 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Classification of Large Time Series Datasets
Dec 10, 2023



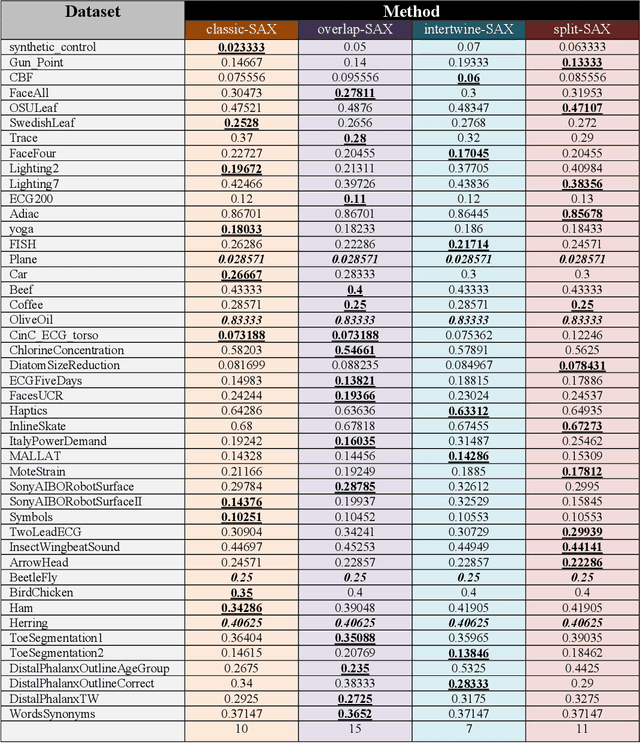
Time series classification (TSC) is the most import task in time series mining as it has several applications in medicine, meteorology, finance cyber security, and many others. With the ever increasing size of time series datasets, several traditional TSC methods are no longer efficient enough to perform this task on such very large datasets. Yet, most recent papers on TSC focus mainly on accuracy by using methods that apply deep learning, for instance, which require extensive computational resources that cannot be applied efficiently to very large datasets. The method we introduce in this paper focuses on these very large time series datasets with the main objective being efficiency. We achieve this through a simplified representation of the time series. This in turn is enhanced by a distance measure that considers only some of the values of the represented time series. The result of this combination is a very efficient representation method for TSC. This has been tested experimentally against another time series method that is particularly popular for its efficiency. The experiments show that our method is not only 4 times faster, on average, but it is also superior in terms of classification accuracy, as it gives better results on 24 out of the 29 tested time series datasets. .
TSAX is Trending
Dec 24, 2021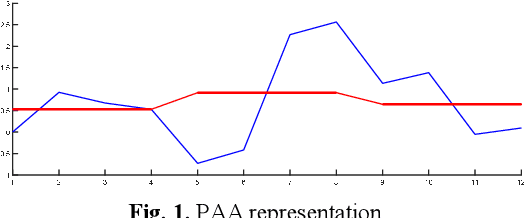
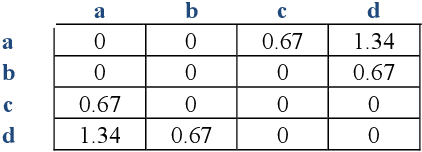
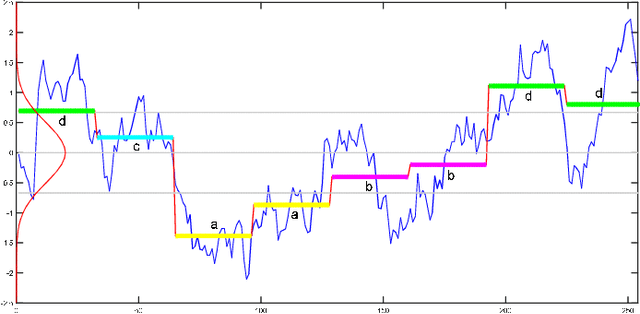
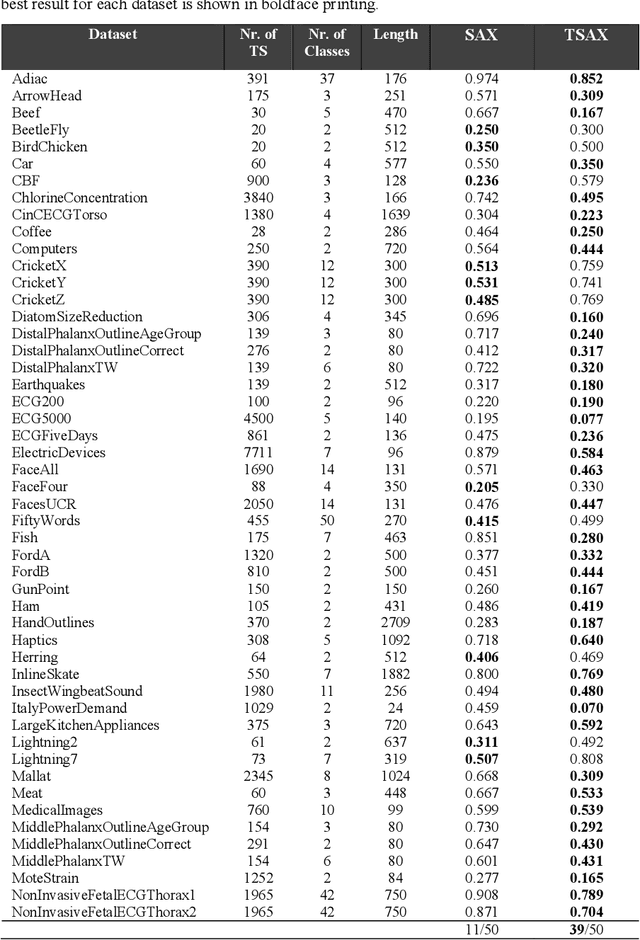
Time series mining is an important branch of data mining, as time series data is ubiquitous and has many applications in several domains. The main task in time series mining is classification. Time series representation methods play an important role in time series classification and other time series mining tasks. One of the most