 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking Superspreaders: Data-Driven Approaches for Identifying and Comparing Key Influencers of Conspiracy Theories on X.com
Feb 04, 2026Conspiracy theories can threaten society by spreading misinformation, deepening polarization, and eroding trust in democratic institutions. Social media often fuels the spread of conspiracies, primarily driven by two key actors: Superspreaders -- influential individuals disseminating conspiracy content at disproportionately high rates, and Bots -- automated accounts designed to amplify conspiracies strategically. To counter the spread of conspiracy theories, it is critical to both identify these actors and to better understand their behavior. However, a systematic analysis of these actors as well as real-world-applicable identification methods are still lacking. In this study, we leverage over seven million tweets from the COVID-19 pandemic to analyze key differences between Human Superspreaders and Bots across dimensions such as linguistic complexity, toxicity, and hashtag usage. Our analysis reveals distinct communication strategies: Superspreaders tend to use more complex language and substantive content while relying less on structural elements like hashtags and emojis, likely to enhance credibility and authority. By contrast, Bots favor simpler language and strategic cross-usage of hashtags, likely to increase accessibility, facilitate infiltration into trending discussions, and amplify reach. To counter both Human Superspreaders and Bots, we propose and evaluate 27 novel metrics for quantifying the severity of conspiracy theory spread. Our findings highlight the effectiveness of an adapted H-Index for computationally feasible identification of Human Superspreaders. By identifying behavioral patterns unique to Human Superspreaders and Bots as well as providing suitable identification methods, this study provides a foundation for mitigation strategies, including platform moderation policies, temporary and permanent account suspensions, and public awareness campaigns.
Locating disparities in machine learning
Aug 13, 2022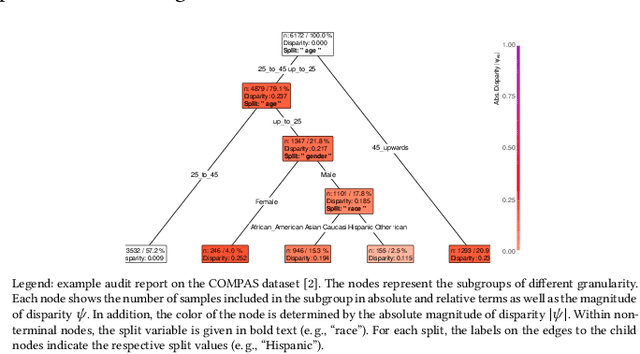

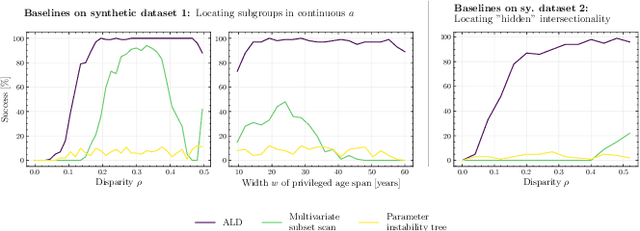

Machine learning was repeatedly proven to provide predictions with disparate outcomes, in which subgroups of the population (e.g., defined by age, gender, or other sensitive attributes) are systematically disadvantaged. Previous literature has focused on detecting such disparities through statistical procedures for when the sensitive attribute is specified a priori. However, this limits applicability in real-world settings where datasets are high dimensional and, on top of that, sensitive attributes may be unknown. As a remedy, we propose a data-driven framework called Automatic Location of Disparities (ALD) which aims at locating disparities in machine learning. ALD meets several demands from machine learning practice: ALD (1) is applicable to arbitrary machine learning classifiers; (2) operates on different definitions of disparities (e.g., statistical parity or equalized odds); (3) deals with both categorical and continuous predictors; (4) is suitable to handle high-dimensional settings; and (5) even identifies disparities due to intersectionality where disparities arise from complex and multi-way interactions (e.g., age above 60 and female). ALD produces interpretable fairness reports as output. We demonstrate the effectiveness of ALD based on both synthetic and real-world datasets. As a result, ALD helps practitioners and researchers of algorithmic fairness to detect disparities in machine learning algorithms, so that disparate -- or even unfair -- outcomes can be mitigated. Moreover, ALD supports practitioners in conducting algorithmic audits and protecting individuals from discrimination.