 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiming Fragility Aware Selective Hardening of RISCV Soft Processors on SRAM Based FPGAs
Jan 09, 2026Selective hardening is widely employed to improve the reliability of FPGA based soft processors while limiting the overhead of full redundancy. However, existing approaches primarily rely on architectural criticality or functional fault analysis, overlooking the impact of routing dependent timing sensitivity on processor robustness. This paper introduces a timing fragility aware selective hardening methodology for RISCV soft processors implemented on SRAM based FPGAs. Building on recent advances in in situ timing observability, the proposed approach quantifies the statistical timing sensitivity of pipeline components under controlled routing perturbations and uses this information to guide hardening decisions. Experimental results on a RISCV processor implemented on a commercial FPGA platform show that components exhibiting higher timing fragility also demonstrate increased vulnerability to routing induced delay effects. Leveraging this correlation, the proposed selective hardening strategy achieves robustness comparable to full hardening while significantly reducing area and timing overhead. These results demonstrate that timing fragility provides a practical and effective metric for reliability aware design optimization in FPGA based processor architectures.
Pipeline Stage Resolved Timing Characterization of FPGA and ASIC Implementations of a RISC V Processor
Dec 17, 2025



This paper presents a pipeline stage resolved timing characterization of a 32-bit RISC V processor implemented on a 20 nm FPGA and a 7 nm FinFET ASIC platform. A unified analysis framework is introduced that decomposes timing paths into logic, routing, and clocking components and maps them to well-defined pipeline stage transitions. This approach enables systematic comparison of timing behavior across heterogeneous implementation technologies at a microarchitectural level. Using static timing analysis and statistical characterization, the study shows that although both implementations exhibit dominant critical paths in the EX to MEM pipeline transition, their underlying timing mechanisms differ fundamentally. FPGA timing is dominated by routing parasitics and placement dependent variability, resulting in wide slack distributions and sensitivity to routing topology. In contrast, ASIC timing is governed primarily by combinational logic depth and predictable parametric variation across process, voltage, and temperature corners, yielding narrow and stable timing distributions. The results provide quantitative insight into the structural origins of timing divergence between programmable and custom fabrics and demonstrate the effectiveness of pipeline stage resolved analysis for identifying platform specific bottlenecks. Based on these findings, the paper derives design implications for achieving predictable timing closure in processor architectures targeting both FPGA and ASIC implementations.
A Hybrid Residue Floating Numerical Architecture for High Precision Arithmetic on FPGAs
Dec 09, 2025Floating point arithmetic remains expensive on FPGA platforms due to wide datapaths and normalization logic, motivating alternative representations that preserve dynamic range at lower cost. This work introduces the Hybrid Residue Floating Numerical Architecture (HRFNA), a unified arithmetic system that combines carry free residue channels with a lightweight floating point scaling factor. We develop the full mathematical framework, derive bounded error normalization rules, and present FPGA optimized microarchitectures for modular multiplication, exponent management, and hybrid reconstruction. HRFNA is implemented on a Xilinx ZCU104, with Vitis simulation, RTL synthesis, and on chip ILA traces confirming cycle accurate correctness. The architecture achieves over 2.1 times throughput improvement and 38-52 percent LUT reduction compared to IEEE 754 single precision baselines while maintaining numerical stability across long iterative sequences. These results demonstrate that HRFNA offers an efficient and scalable alternative to floating point computation on modern FPGA devices.
Practical Timing Closure in FPGA and ASIC Designs: Methods, Challenges, and Case Studies
Oct 30, 2025This paper presents an in-depth analysis of timing closure challenges and constraints in Field Programmable Gate Arrays (FPGAs) and Application Specific Integrated Circuits (ASICs). We examine core timing principles, architectural distinctions, and design methodologies influencing timing behavior in both technologies. A case study comparing the Xilinx Kintex UltraScale+ FPGA (XCKU040) with a 7nm ASIC highlights practical timing analysis and performance trade-offs. Experimental results show ASICs achieve superior timing of 45ps setup and 35ps hold, while modern FPGAs remain competitive with 180ps setup and 120ps hold times, validating their suitability for high-performance designs.