popular representation methods of time series data is the Symbolic Aggregate approXimation (SAX). The secret behind its popularity is its simplicity and efficiency. SAX has however one major drawback, which is its inability to represent trend information. Several methods have been proposed to enable SAX to capture trend information, but this comes at the expense of complex processing, preprocessing, or post-processing procedures. In this paper we present a new modification of SAX that we call Trending SAX (TSAX), which only adds minimal complexity to SAX, but substantially improves its performance in time series classification. This is validated experimentally on 50 datasets. The results show the superior performance of our method, as it gives a smaller classification error on 39 datasets compared with SAX.
* 21st International Conference on Computational Science (ICCS 2021)
Extreme-SAX: Extreme Points Based Symbolic Representation for Time Series Classification
Oct 02, 2020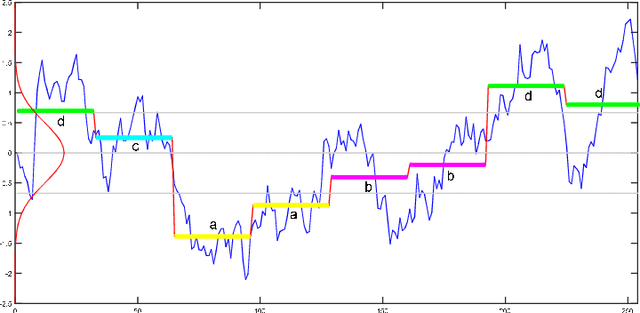
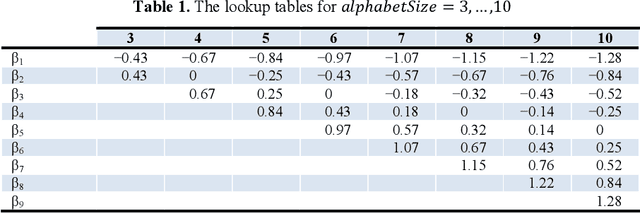
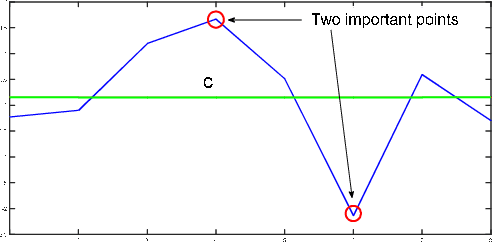
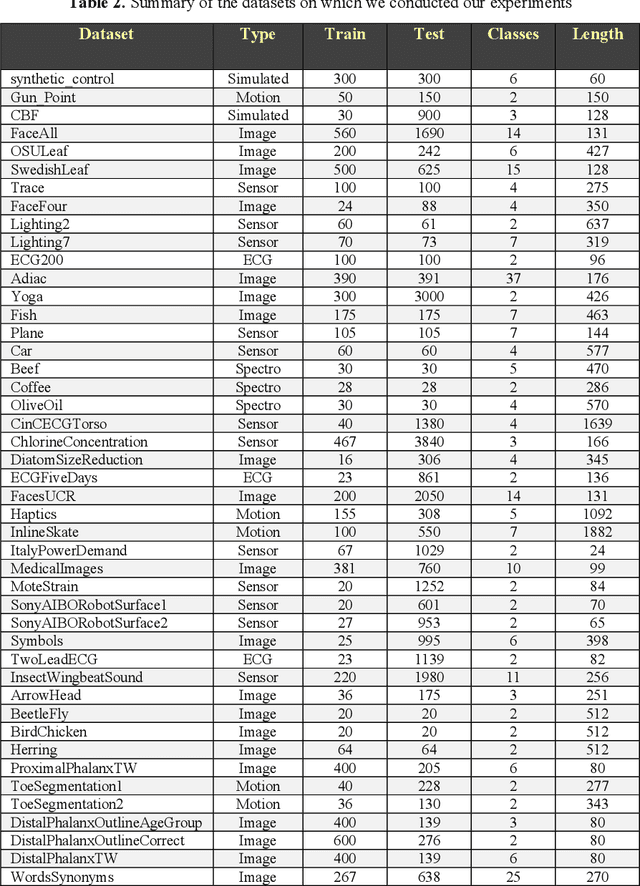
Time series classification is an important problem in data mining with several applications in different domains. Because time series data are usually high dimensional, dimensionality reduction techniques have been proposed as an efficient approach to lower their dimensionality. One of the most popular dimensionality reduction techniques of time series data is the Symbolic Aggregate Approximation (SAX), which is inspired by algorithms from text mining and bioinformatics. SAX is simple and efficient because it uses precomputed distances. The disadvantage of SAX is its inability to accurately represent important points in the time series. In this paper we present Extreme-SAX (E-SAX), which uses only the extreme points of each segment to represent the time series. E-SAX has exactly the same simplicity and efficiency of the original SAX, yet it gives better results in time series classification than the original SAX, as we show in extensive experiments on a variety of time series datasets.
