 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of YOLOv12: Attention-Based Enhancements vs. Previous Versions
Apr 16, 2025The YOLO (You Only Look Once) series has been a leading framework in real-time object detection, consistently improving the balance between speed and accuracy. However, integrating attention mechanisms into YOLO has been challenging due to their high computational overhead. YOLOv12 introduces a novel approach that successfully incorporates attention-based enhancements while preserving real-time performance. This paper provides a comprehensive review of YOLOv12's architectural innovations, including Area Attention for computationally efficient self-attention, Residual Efficient Layer Aggregation Networks for improved feature aggregation, and FlashAttention for optimized memory access. Additionally, we benchmark YOLOv12 against prior YOLO versions and competing object detectors, analyzing its improvements in accuracy, inference speed, and computational efficiency. Through this analysis, we demonstrate how YOLOv12 advances real-time object detection by refining the latency-accuracy trade-off and optimizing computational resources.
YOLOv12: A Breakdown of the Key Architectural Features
Feb 20, 2025This paper presents an architectural analysis of YOLOv12, a significant advancement in single-stage, real-time object detection building upon the strengths of its predecessors while introducing key improvements. The model incorporates an optimised backbone (R-ELAN), 7x7 separable convolutions, and FlashAttention-driven area-based attention, improving feature extraction, enhanced efficiency, and robust detections. With multiple model variants, similar to its predecessors, YOLOv12 offers scalable solutions for both latency-sensitive and high-accuracy applications. Experimental results manifest consistent gains in mean average precision (mAP) and inference speed, making YOLOv12 a compelling choice for applications in autonomous systems, security, and real-time analytics. By achieving an optimal balance between computational efficiency and performance, YOLOv12 sets a new benchmark for real-time computer vision, facilitating deployment across diverse hardware platforms, from edge devices to high-performance clusters.
YOLOv11: An Overview of the Key Architectural Enhancements
Oct 23, 2024



This study presents an architectural analysis of YOLOv11, the latest iteration in the YOLO (You Only Look Once) series of object detection models. We examine the models architectural innovations, including the introduction of the C3k2 (Cross Stage Partial with kernel size 2) block, SPPF (Spatial Pyramid Pooling - Fast), and C2PSA (Convolutional block with Parallel Spatial Attention) components, which contribute in improving the models performance in several ways such as enhanced feature extraction. The paper explores YOLOv11's expanded capabilities across various computer vision tasks, including object detection, instance segmentation, pose estimation, and oriented object detection (OBB). We review the model's performance improvements in terms of mean Average Precision (mAP) and computational efficiency compared to its predecessors, with a focus on the trade-off between parameter count and accuracy. Additionally, the study discusses YOLOv11's versatility across different model sizes, from nano to extra-large, catering to diverse application needs from edge devices to high-performance computing environments. Our research provides insights into YOLOv11's position within the broader landscape of object detection and its potential impact on real-time computer vision applications.
A Review of Transformer-Based Models for Computer Vision Tasks: Capturing Global Context and Spatial Relationships
Aug 27, 2024



Transformer-based models have transformed the landscape of natural language processing (NLP) and are increasingly applied to computer vision tasks with remarkable success. These models, renowned for their ability to capture long-range dependencies and contextual information, offer a promising alternative to traditional convolutional neural networks (CNNs) in computer vision. In this review paper, we provide an extensive overview of various transformer architectures adapted for computer vision tasks. We delve into how these models capture global context and spatial relationships in images, empowering them to excel in tasks such as image classification, object detection, and segmentation. Analyzing the key components, training methodologies, and performance metrics of transformer-based models, we highlight their strengths, limitations, and recent advancements. Additionally, we discuss potential research directions and applications of transformer-based models in computer vision, offering insights into their implications for future advancements in the field.
