 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Pixelwise Object Labeling for Aerial Imagery Using Stacked U-Nets
Mar 13, 2018
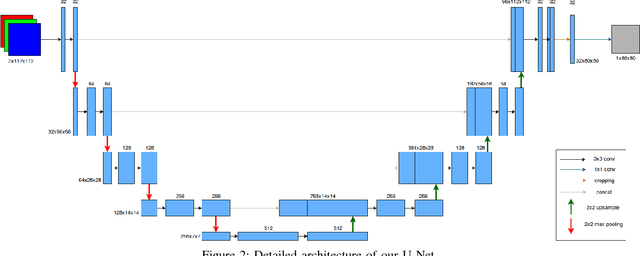


Automation of objects labeling in aerial imagery is a computer vision task with numerous practical applications. Fields like energy exploration require an automated method to process a continuous stream of imagery on a daily basis. In this paper we propose a pipeline to tackle this problem using a stack of convolutional neural networks (U-Net architecture) arranged end-to-end. Each network works as post-processor to the previous one. Our model outperforms current state-of-the-art on two different datasets: Inria Aerial Image Labeling dataset and Massachusetts Buildings dataset each with different characteristics such as spatial resolution, object shapes and scales. Moreover, we experimentally validate computation time savings by processing sub-sampled images and later upsampling pixelwise labeling. These savings come at a negligible degradation in segmentation quality. Though the conducted experiments in this paper cover only aerial imagery, the technique presented is general and can handle other types of images.
Facial Expression Recognition in the Wild using Rich Deep Features
Jan 11, 2016


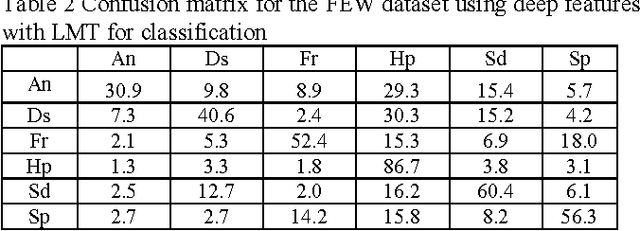
Facial Expression Recognition is an active area of research in computer vision with a wide range of applications. Several approaches have been developed to solve this problem for different benchmark datasets. However, Facial Expression Recognition in the wild remains an area where much work is still needed to serve real-world applications. To this end, in this paper we present a novel approach towards facial expression recognition. We fuse rich deep features with domain knowledge through encoding discriminant facial patches. We conduct experiments on two of the most popular benchmark datasets; CK and TFE. Moreover, we present a novel dataset that, unlike its precedents, consists of natural - not acted - expression images. Experimental results show that our approach achieves state-of-the-art results over standard benchmarks and our own dataset