* International Conference on Big Data Analytics and Knowledge Discovery - DaWaK 2020: Big Data Analytics and Knowledge Discovery pp 122-130
Modifying the Symbolic Aggregate Approximation Method to Capture Segment Trend Information
Oct 02, 2020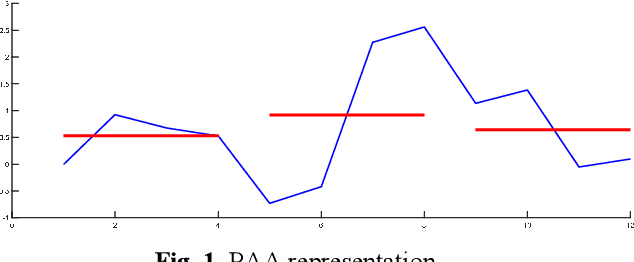
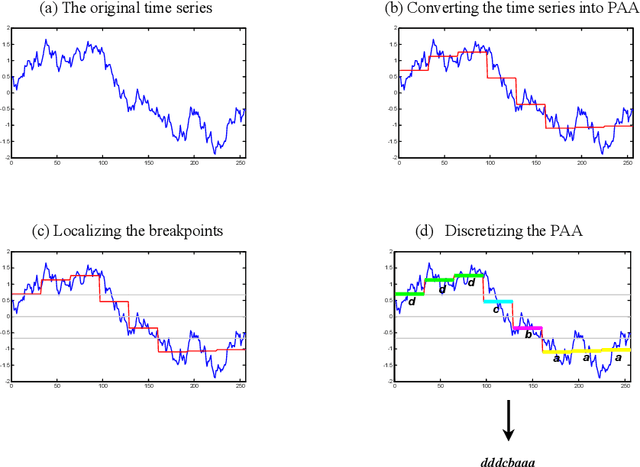
The Symbolic Aggregate approXimation (SAX) is a very popular symbolic dimensionality reduction technique of time series data, as it has several advantages over other dimensionality reduction techniques. One of its major advantages is its efficiency, as it uses precomputed distances. The other main advantage is that in SAX the distance measure defined on the reduced space lower bounds the distance measure defined on the original space. This enables SAX to return exact results in query-by-content tasks. Yet SAX has an inherent drawback, which is its inability to capture segment trend information. Several researchers have attempted to enhance SAX by proposing modifications to include trend information. However, this comes at the expense of giving up on one or more of the advantages of SAX. In this paper we investigate three modifications of SAX to add trend capturing ability to it. These modifications retain the same features of SAX in terms of simplicity, efficiency, as well as the exact results it returns. They are simple procedures based on a different segmentation of the time series than that used in classic-SAX. We test the performance of these three modifications on 45 time series datasets of different sizes, dimensions, and nature, on a classification task and we compare it to that of classic-SAX. The results we obtained show that one of these modifications manages to outperform classic-SAX and that another one slightly gives better results than classic-SAX.