From SAM to SAM 2: Exploring Improvements in Meta's Segment Anything Model
Aug 12, 2024The Segment Anything Model (SAM), introduced to the computer vision community by Meta in April 2023, is a groundbreaking tool that allows automated segmentation of objects in images based on prompts such as text, clicks, or bounding boxes. SAM excels in zero-shot performance, segmenting unseen objects without additional training, stimulated by a large dataset of over one billion image masks. SAM 2 expands this functionality to video, leveraging memory from preceding and subsequent frames to generate accurate segmentation across entire videos, enabling near real-time performance. This comparison shows how SAM has evolved to meet the growing need for precise and efficient segmentation in various applications. The study suggests that future advancements in models like SAM will be crucial for improving computer vision technology.
What is YOLOv5: A deep look into the internal features of the popular object detector
Jul 30, 2024



This study presents a comprehensive analysis of the YOLOv5 object detection model, examining its architecture, training methodologies, and performance. Key components, including the Cross Stage Partial backbone and Path Aggregation-Network, are explored in detail. The paper reviews the model's performance across various metrics and hardware platforms. Additionally, the study discusses the transition from Darknet to PyTorch and its impact on model development. Overall, this research provides insights into YOLOv5's capabilities and its position within the broader landscape of object detection and why it is a popular choice for constrained edge deployment scenarios.
A Comparative Analysis of YOLOv5, YOLOv8, and YOLOv10 in Kitchen Safety
Jul 30, 2024



Knife safety in the kitchen is essential for preventing accidents or injuries with an emphasis on proper handling, maintenance, and storage methods. This research presents a comparative analysis of three YOLO models, YOLOv5, YOLOv8, and YOLOv10, to detect the hazards involved in handling knife, concentrating mainly on ensuring fingers are curled while holding items to be cut and that hands should only be in contact with knife handle avoiding the blade. Precision, recall, F-score, and normalized confusion matrix are used to evaluate the performance of the models. The results indicate that YOLOv5 performed better than the other two models in identifying the hazard of ensuring hands only touch the blade, while YOLOv8 excelled in detecting the hazard of curled fingers while holding items. YOLOv5 and YOLOv8 performed almost identically in recognizing classes such as hand, knife, and vegetable, whereas YOLOv5, YOLOv8, and YOLOv10 accurately identified the cutting board. This paper provides insights into the advantages and shortcomings of these models in real-world settings. Moreover, by detailing the optimization of YOLO architectures for safe knife handling, this study promotes the development of increased accuracy and efficiency in safety surveillance systems.
YOLOv5, YOLOv8 and YOLOv10: The Go-To Detectors for Real-time Vision
Jul 03, 2024This paper presents a comprehensive review of the evolution of the YOLO (You Only Look Once) object detection algorithm, focusing on YOLOv5, YOLOv8, and YOLOv10. We analyze the architectural advancements, performance improvements, and suitability for edge deployment across these versions. YOLOv5 introduced significant innovations such as the CSPDarknet backbone and Mosaic Augmentation, balancing speed and accuracy. YOLOv8 built upon this foundation with enhanced feature extraction and anchor-free detection, improving versatility and performance. YOLOv10 represents a leap forward with NMS-free training, spatial-channel decoupled downsampling, and large-kernel convolutions, achieving state-of-the-art performance with reduced computational overhead. Our findings highlight the progressive enhancements in accuracy, efficiency, and real-time performance, particularly emphasizing their applicability in resource-constrained environments. This review provides insights into the trade-offs between model complexity and detection accuracy, offering guidance for selecting the most appropriate YOLO version for specific edge computing applications.
