 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase-Scheduled Multi-Agent Systems for Token-Efficient Coordination
Apr 19, 2026Multi-agent systems (MAS) powered by large language models suffer from severe token inefficiency arising from two compounding sources: (i) unstructured parallel execution, where all agents activate simultaneously irrespective of input readiness; and (ii) unrestricted context sharing, where every agent receives the full accumulated context regardless of relevance. Existing mitigation strategies - static pruning, hierarchical decomposition, and learned routing - treat coordination as a structural allocation problem and fundamentally ignore its temporal dimension. We propose Phase-Scheduled Multi-Agent Systems (PSMAS), a framework that reconceptualizes agent activation as continuous control over a shared attention space modeled on a circular manifold. Each agent i is assigned a fixed angular phase theta_i in the range [0, 2*pi], derived from the task dependency topology; a global sweep signal phi(t) rotates at velocity omega, activating only agents within an angular window epsilon. Idle agents receive compressed context summaries, reducing per-step token consumption. We implement PSMAS on LangGraph, evaluate on four structured benchmarks (HotPotQA-MAS, HumanEval-MAS, ALFWorld-Multi, WebArena-Coord) and two unstructured conversational settings, and prove stability, convergence, and optimality results for the sweep dynamics. PSMAS achieves a mean token reduction of 27.3 percent (range 21.4-34.8 percent) while maintaining task performance within 2.1 percentage points of a fully activated baseline (p < 0.01, n = 500 per configuration), and outperforms the strongest learned routing baseline by 5.6 percentage points in token reduction with 2.0 percentage points less performance drop. Crucially, we show that scheduling and compression are independent sources of gain: scheduling alone accounts for 18-20 percentage points of reduction, robust to compression degradation up to alpha = 0.40.
Does Phase Matter For Monaural Source Separation?
Nov 02, 2017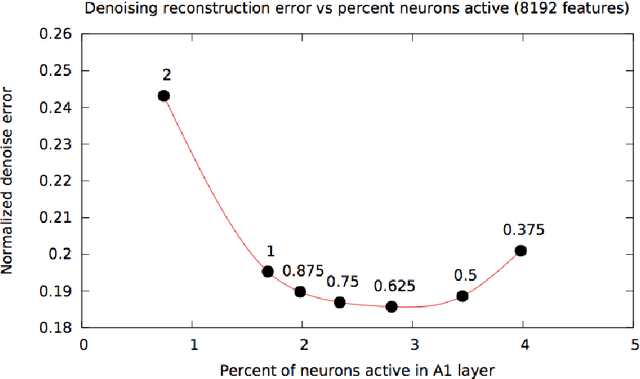
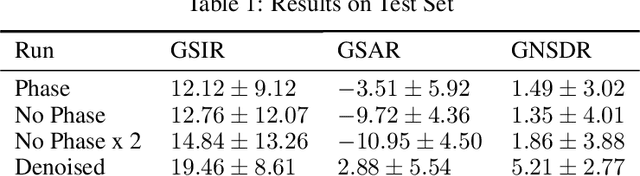
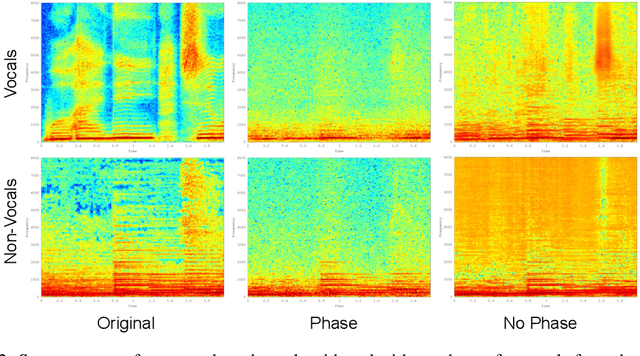
The "cocktail party" problem of fully separating multiple sources from a single channel audio waveform remains unsolved. Current biological understanding of neural encoding suggests that phase information is preserved and utilized at every stage of the auditory pathway. However, current computational approaches primarily discard phase information in order to mask amplitude spectrograms of sound. In this paper, we seek to address whether preserving phase information in spectral representations of sound provides better results in monaural separation of vocals from a musical track by using a neurally plausible sparse generative model. Our results demonstrate that preserving phase information reduces artifacts in the separated tracks, as quantified by the signal to artifact ratio (GSAR). Furthermore, our proposed method achieves state-of-the-art performance for source separation, as quantified by a mean signal to interference ratio (GSIR) of 19.46.