* International Conference on Modeling Decisions for Artificial Intelligence - MDAI 2020: Modeling Decisions for Artificial Intelligence pp 230-239
Applying Nature-Inspired Optimization Algorithms for Selecting Important Timestamps to Reduce Time Series Dimensionality
Dec 09, 2018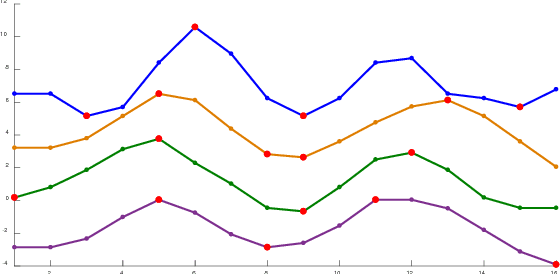
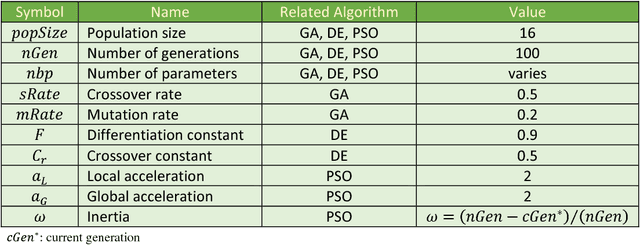
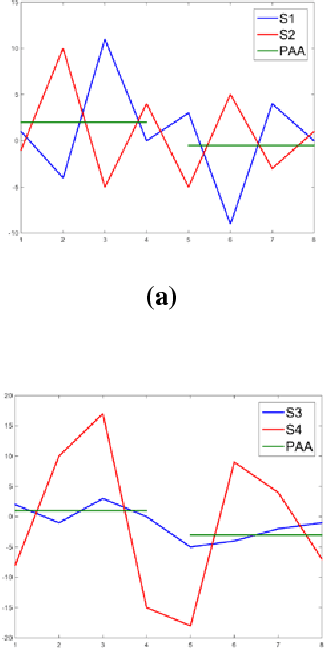
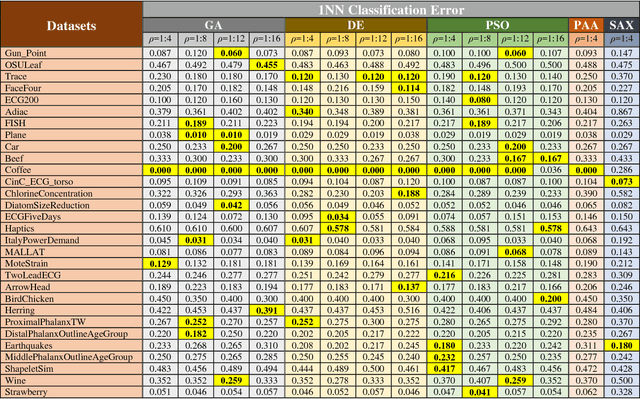
Time series data account for a major part of data supply available today. Time series mining handles several tasks such as classification, clustering, query-by-content, prediction, and others. Performing data mining tasks on raw time series is inefficient as these data are high-dimensional by nature. Instead, time series are first pre-processed using several techniques before different data mining tasks can be performed on them. In general, there are two main approaches to reduce time series dimensionality, the first is what we call landmark methods. These methods are based on finding characteristic features in the target time series. The second is based on data transformations. These methods transform the time series from the original space into a reduced space, where they can be managed more efficiently. The method we present in this paper applies a third approach, as it projects a time series onto a lower-dimensional space by selecting important points in the time series. The novelty of our method is that these points are not chosen according to a geometric criterion, which is subjective in most cases, but through an optimization process. The other important characteristic of our method is that these important points are selected on a dataset-level and not on a single time series-level. The direct advantage of this strategy is that the distance defined on the low-dimensional space lower bounds the original distance applied to raw data. This enables us to apply the popular GEMINI algorithm. The promising results of our experiments on a wide variety of time series datasets, using different optimizers, and applied to the two major data mining tasks, validate our new method.