YOLOv1 to YOLOv10: A comprehensive review of YOLO variants and their application in the agricultural domain
Jun 14, 2024



This survey investigates the transformative potential of various YOLO variants, from YOLOv1 to the state-of-the-art YOLOv10, in the context of agricultural advancements. The primary objective is to elucidate how these cutting-edge object detection models can re-energise and optimize diverse aspects of agriculture, ranging from crop monitoring to livestock management. It aims to achieve key objectives, including the identification of contemporary challenges in agriculture, a detailed assessment of YOLO's incremental advancements, and an exploration of its specific applications in agriculture. This is one of the first surveys to include the latest YOLOv10, offering a fresh perspective on its implications for precision farming and sustainable agricultural practices in the era of Artificial Intelligence and automation. Further, the survey undertakes a critical analysis of YOLO's performance, synthesizes existing research, and projects future trends. By scrutinizing the unique capabilities packed in YOLO variants and their real-world applications, this survey provides valuable insights into the evolving relationship between YOLO variants and agriculture. The findings contribute towards a nuanced understanding of the potential for precision farming and sustainable agricultural practices, marking a significant step forward in the integration of advanced object detection technologies within the agricultural sector.
Diabetic Retinopathy Screening Using Custom-Designed Convolutional Neural Network
Oct 08, 2021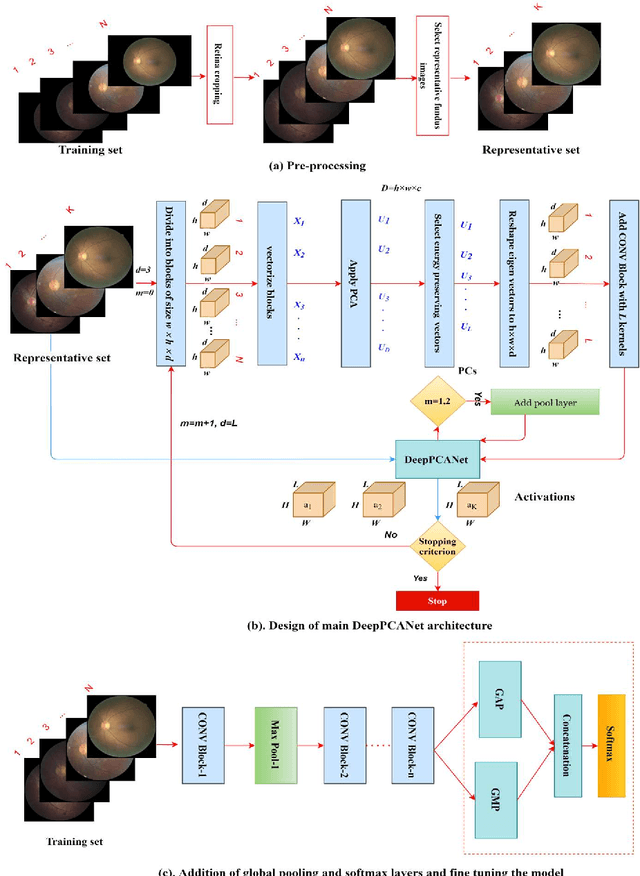
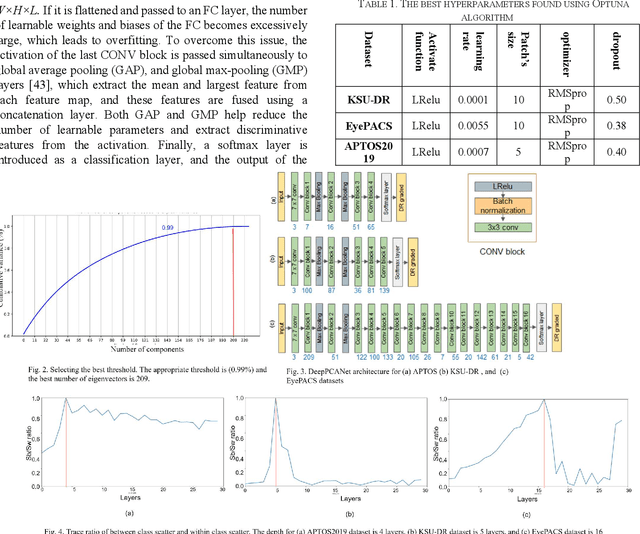
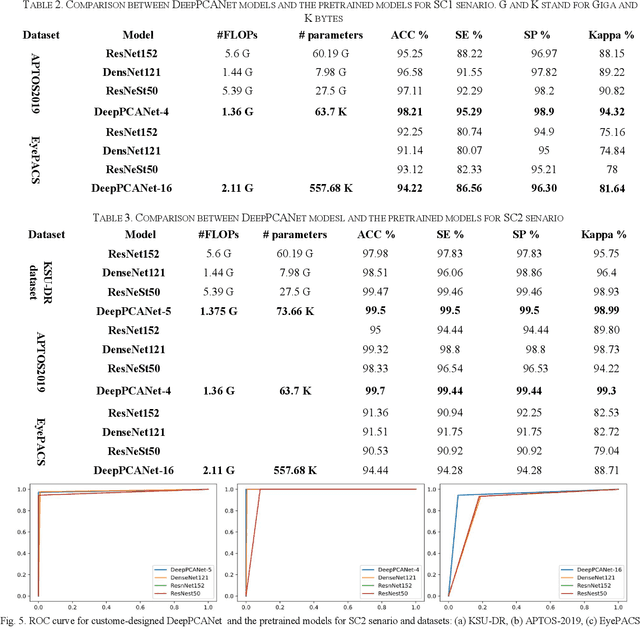
