 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactical Decision Making for Autonomous Trucks by Deep Reinforcement Learning with Total Cost of Operation Based Reward
Mar 11, 2024



We develop a deep reinforcement learning framework for tactical decision making in an autonomous truck, specifically for Adaptive Cruise Control (ACC) and lane change maneuvers in a highway scenario. Our results demonstrate that it is beneficial to separate high-level decision-making processes and low-level control actions between the reinforcement learning agent and the low-level controllers based on physical models. In the following, we study optimizing the performance with a realistic and multi-objective reward function based on Total Cost of Operation (TCOP) of the truck using different approaches; by adding weights to reward components, by normalizing the reward components and by using curriculum learning techniques.
Tree Ensembles for Contextual Bandits
Feb 10, 2024



We propose a novel framework for contextual multi-armed bandits based on tree ensembles. Our framework integrates two widely used bandit methods, Upper Confidence Bound and Thompson Sampling, for both standard and combinatorial settings. We demonstrate the effectiveness of our framework via several experimental studies, employing XGBoost, a popular tree ensemble method. Compared to state-of-the-art methods based on neural networks, our methods exhibit superior performance in terms of both regret minimization and computational runtime, when applied to benchmark datasets and the real-world application of navigation over road networks.
Effective Acquisition Functions for Active Correlation Clustering
Feb 05, 2024Correlation clustering is a powerful unsupervised learning paradigm that supports positive and negative similarities. In this paper, we assume the similarities are not known in advance. Instead, we employ active learning to iteratively query similarities in a cost-efficient way. In particular, we develop three effective acquisition functions to be used in this setting. One is based on the notion of inconsistency (i.e., when similarities violate the transitive property). The remaining two are based on information-theoretic quantities, i.e., entropy and information gain.
Combinatorial Gaussian Process Bandits in Bayesian Settings: Theory and Application for Energy-Efficient Navigation
Dec 20, 2023



We consider a combinatorial Gaussian process semi-bandit problem with time-varying arm availability. Each round, an agent is provided a set of available base arms and must select a subset of them to maximize the long-term cumulative reward. Assuming the expected rewards are sampled from a Gaussian process (GP) over the arm space, the agent can efficiently learn. We study the Bayesian setting and provide novel Bayesian regret bounds for three GP-based algorithms: GP-UCB, Bayes-GP-UCB and GP-TS. Our bounds extend previous results for GP-UCB and GP-TS to a combinatorial setting with varying arm availability and to the best of our knowledge, we provide the first Bayesian regret bound for Bayes-GP-UCB. Time-varying arm availability encompasses other widely considered bandit problems such as contextual bandits. We formulate the online energy-efficient navigation problem as a combinatorial and contextual bandit and provide a comprehensive experimental study on synthetic and real-world road networks with detailed simulations. The contextual GP model obtains lower regret and is less dependent on the informativeness of the prior compared to the non-contextual Bayesian inference model. In addition, Thompson sampling obtains lower regret than Bayes-UCB for both the contextual and non-contextual model.
Cost-Efficient Online Decision Making: A Combinatorial Multi-Armed Bandit Approach
Aug 21, 2023
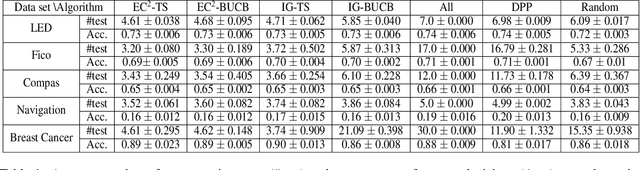
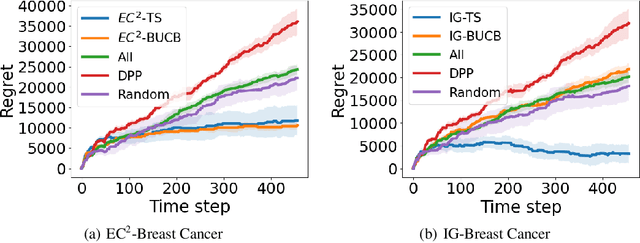
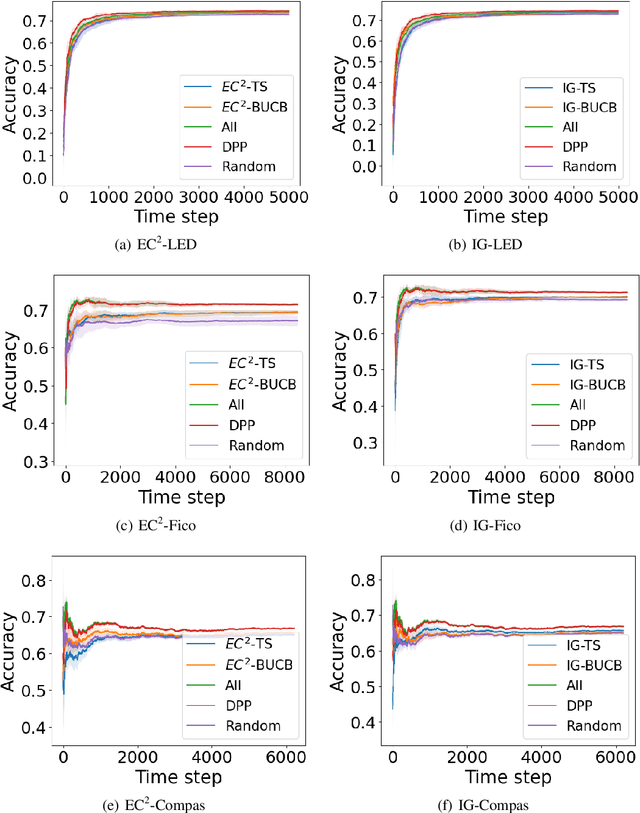
Online decision making plays a crucial role in numerous real-world applications. In many scenarios, the decision is made based on performing a sequence of tests on the incoming data points. However, performing all tests can be expensive and is not always possible. In this paper, we provide a novel formulation of the online decision making problem based on combinatorial multi-armed bandits and take the cost of performing tests into account. Based on this formulation, we provide a new framework for cost-efficient online decision making which can utilize posterior sampling or BayesUCB for exploration. We provide a rigorous theoretical analysis for our framework and present various experimental results that demonstrate its applicability to real-world problems.
Efficient Online Decision Tree Learning with Active Feature Acquisition
May 03, 2023