One-Step or Two-Step Optimization and the Overfitting Phenomenon: A Case Study on Time Series Classification
Jul 16, 2014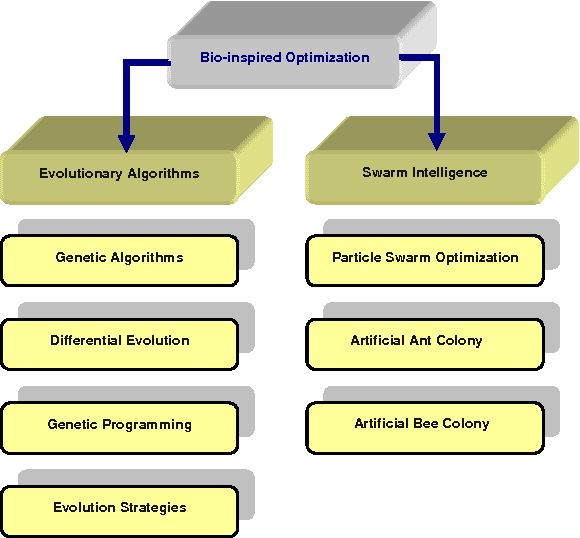
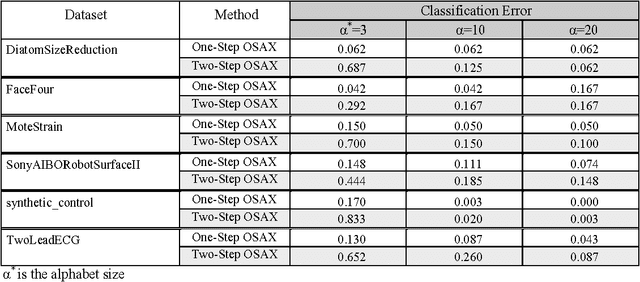
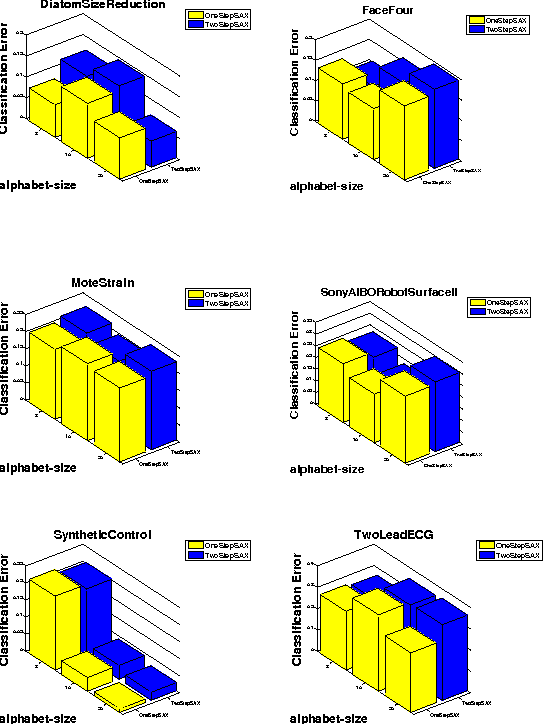
For the last few decades, optimization has been developing at a fast rate. Bio-inspired optimization algorithms are metaheuristics inspired by nature. These algorithms have been applied to solve different problems in engineering, economics, and other domains. Bio-inspired algorithms have also been applied in different branches of information technology such as networking and software engineering. Time series data mining is a field of information technology that has its share of these applications too. In previous works we showed how bio-inspired algorithms such as the genetic algorithms and differential evolution can be used to find the locations of the breakpoints used in the symbolic aggregate approximation of time series representation, and in another work we showed how we can utilize the particle swarm optimization, one of the famous bio-inspired algorithms, to set weights to the different segments in the symbolic aggregate approximation representation. In this paper we present, in two different approaches, a new meta optimization process that produces optimal locations of the breakpoints in addition to optimal weights of the segments. The experiments of time series classification task that we conducted show an interesting example of how the overfitting phenomenon, a frequently encountered problem in data mining which happens when the model overfits the training set, can interfere in the optimization process and hide the superior performance of an optimization algorithm.
