 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Comparative Study of Word and Sentence Similarity Measures
Feb 17, 2016
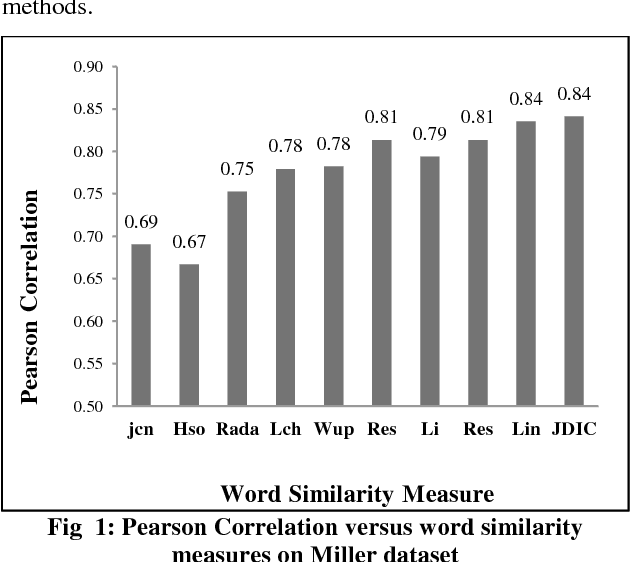
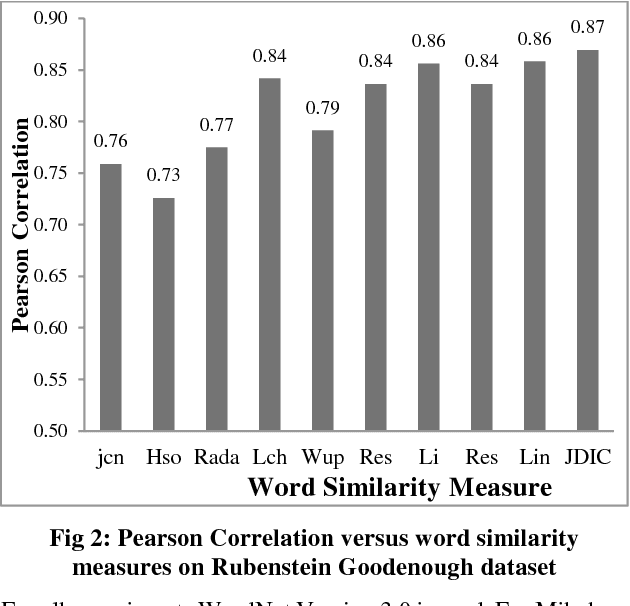
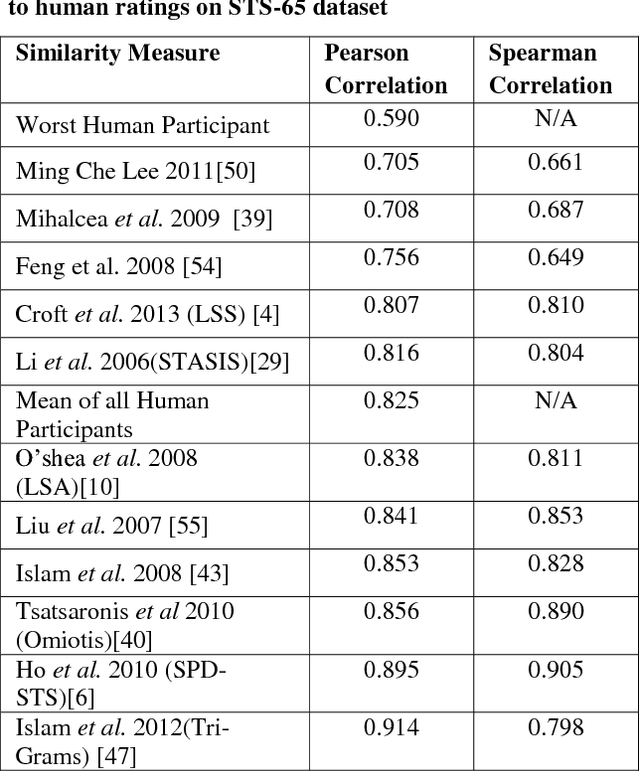
Sentence similarity is considered the basis of many natural language tasks such as information retrieval, question answering and text summarization. The semantic meaning between compared text fragments is based on the words semantic features and their relationships. This article reviews a set of word and sentence similarity measures and compares them on benchmark datasets. On the studied datasets, results showed that hybrid semantic measures perform better than both knowledge and corpus based measures.
