 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
Hardware/Software Co-Design of RISC-V Extensions for Accelerating Sparse DNNs on FPGAs
Apr 28, 2025



The customizability of RISC-V makes it an attractive choice for accelerating deep neural networks (DNNs). It can be achieved through instruction set extensions and corresponding custom functional units. Yet, efficiently exploiting these opportunities requires a hardware/software co-design approach in which the DNN model, software, and hardware are designed together. In this paper, we propose novel RISC-V extensions for accelerating DNN models containing semi-structured and unstructured sparsity. While the idea of accelerating structured and unstructured pruning is not new, our novel design offers various advantages over other designs. To exploit semi-structured sparsity, we take advantage of the fine-grained (bit-level) configurability of FPGAs and suggest reserving a few bits in a block of DNN weights to encode the information about sparsity in the succeeding blocks. The proposed custom functional unit utilizes this information to skip computations. To exploit unstructured sparsity, we propose a variable cycle sequential multiply-and-accumulate unit that performs only as many multiplications as the non-zero weights. Our implementation of unstructured and semi-structured pruning accelerators can provide speedups of up to a factor of 3 and 4, respectively. We then propose a combined design that can accelerate both types of sparsities, providing speedups of up to a factor of 5. Our designs consume a small amount of additional FPGA resources such that the resulting co-designs enable the acceleration of DNNs even on small FPGAs. We benchmark our designs on standard TinyML applications such as keyword spotting, image classification, and person detection.
Utilizing Explainable AI for Quantization and Pruning of Deep Neural Networks
Aug 20, 2020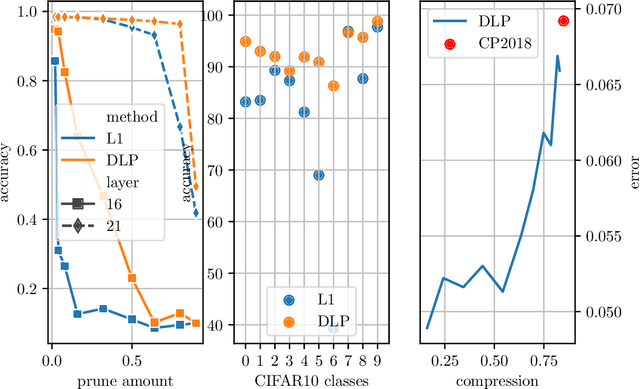

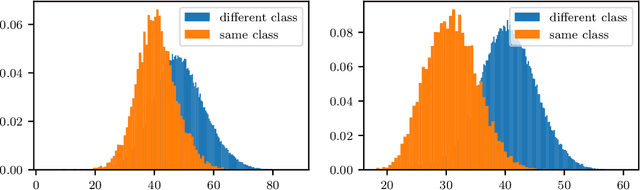
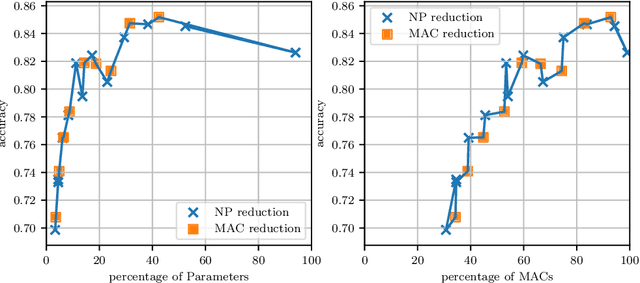
For many applications, utilizing DNNs (Deep Neural Networks) requires their implementation on a target architecture in an optimized manner concerning energy consumption, memory requirement, throughput, etc. DNN compression is used to reduce the memory footprint and complexity of a DNN before its deployment on hardware. Recent efforts to understand and explain AI (Artificial Intelligence) methods have led to a new research area, termed as explainable AI. Explainable AI methods allow us to understand better the inner working of DNNs, such as the importance of different neurons and features. The concepts from explainable AI provide an opportunity to improve DNN compression methods such as quantization and pruning in several ways that have not been sufficiently explored so far. In this paper, we utilize explainable AI methods: mainly DeepLIFT method. We use these methods for (1) pruning of DNNs; this includes structured and unstructured pruning of \ac{CNN} filters pruning as well as pruning weights of fully connected layers, (2) non-uniform quantization of DNN weights using clustering algorithm; this is also referred to as Weight Sharing, and (3) integer-based mixed-precision quantization; this is where each layer of a DNN may use a different number of integer bits. We use typical image classification datasets with common deep learning image classification models for evaluation. In all these three cases, we demonstrate significant improvements as well as new insights and opportunities from the use of explainable AI in DNN compression.