 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying inductive biases in image classification task
Oct 31, 2022Recently, self-attention (SA) structures became popular in computer vision fields. They have locally independent filters and can use large kernels, which contradicts the previously popular convolutional neural networks (CNNs). CNNs success was attributed to the hard-coded inductive biases of locality and spatial invariance. However, recent studies have shown that inductive biases in CNNs are too restrictive. On the other hand, the relative position encodings, similar to depthwise (DW) convolution, are necessary for the local SA networks, which indicates that the SA structures are not entirely spatially variant. Hence, we would like to determine which part of inductive biases contributes to the success of the local SA structures. To do so, we introduced context-aware decomposed attention (CADA), which decomposes attention maps into multiple trainable base kernels and accumulates them using context-aware (CA) parameters. This way, we could identify the link between the CNNs and SA networks. We conducted ablation studies using the ResNet50 applied to the ImageNet classification task. DW convolution could have a large locality without increasing computational costs compared to CNNs, but the accuracy saturates with larger kernels. CADA follows this characteristic of locality. We showed that context awareness was the crucial property; however, large local information was not necessary to construct CA parameters. Even though no spatial invariance makes training difficult, more relaxed spatial invariance gave better accuracy than strict spatial invariance. Also, additional strong spatial invariance through relative position encoding was preferable. We extended these experiments to filters for downsampling and showed that locality bias is more critical for downsampling but can remove the strong locality bias using relaxed spatial invariance.
Gabor filter incorporated CNN for compression
Oct 29, 2021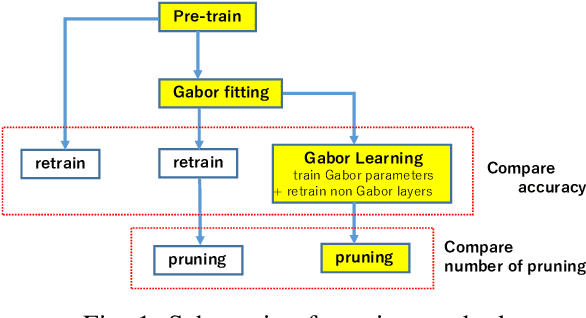
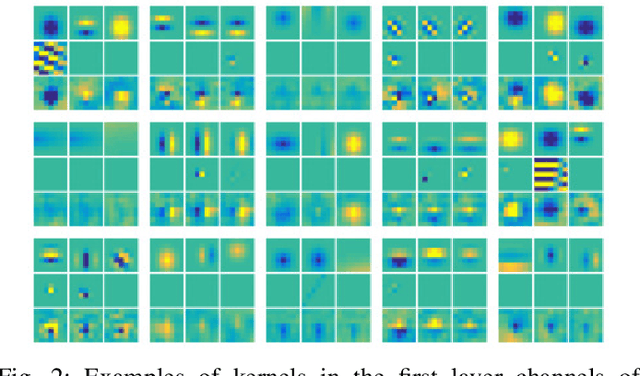
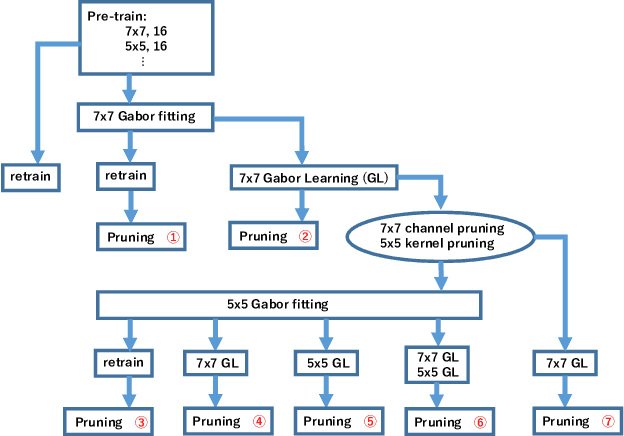
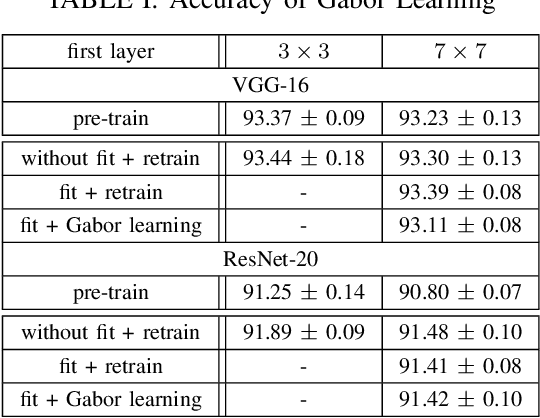
Convolutional neural networks (CNNs) are remarkably successful in many computer vision tasks. However, the high cost of inference is problematic for embedded and real-time systems, so there are many studies on compressing the networks. On the other hand, recent advances in self-attention models showed that convolution filters are preferable to self-attention in the earlier layers, which indicates that stronger inductive biases are better in the earlier layers. As shown in convolutional filters, strong biases can train specific filters and construct unnecessarily filters to zero. This is analogous to classical image processing tasks, where choosing the suitable filters makes a compact dictionary to represent features. We follow this idea and incorporate Gabor filters in the earlier layers of CNNs for compression. The parameters of Gabor filters are learned through backpropagation, so the features are restricted to Gabor filters. We show that the first layer of VGG-16 for CIFAR-10 has 192 kernels/features, but learning Gabor filters requires an average of 29.4 kernels. Also, using Gabor filters, an average of 83% and 94% of kernels in the first and the second layer, respectively, can be removed on the altered ResNet-20, where the first five layers are exchanged with two layers of larger kernels for CIFAR-10.