* 7 pages,4 figures
Mining Software Quality from Software Reviews: Research Trends and Open Issues
Feb 05, 2016Software review text fragments have considerably valuable information about users experience. It includes a huge set of properties including the software quality. Opinion mining or sentiment analysis is concerned with analyzing textual user judgments. The application of sentiment analysis on software reviews can find a quantitative value that represents software quality. Although many software quality methods are proposed they are considered difficult to customize and many of them are limited. This article investigates the application of opinion mining as an approach to extract software quality properties. We found that the major issues of software reviews mining using sentiment analysis are due to software lifecycle and the diverse users and teams.
* 11 pages
Building a Pilot Software Quality-in-Use Benchmark Dataset
Sep 18, 2015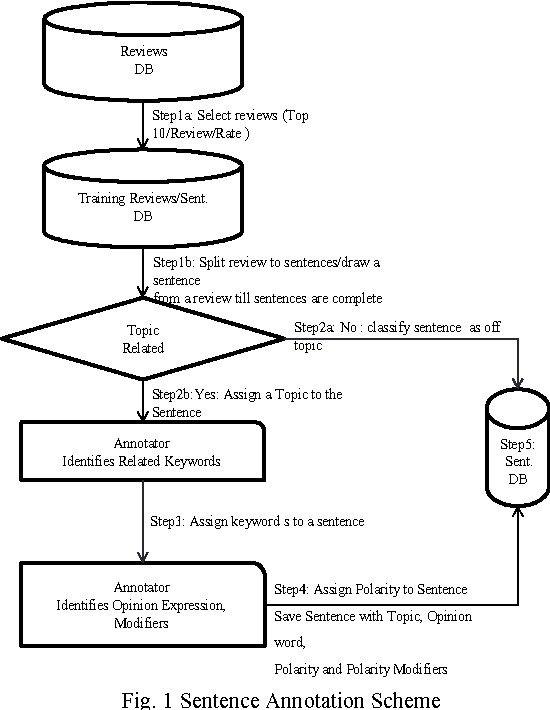
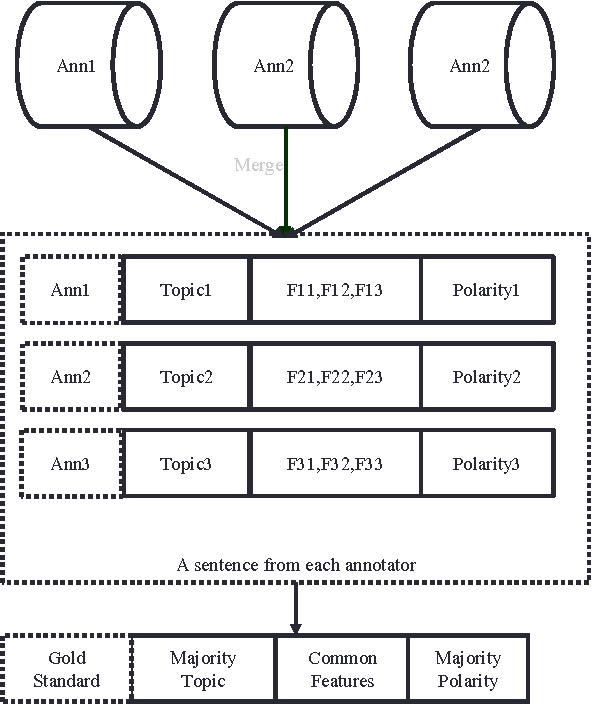
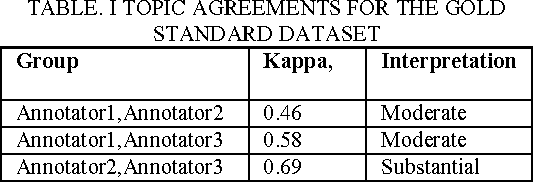
Prepared domain specific datasets plays an important role to supervised learning approaches. In this article a new sentence dataset for software quality-in-use is proposed. Three experts were chosen to annotate the data using a proposed annotation scheme. Then the data were reconciled in a (no match eliminate) process to reduce bias. The Kappa, k statistics revealed an acceptable level of agreement; moderate to substantial agreement between the experts. The built data can be used to evaluate software quality-in-use models in sentiment analysis models. Moreover, the annotation scheme can be used to extend the current dataset.
