 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Comparative Study of Word and Sentence Similarity Measures
Feb 17, 2016
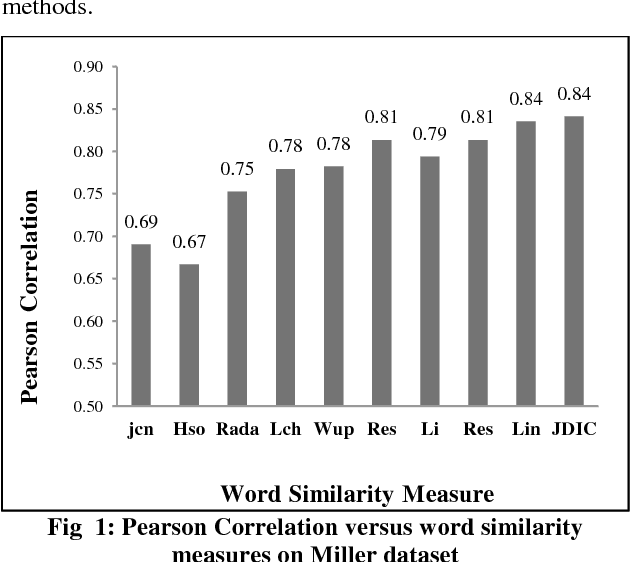
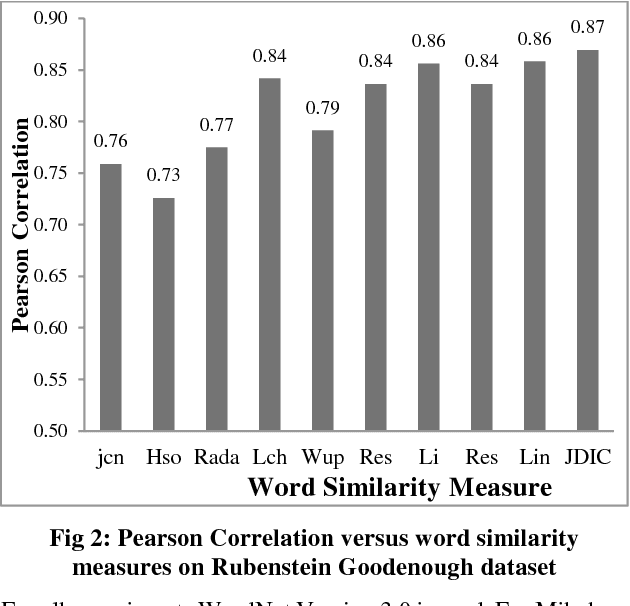
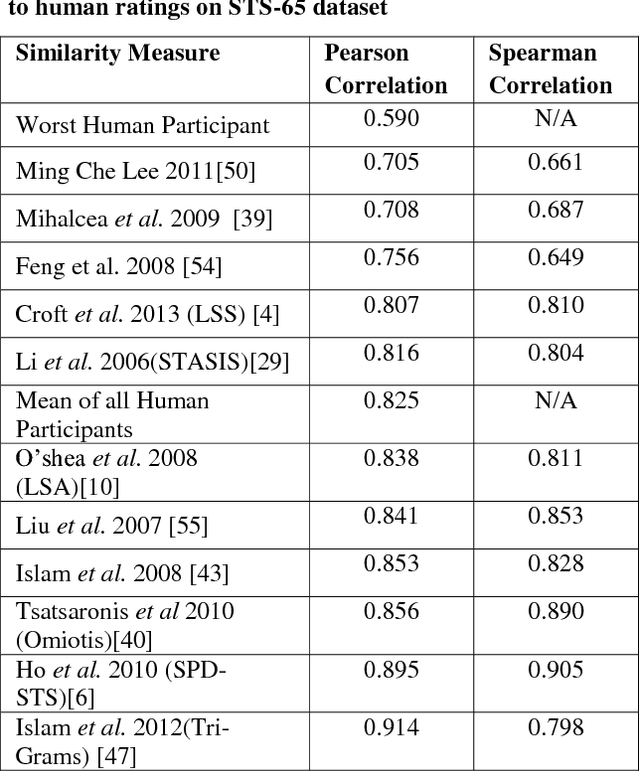
Sentence similarity is considered the basis of many natural language tasks such as information retrieval, question answering and text summarization. The semantic meaning between compared text fragments is based on the words semantic features and their relationships. This article reviews a set of word and sentence similarity measures and compares them on benchmark datasets. On the studied datasets, results showed that hybrid semantic measures perform better than both knowledge and corpus based measures.