Constructing decision trees online is a classical machine learning problem. Existing works often assume that features are readily available for each incoming data point. However, in many real world applications, both feature values and the labels are unknown a priori and can only be obtained at a cost. For example, in medical diagnosis, doctors have to choose which tests to perform (i.e., making costly feature queries) on a patient in order to make a diagnosis decision (i.e., predicting labels). We provide a fresh perspective to tackle this practical challenge. Our framework consists of an active planning oracle embedded in an online learning scheme for which we investigate several information acquisition functions. Specifically, we employ a surrogate information acquisition function based on adaptive submodularity to actively query feature values with a minimal cost, while using a posterior sampling scheme to maintain a low regret for online prediction. We demonstrate the efficiency and effectiveness of our framework via extensive experiments on various real-world datasets. Our framework also naturally adapts to the challenging setting of online learning with concept drift and is shown to be competitive with baseline models while being more flexible.
A Unified Active Learning Framework for Annotating Graph Data with Application to Software Source Code Performance Prediction
Apr 06, 2023



Most machine learning and data analytics applications, including performance engineering in software systems, require a large number of annotations and labelled data, which might not be available in advance. Acquiring annotations often requires significant time, effort, and computational resources, making it challenging. We develop a unified active learning framework, specializing in software performance prediction, to address this task. We begin by parsing the source code to an Abstract Syntax Tree (AST) and augmenting it with data and control flow edges. Then, we convert the tree representation of the source code to a Flow Augmented-AST graph (FA-AST) representation. Based on the graph representation, we construct various graph embeddings (unsupervised and supervised) into a latent space. Given such an embedding, the framework becomes task agnostic since active learning can be performed using any regression method and query strategy suited for regression. Within this framework, we investigate the impact of using different levels of information for active and passive learning, e.g., partially available labels and unlabeled test data. Our approach aims to improve the investment in AI models for different software performance predictions (execution time) based on the structure of the source code. Our real-world experiments reveal that respectable performance can be achieved by querying labels for only a small subset of all the data.
Utilizing Reinforcement Learning for de novo Drug Design
Mar 30, 2023Deep learning-based approaches for generating novel drug molecules with specific properties have gained a lot of interest in the last years. Recent studies have demonstrated promising performance for string-based generation of novel molecules utilizing reinforcement learning. In this paper, we develop a unified framework for using reinforcement learning for de novo drug design, wherein we systematically study various on- and off-policy reinforcement learning algorithms and replay buffers to learn an RNN-based policy to generate novel molecules predicted to be active against the dopamine receptor DRD2. Our findings suggest that it is advantageous to use at least both top-scoring and low-scoring molecules for updating the policy when structural diversity is essential. Using all generated molecules at an iteration seems to enhance performance stability for on-policy algorithms. In addition, when replaying high, intermediate, and low-scoring molecules, off-policy algorithms display the potential of improving the structural diversity and number of active molecules generated, but possibly at the cost of a longer exploration phase. Our work provides an open-source framework enabling researchers to investigate various reinforcement learning methods for de novo drug design.
Prediction of Time and Distance of Trips Using Explainable Attention-based LSTMs
Mar 27, 2023In this paper, we propose machine learning solutions to predict the time of future trips and the possible distance the vehicle will travel. For this prediction task, we develop and investigate four methods. In the first method, we use long short-term memory (LSTM)-based structures specifically designed to handle multi-dimensional historical data of trip time and distances simultaneously. Using it, we predict the future trip time and forecast the distance a vehicle will travel by concatenating the outputs of LSTM networks through fully connected layers. The second method uses attention-based LSTM networks (At-LSTM) to perform the same tasks. The third method utilizes two LSTM networks in parallel, one for forecasting the time of the trip and the other for predicting the distance. The output of each LSTM is then concatenated through fully connected layers. Finally, the last model is based on two parallel At-LSTMs, where similarly, each At-LSTM predicts time and distance separately through fully connected layers. Among the proposed methods, the most advanced one, i.e., parallel At-LSTM, predicts the next trip's distance and time with 3.99% error margin where it is 23.89% better than LSTM, the first method. We also propose TimeSHAP as an explainability method for understanding how the networks perform learning and model the sequence of information.
Active Learning with Positive and Negative Pairwise Feedback
Feb 22, 2023



In this paper, we propose a generic framework for active clustering with queries for pairwise similarities between objects. First, the pairwise similarities can be any positive or negative number, yielding full flexibility in the type of feedback that a user/annotator can provide. Second, the process of querying pairwise similarities is separated from the clustering algorithm, leading to more flexibility in how the query strategies can be constructed. Third, the queries are robust to noise by allowing multiple queries for the same pairwise similarity (i.e., a non-persistent noise model is assumed). Finally, the number of clusters is automatically identified based on the currently known pairwise similarities. In addition, we propose and analyze a number of novel query strategies suited to this active clustering framework. We demonstrate the effectiveness of our framework and the proposed query strategies via several experimental studies.