Using Latent Semantic Analysis to Identify Quality in Use (QU) Indicators from User Reviews
Mar 25, 2015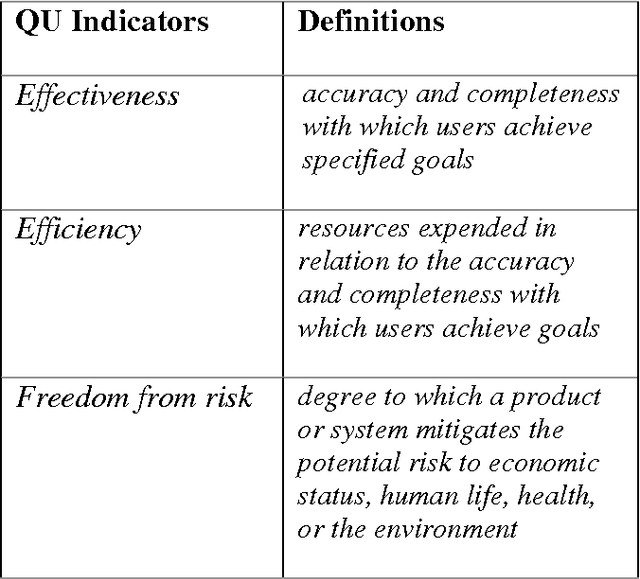
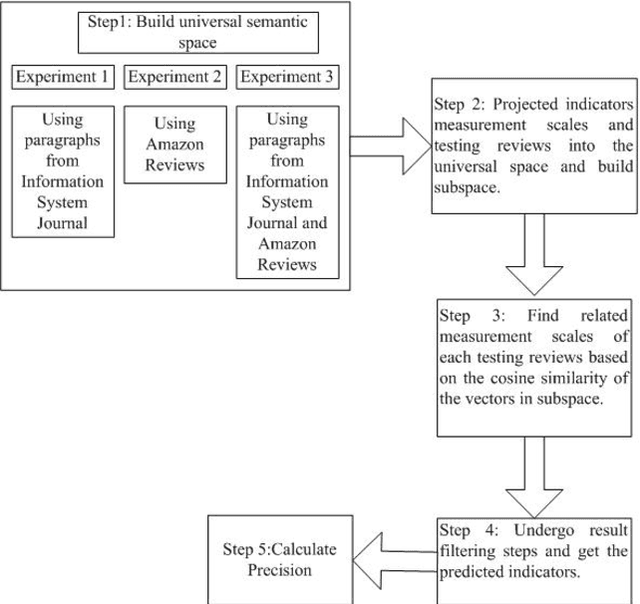
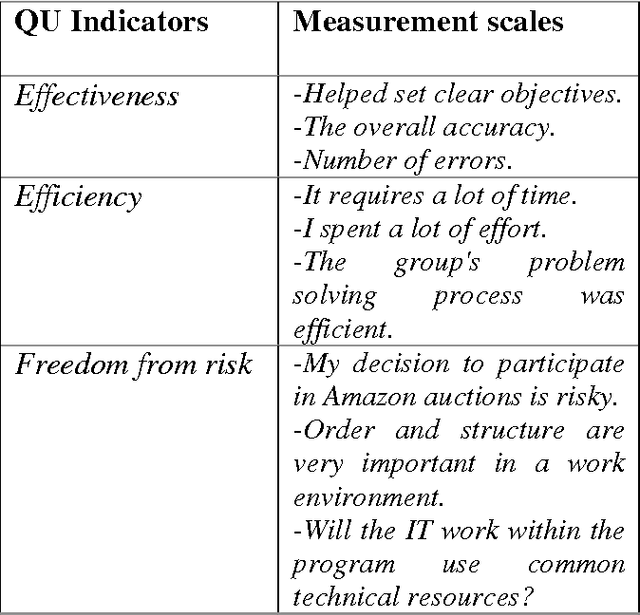
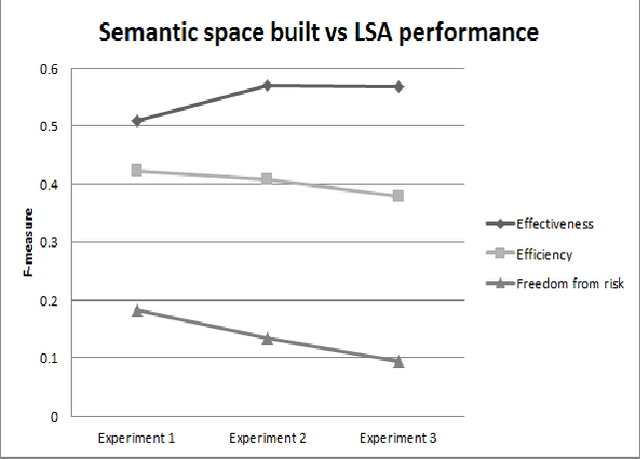
The paper describes a novel approach to categorize users' reviews according to the three Quality in Use (QU) indicators defined in ISO: effectiveness, efficiency and freedom from risk. With the tremendous amount of reviews published each day, there is a need to automatically summarize user reviews to inform us if any of the software able to meet requirement of a company according to the quality requirements. We implemented the method of Latent Semantic Analysis (LSA) and its subspace to predict QU indicators. We build a reduced dimensionality universal semantic space from Information System journals and Amazon reviews. Next, we projected set of indicators' measurement scales into the universal semantic space and represent them as subspace. In the subspace, we can map similar measurement scales to the unseen reviews and predict the QU indicators. Our preliminary study able to obtain the average of F-measure, 0.3627.
