 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabGlossBERT: Fine-Tuning BERT on Context-Gloss Pairs for WSD
May 19, 2022

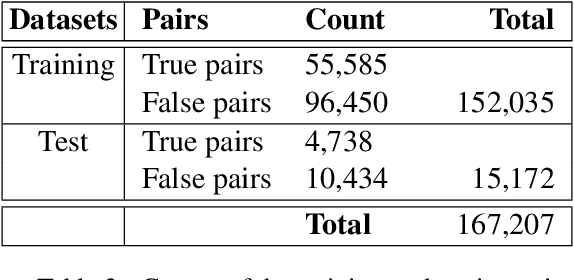

Using pre-trained transformer models such as BERT has proven to be effective in many NLP tasks. This paper presents our work to fine-tune BERT models for Arabic Word Sense Disambiguation (WSD). We treated the WSD task as a sentence-pair binary classification task. First, we constructed a dataset of labeled Arabic context-gloss pairs (~167k pairs) we extracted from the Arabic Ontology and the large lexicographic database available at Birzeit University. Each pair was labeled as True or False and target words in each context were identified and annotated. Second, we used this dataset for fine-tuning three pre-trained Arabic BERT models. Third, we experimented the use of different supervised signals used to emphasize target words in context. Our experiments achieved promising results (accuracy of 84%) although we used a large set of senses in the experiment.
LU-BZU at SemEval-2021 Task 2: Word2Vec and Lemma2Vec performance in Arabic Word-in-Context disambiguation
Apr 16, 2021
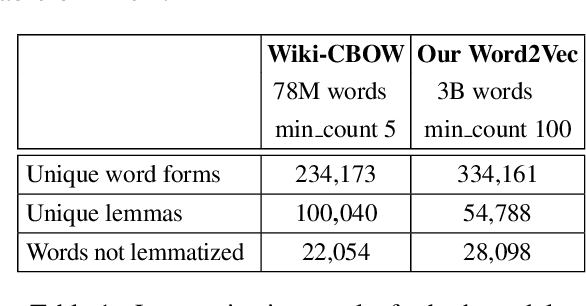
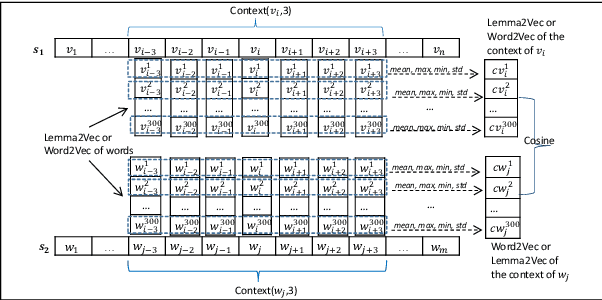
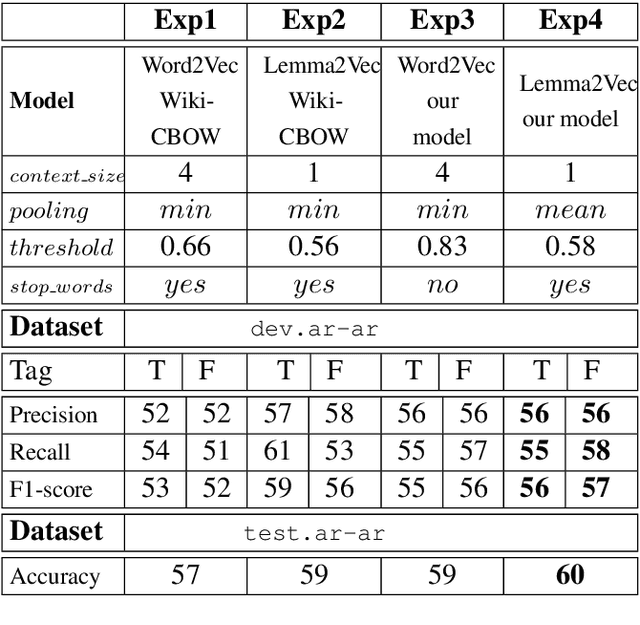
This paper presents a set of experiments to evaluate and compare between the performance of using CBOW Word2Vec and Lemma2Vec models for Arabic Word-in-Context (WiC) disambiguation without using sense inventories or sense embeddings. As part of the SemEval-2021 Shared Task 2 on WiC disambiguation, we used the dev.ar-ar dataset (2k sentence pairs) to decide whether two words in a given sentence pair carry the same meaning. We used two Word2Vec models: Wiki-CBOW, a pre-trained model on Arabic Wikipedia, and another model we trained on large Arabic corpora of about 3 billion tokens. Two Lemma2Vec models was also constructed based on the two Word2Vec models. Each of the four models was then used in the WiC disambiguation task, and then evaluated on the SemEval-2021 test.ar-ar dataset. At the end, we reported the performance of different models and compared between using lemma-based and word-based models.
Automatic Identification of Arabic expressions related to future events in Lebanon's economy
May 29, 2018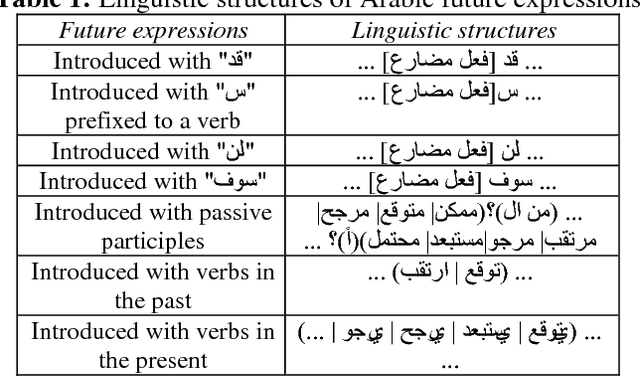
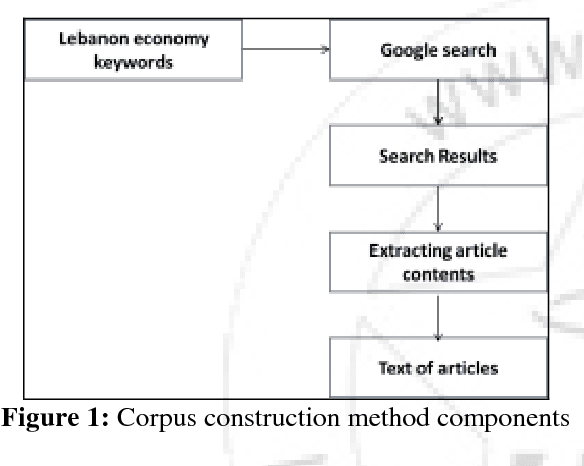