Towards Normalizing the Edit Distance Using a Genetic Algorithms Based Scheme
Dec 06, 2013
The normalized edit distance is one of the distances derived from the edit distance. It is useful in some applications because it takes into account the lengths of the two strings compared. The normalized edit distance is not defined in terms of edit operations but rather in terms of the edit path. In this paper we propose a new derivative of the edit distance that also takes into consideration the lengths of the two strings, but the new distance is related directly to the edit distance. The particularity of the new distance is that it uses the genetic algorithms to set the values of the parameters it uses. We conduct experiments to test the new distance and we obtain promising results.
Particle Swarm Optimization of Information-Content Weighting of Symbolic Aggregate Approximation
Dec 06, 2013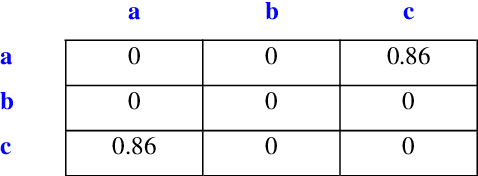
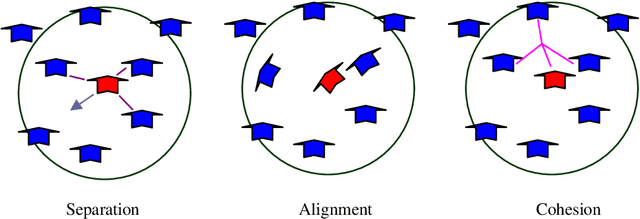
Bio-inspired optimization algorithms have been gaining more popularity recently. One of the most important of these algorithms is particle swarm optimization (PSO). PSO is based on the collective intelligence of a swam of particles. Each particle explores a part of the search space looking for the optimal position and adjusts its position according to two factors; the first is its own experience and the second is the collective experience of the whole swarm. PSO has been successfully used to solve many optimization problems. In this work we use PSO to improve the performance of a well-known representation method of time series data which is the symbolic aggregate approximation (SAX). As with other time series representation methods, SAX results in loss of information when applied to represent time series. In this paper we use PSO to propose a new minimum distance WMD for SAX to remedy this problem. Unlike the original minimum distance, the new distance sets different weights to different segments of the time series according to their information content. This weighted minimum distance enhances the performance of SAX as we show through experiments using different time series datasets.
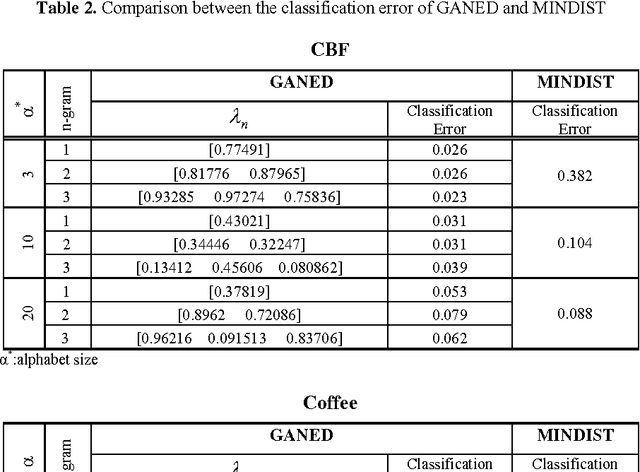
ABC-SG: A New Artificial Bee Colony Algorithm-Based Distance of Sequential Data Using Sigma Grams
Dec 05, 2013
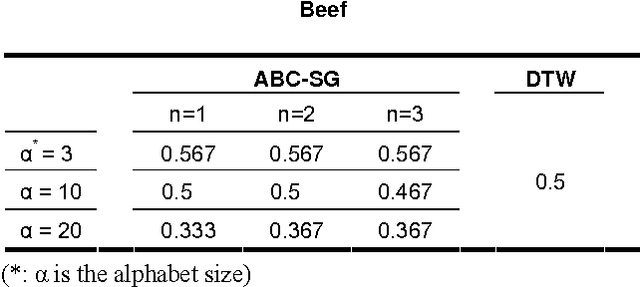
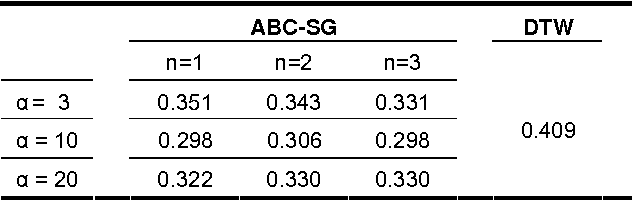
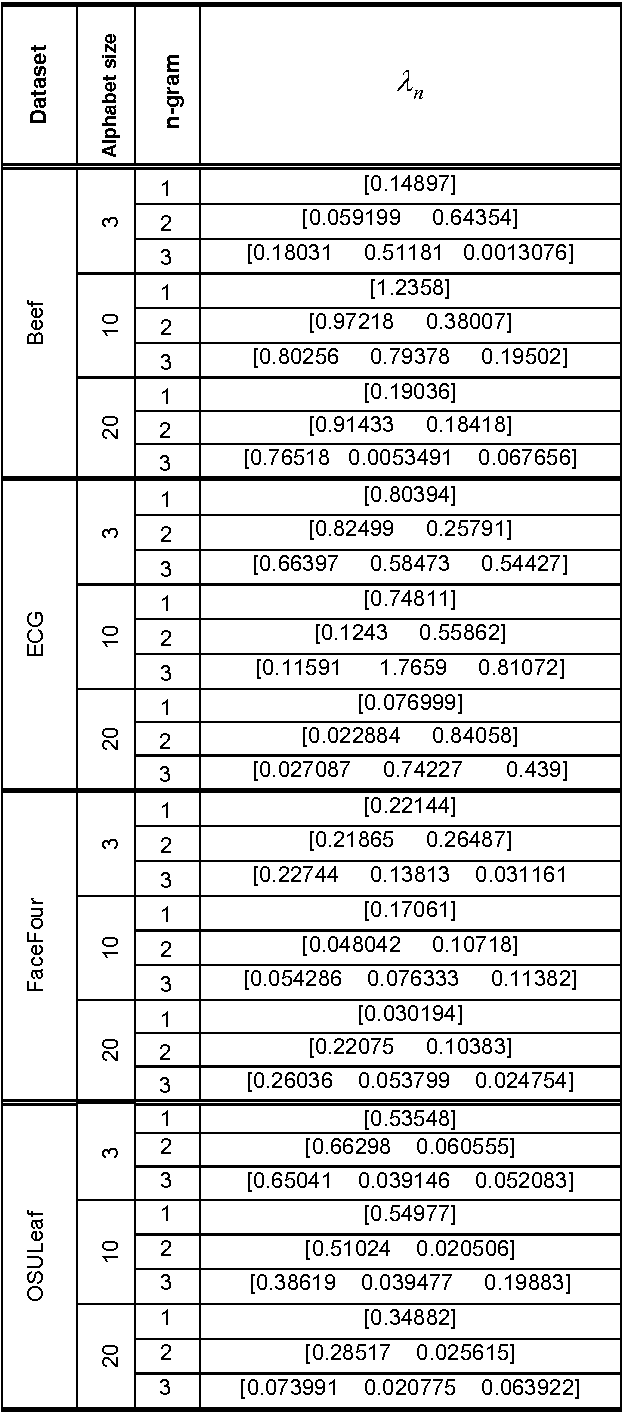
The problem of similarity search is one of the main problems in computer science. This problem has many applications in text-retrieval, web search, computational biology, bioinformatics and others. Similarity between two data objects can be depicted using a similarity measure or a distance metric. There are numerous distance metrics in the literature, some are used for a particular data type, and others are more general. In this paper we present a new distance metric for sequential data which is based on the sum of n-grams. The novelty of our distance is that these n-grams are weighted using artificial bee colony; a recent optimization algorithm based on the collective intelligence of a swarm of bees on their search for nectar. This algorithm has been used in optimizing a large number of numerical problems. We validate the new distance experimentally.