Measuring Software Quality in Use: State-of-the-Art and Research Challenges
Mar 24, 2015
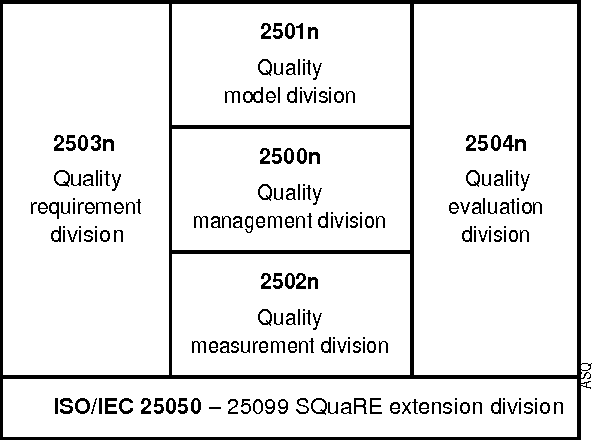
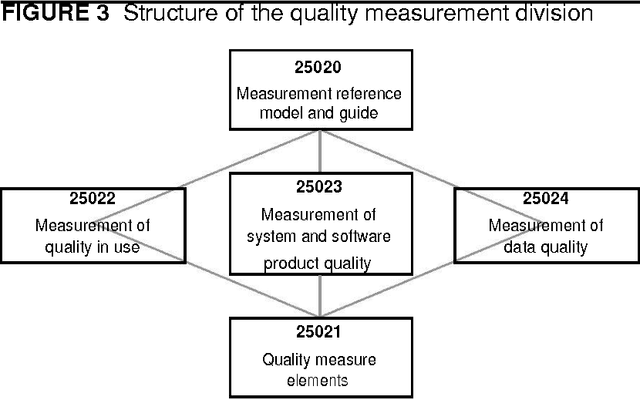
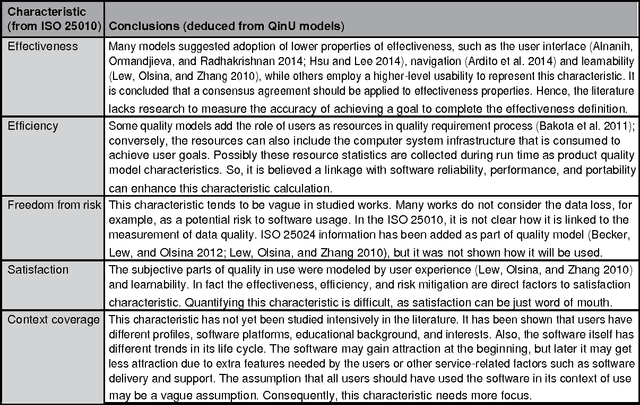
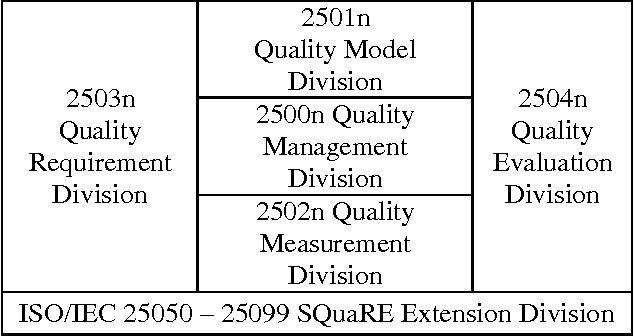
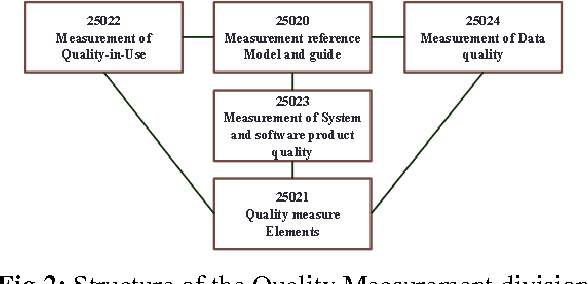
Software quality in use comprises quality from the user's perspective. It has gained its importance in e-government applications, mobile-based applications, embedded systems, and even business process development. User's decisions on software acquisitions are often ad hoc or based on preference due to difficulty in quantitatively measuring software quality in use. But, why is quality-in-use measurement difficult? Although there are many software quality models, to the authors' knowledge no works survey the challenges related to software quality-in-use measurement. This article has two main contributions: 1) it identifies and explains major issues and challenges in measuring software quality in use in the context of the ISO SQuaRE series and related software quality models and highlights open research areas; and 2) it sheds light on a research direction that can be used to predict software quality in use. In short, the quality-in-use measurement issues are related to the complexity of the current standard models and the limitations and incompleteness of the customized software quality models. A sentiment analysis of software reviews is proposed to deal with these issues.
