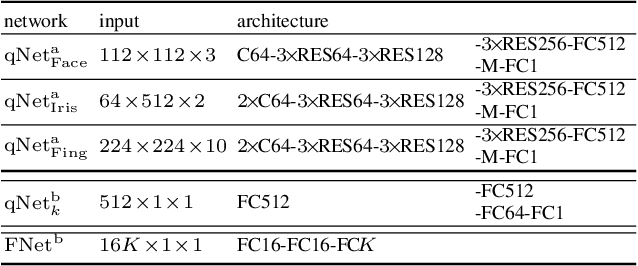
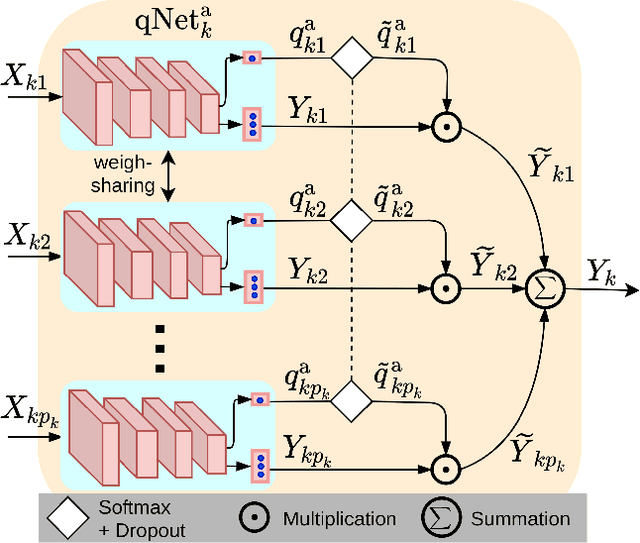
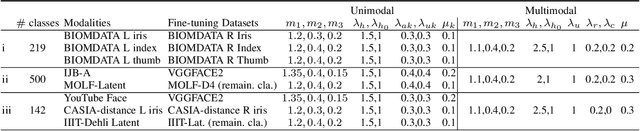
We present a quality-aware multimodal recognition framework that combines representations from multiple biometric traits with varying quality and number of samples to achieve increased recognition accuracy by extracting complimentary identification information based on the quality of the samples. We develop a quality-aware framework for fusing representations of input modalities by weighting their importance using quality scores estimated in a weakly-supervised fashion. This framework utilizes two fusion blocks, each represented by a set of quality-aware and aggregation networks. In addition to architecture modifications, we propose two task-specific loss functions: multimodal separability loss and multimodal compactness loss. The first loss assures that the representations of modalities for a class have comparable magnitudes to provide a better quality estimation, while the multimodal representations of different classes are distributed to achieve maximum discrimination in the embedding space. The second loss, which is considered to regularize the network weights, improves the generalization performance by regularizing the framework. We evaluate the performance by considering three multimodal datasets consisting of face, iris, and fingerprint modalities. The efficacy of the framework is demonstrated through comparison with the state-of-the-art algorithms. In particular, our framework outperforms the rank- and score-level fusion of modalities of BIOMDATA by more than 30% for true acceptance rate at false acceptance rate of $10^{-4}$.