* 7 pages,4 figures
Building a Pilot Software Quality-in-Use Benchmark Dataset
Sep 18, 2015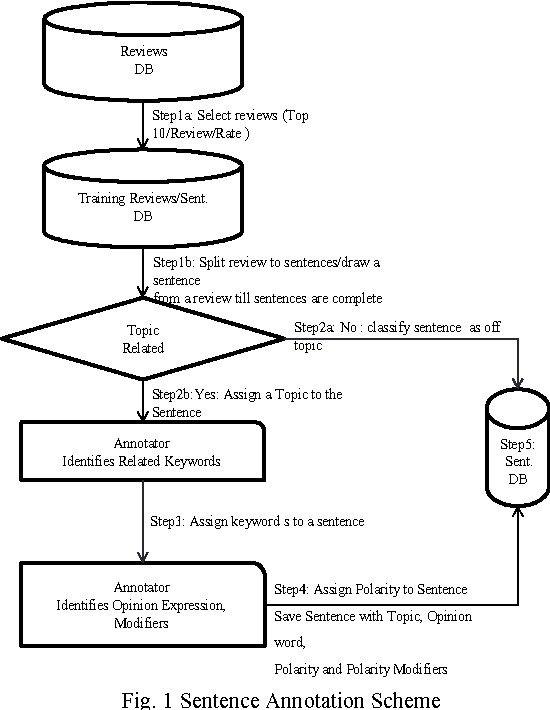
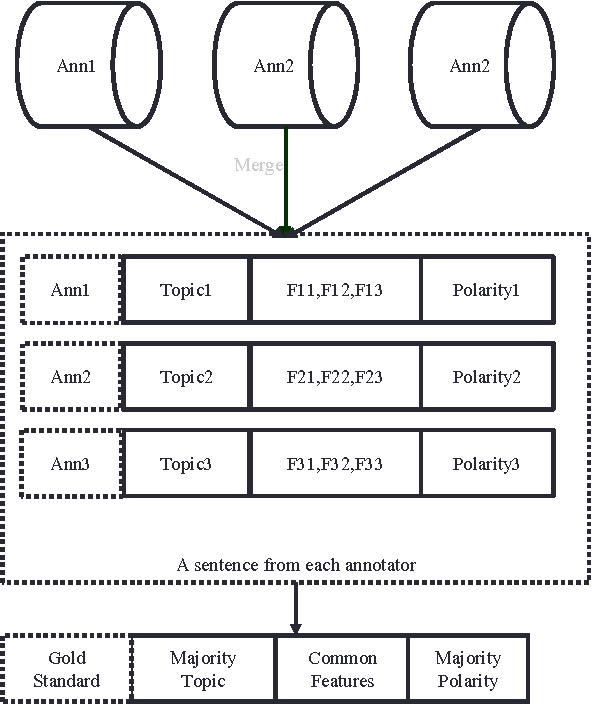
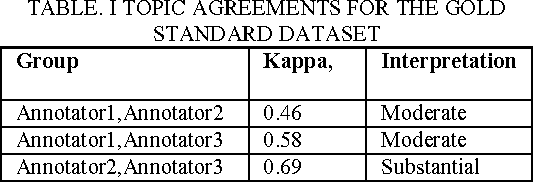
Prepared domain specific datasets plays an important role to supervised learning approaches. In this article a new sentence dataset for software quality-in-use is proposed. Three experts were chosen to annotate the data using a proposed annotation scheme. Then the data were reconciled in a (no match eliminate) process to reduce bias. The Kappa, k statistics revealed an acceptable level of agreement; moderate to substantial agreement between the experts. The built data can be used to evaluate software quality-in-use models in sentiment analysis models. Moreover, the annotation scheme can be used to extend the current dataset.