Fault-Resilient PCIe Bus with Real-time Error Detection and Correction
May 12, 2021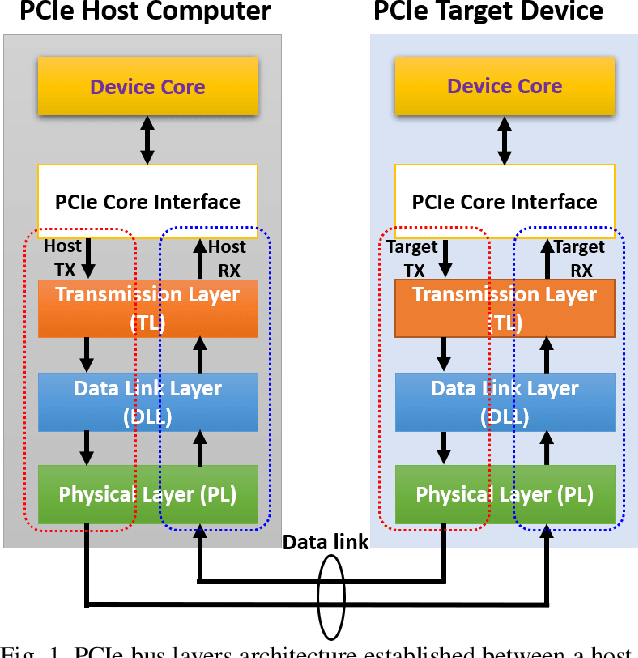

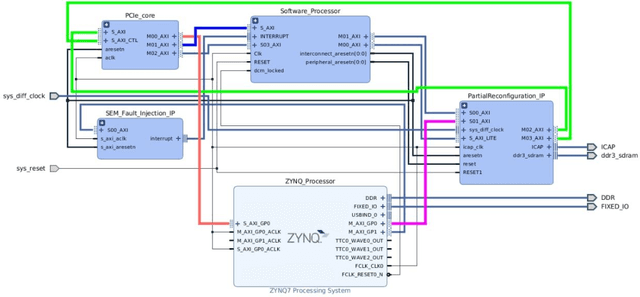
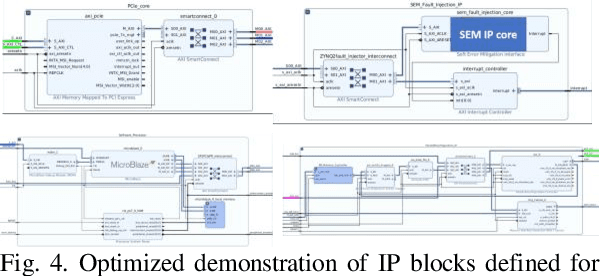
This paper presents a novel IP design for real-time fault/error detection and recovery on a peripheral component interconnect express (PCIe) which interfaces a host system (here a PC) to a slave design including processing system and memory transaction implemented on a Zynq Ultrascale Xilinx Kintex FPGA board (KCU105). The proposed IP design is capable of detection and correction of different types of PCIe errors on-the-fly
Linear and Nonlinear Identification of Dryer System Using Artificial Intelligence and Neural Networks
Nov 16, 2018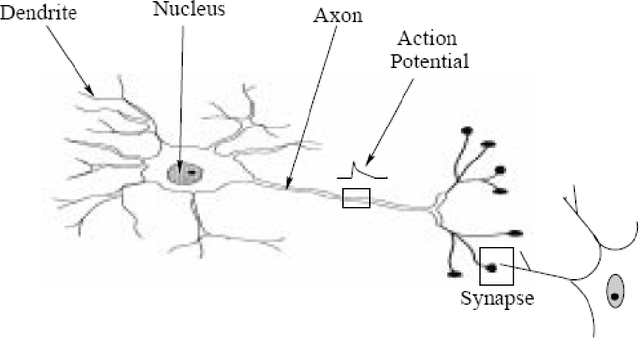
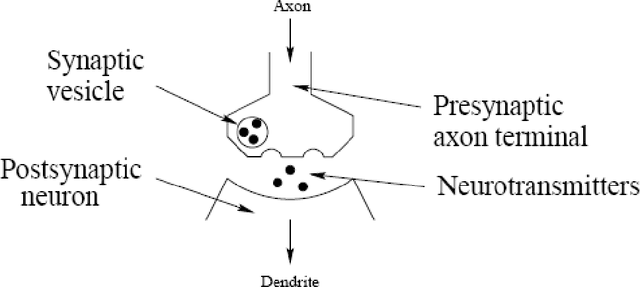
As you read these words you are using a complex biological neural network. You have a highly interconnected set of some neurons to facilitate your reading, breathing, motion and thinking. Each of your biological neurons, a rich assembly of tissue and chemistry, has the complexity, if not the speed, of a microprocessor. Some of your neural structure was with you at birth. Other parts have been established by experience.