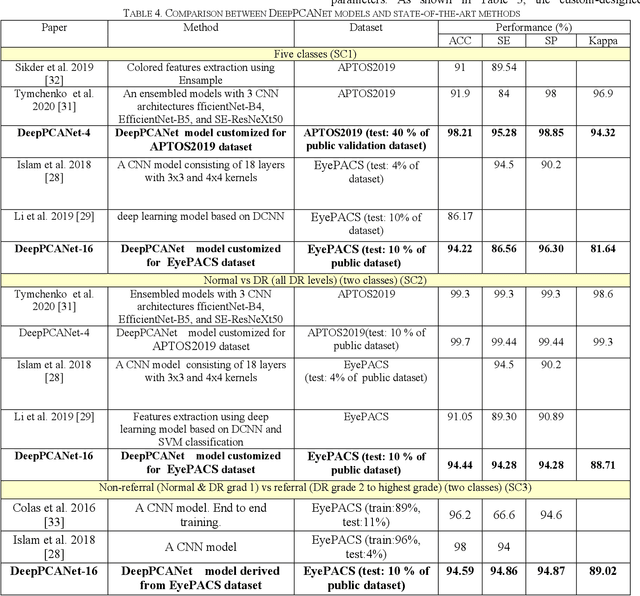
The prevalence of diabetic retinopathy (DR) has reached 34.6% worldwide and is a major cause of blindness among middle-aged diabetic patients. Regular DR screening using fundus photography helps detect its complications and prevent its progression to advanced levels. As manual screening is time-consuming and subjective, machine learning (ML) and deep learning (DL) have been employed to aid graders. However, the existing CNN-based methods use either pre-trained CNN models or a brute force approach to design new CNN models, which are not customized to the complexity of fundus images. To overcome this issue, we introduce an approach for custom-design of CNN models, whose architectures are adapted to the structural patterns of fundus images and better represent the DR-relevant features. It takes the leverage of k-medoid clustering, principal component analysis (PCA), and inter-class and intra-class variations to automatically determine the depth and width of a CNN model. The designed models are lightweight, adapted to the internal structures of fundus images, and encode the discriminative patterns of DR lesions. The technique is validated on a local dataset from King Saud University Medical City, Saudi Arabia, and two challenging benchmark datasets from Kaggle: EyePACS and APTOS2019. The custom-designed models outperform the famous pre-trained CNN models like ResNet152, Densnet121, and ResNeSt50 with a significant decrease in the number of parameters and compete well with the state-of-the-art CNN-based DR screening methods. The proposed approach is helpful for DR screening under diverse clinical settings and referring the patients who may need further assessment and treatment to expert ophthalmologists.