Towards Resolving Software Quality-in-Use Measurement Challenges
Jan 30, 2015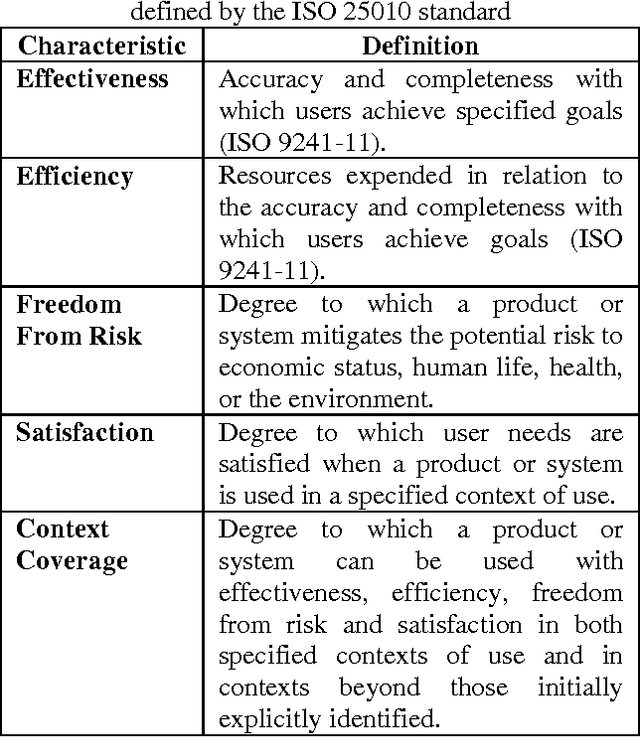
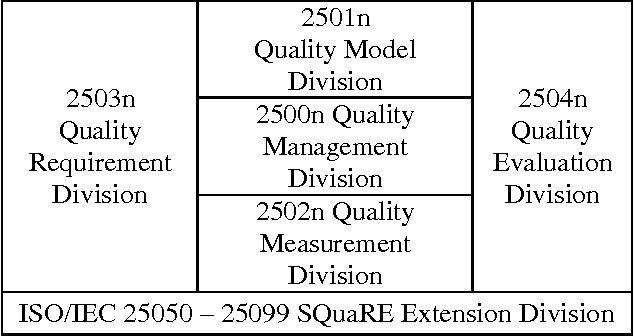
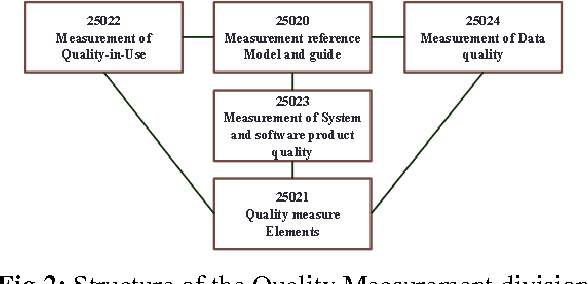
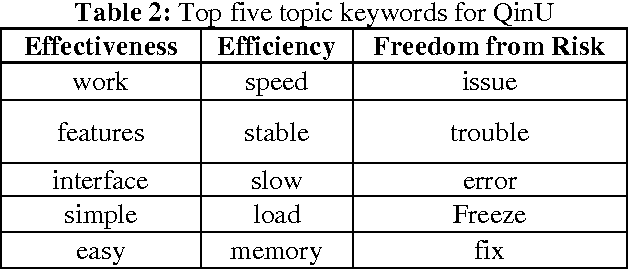
Software quality-in-use comprehends the quality from user's perspectives. It has gained its importance in e-learning applications, mobile service based applications and project management tools. User's decisions on software acquisitions are often ad hoc or based on preference due to difficulty in quantitatively measure software quality-in-use. However, why quality-in-use measurement is difficult? Although there are many software quality models to our knowledge, no works surveys the challenges related to software quality-in-use measurement. This paper has two main contributions; 1) presents major issues and challenges in measuring software quality-in-use in the context of the ISO SQuaRE series and related software quality models, 2) Presents a novel framework that can be used to predict software quality-in-use, and 3) presents preliminary results of quality-in-use topic prediction. Concisely, the issues are related to the complexity of the current standard models and the limitations and incompleteness of the customized software quality models. The proposed framework employs sentiment analysis techniques to predict software quality-in-use.