 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Reflection in Pre-Training
Apr 05, 2025



A language model's ability to reflect on its own reasoning provides a key advantage for solving complex problems. While most recent research has focused on how this ability develops during reinforcement learning, we show that it actually begins to emerge much earlier - during the model's pre-training. To study this, we introduce deliberate errors into chains-of-thought and test whether the model can still arrive at the correct answer by recognizing and correcting these mistakes. By tracking performance across different stages of pre-training, we observe that this self-correcting ability appears early and improves steadily over time. For instance, an OLMo2-7B model pre-trained on 4 trillion tokens displays self-correction on our six self-reflection tasks.
Position Masking for Language Models
Jun 02, 2020
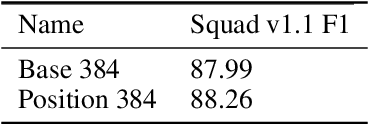
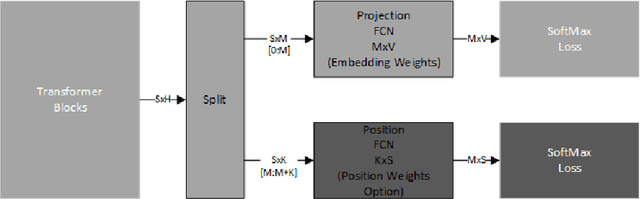

Masked language modeling (MLM) pre-training models such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. This is an effective technique which has led to good results on all NLP benchmarks. We propose to expand upon this idea by masking the positions of some tokens along with the masked input token ids. We follow the same standard approach as BERT masking a percentage of the tokens positions and then predicting their original values using an additional fully connected classifier stage. This approach has shown good performance gains (.3\% improvement) for the SQUAD additional improvement in convergence times. For the Graphcore IPU the convergence of BERT Base with position masking requires only 50\% of the tokens from the original BERT paper.