In this paper, we propose a method to automatically identify future events in Lebanon's economy from Arabic texts. Challenges are threefold: first, we need to build a corpus of Arabic texts that covers Lebanon's economy; second, we need to study how future events are expressed linguistically in these texts; and third, we need to automatically identify the relevant textual segments accordingly. We will validate this method on a constructed corpus form the web and show that it has very promising results. To do so, we will be using SLCSAS, a system for semantic analysis, based on the Contextual Explorer method, and "AlKhalil Morpho Sys" system for morpho-syntactic analysis.
* 5 pages
Automatic Annotation of Locative and Directional Expressions in Arabic
May 26, 2018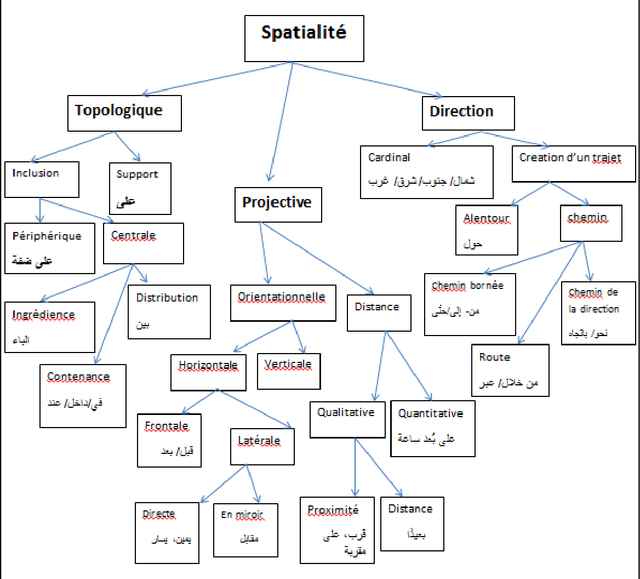
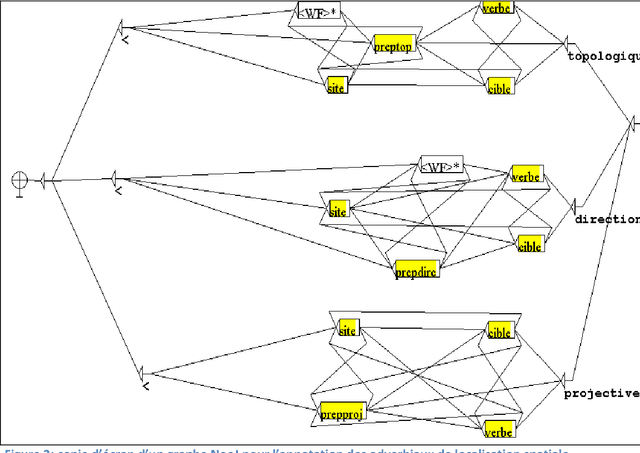
In this paper, we introduce a rule-based approach to annotate Locative and Directional Expressions in Arabic natural language text. The annotation is based on a constructed semantic map of the spatiality domain. Challenges are twofold: first, we need to study how locative and directional expressions are expressed linguistically in these texts; and second, we need to automatically annotate the relevant textual segments accordingly. The research method we will use in this article is analytic-descriptive. We will validate this approach on specific novel rich with these expressions and show that it has very promising results. We will be using NOOJ as a software tool to implement finite-state transducers to annotate linguistic elements according to Locative and Directional Expressions. In conclusion, NOOJ allowed us to write linguistic rules for the automatic annotation in Arabic text of Locative and Directional Expressions.