 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal State Space Model For Efficient Event-Based Optical Flow
Jun 09, 2025Event cameras unlock new frontiers that were previously unthinkable with standard frame-based cameras. One notable example is low-latency motion estimation (optical flow), which is critical for many real-time applications. In such applications, the computational efficiency of algorithms is paramount. Although recent deep learning paradigms such as CNN, RNN, or ViT have shown remarkable performance, they often lack the desired computational efficiency. Conversely, asynchronous event-based methods including SNNs and GNNs are computationally efficient; however, these approaches fail to capture sufficient spatio-temporal information, a powerful feature required to achieve better performance for optical flow estimation. In this work, we introduce Spatio-Temporal State Space Model (STSSM) module along with a novel network architecture to develop an extremely efficient solution with competitive performance. Our STSSM module leverages state-space models to effectively capture spatio-temporal correlations in event data, offering higher performance with lower complexity compared to ViT, CNN-based architectures in similar settings. Our model achieves 4.5x faster inference and 8x lower computations compared to TMA and 2x lower computations compared to EV-FlowNet with competitive performance on the DSEC benchmark. Our code will be available at https://github.com/AhmedHumais/E-STMFlow
EV-LayerSegNet: Self-supervised Motion Segmentation using Event Cameras
Jun 07, 2025Event cameras are novel bio-inspired sensors that capture motion dynamics with much higher temporal resolution than traditional cameras, since pixels react asynchronously to brightness changes. They are therefore better suited for tasks involving motion such as motion segmentation. However, training event-based networks still represents a difficult challenge, as obtaining ground truth is very expensive, error-prone and limited in frequency. In this article, we introduce EV-LayerSegNet, a self-supervised CNN for event-based motion segmentation. Inspired by a layered representation of the scene dynamics, we show that it is possible to learn affine optical flow and segmentation masks separately, and use them to deblur the input events. The deblurring quality is then measured and used as self-supervised learning loss. We train and test the network on a simulated dataset with only affine motion, achieving IoU and detection rate up to 71% and 87% respectively.
Analysis of the Effect of Time Delay for Unmanned Aerial Vehicles with Applications to Vision Based Navigation
Sep 05, 2022
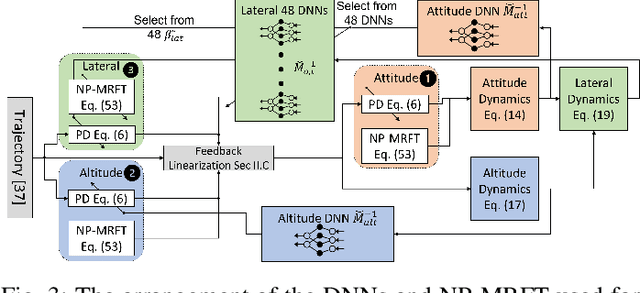
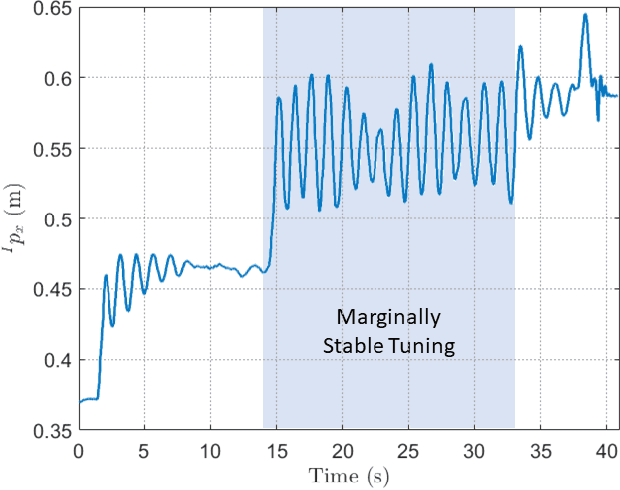
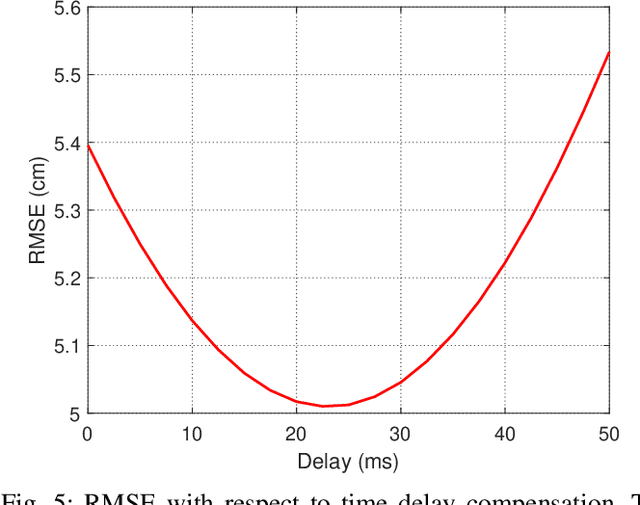
In this paper, we analyze the effect of time delay dynamics on controller design for Unmanned Aerial Vehicles (UAVs) with vision based navigation. Time delay is an inevitable phenomenon in cyber-physical systems, and has important implications on controller design and trajectory generation for UAVs. The impact of time delay on UAV dynamics increases with the use of the slower vision based navigation stack. We show that the existing models in the literature, which exclude time delay, are unsuitable for controller tuning since a trivial solution for minimizing an error cost functional always exists. The trivial solution that we identify suggests use of infinite controller gains to achieve optimal performance, which contradicts practical findings. We avoid such shortcomings by introducing a novel nonlinear time delay model for UAVs, and then obtain a set of linear decoupled models corresponding to each of the UAV control loops. The cost functional of the linearized time delay model of angular and altitude dynamics is analyzed, and in contrast to the delay-free models, we show the existence of finite optimal controller parameters. Due to the use of time delay models, we experimentally show that the proposed model accurately represents system stability limits. Due to time delay consideration, we achieved a tracking results of RMSE 5.01 cm when tracking a lemniscate trajectory with a peak velocity of 2.09 m/s using visual odometry (VO) based UAV navigation, which is on par with the state-of-the-art.