* 4 Figures
Towards Resolving Software Quality-in-Use Measurement Challenges
Jan 30, 2015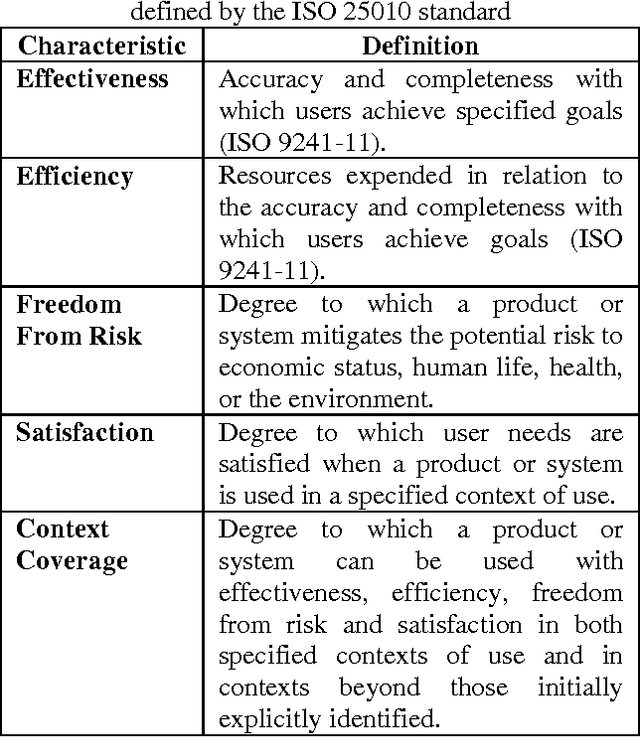
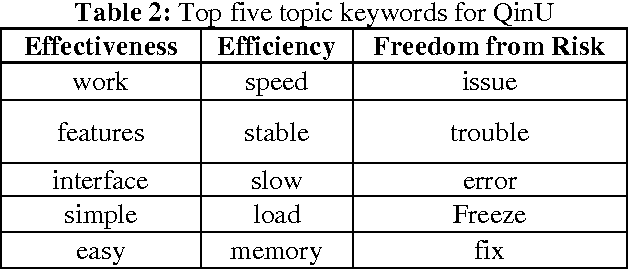
Software quality-in-use comprehends the quality from user's perspectives. It has gained its importance in e-learning applications, mobile service based applications and project management tools. User's decisions on software acquisitions are often ad hoc or based on preference due to difficulty in quantitatively measure software quality-in-use. However, why quality-in-use measurement is difficult? Although there are many software quality models to our knowledge, no works surveys the challenges related to software quality-in-use measurement. This paper has two main contributions; 1) presents major issues and challenges in measuring software quality-in-use in the context of the ISO SQuaRE series and related software quality models, 2) Presents a novel framework that can be used to predict software quality-in-use, and 3) presents preliminary results of quality-in-use topic prediction. Concisely, the issues are related to the complexity of the current standard models and the limitations and incompleteness of the customized software quality models. The proposed framework employs sentiment analysis techniques to predict software quality-in-use.