 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Data Size in Probing Fine-tuned Models
Mar 17, 2022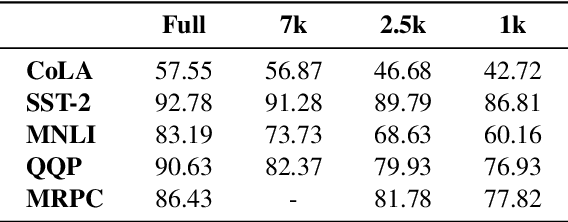
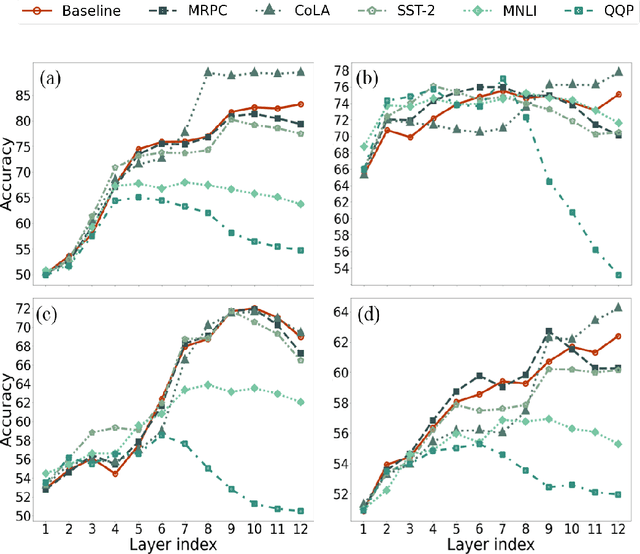
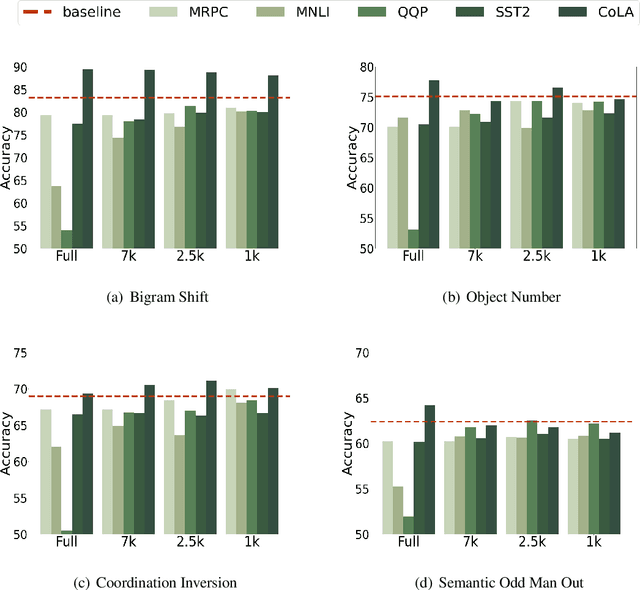
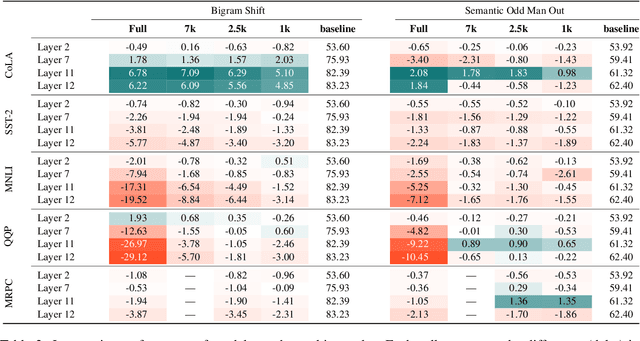
Several studies have investigated the reasons behind the effectiveness of fine-tuning, usually through the lens of probing. However, these studies often neglect the role of the size of the dataset on which the model is fine-tuned. In this paper, we highlight the importance of this factor and its undeniable role in probing performance. We show that the extent of encoded linguistic knowledge depends on the number of fine-tuning samples. The analysis also reveals that larger training data mainly affects higher layers, and that the extent of this change is a factor of the number of iterations updating the model during fine-tuning rather than the diversity of the training samples. Finally, we show through a set of experiments that fine-tuning data size affects the recoverability of the changes made to the model's linguistic knowledge.
AdapLeR: Speeding up Inference by Adaptive Length Reduction
Mar 16, 2022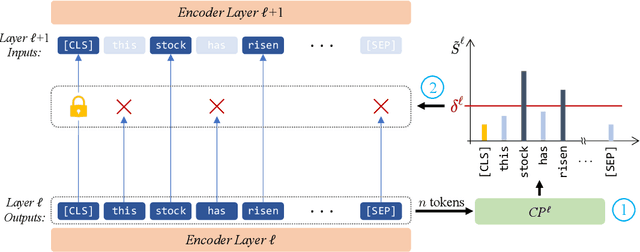
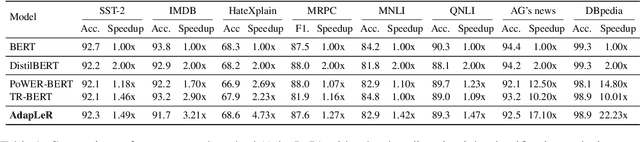
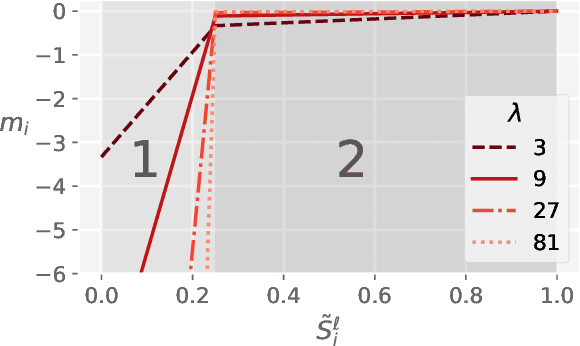
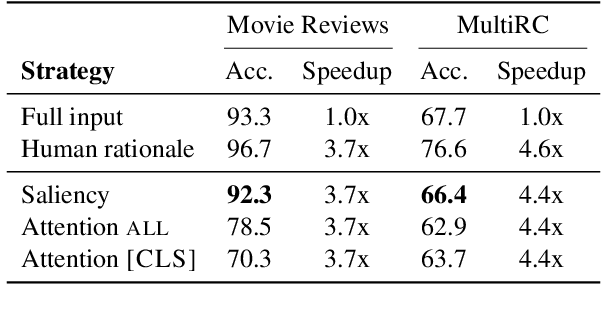
Pre-trained language models have shown stellar performance in various downstream tasks. But, this usually comes at the cost of high latency and computation, hindering their usage in resource-limited settings. In this work, we propose a novel approach for reducing the computational cost of BERT with minimal loss in downstream performance. Our method dynamically eliminates less contributing tokens through layers, resulting in shorter lengths and consequently lower computational cost. To determine the importance of each token representation, we train a Contribution Predictor for each layer using a gradient-based saliency method. Our experiments on several diverse classification tasks show speedups up to 22x during inference time without much sacrifice in performance. We also validate the quality of the selected tokens in our method using human annotations in the ERASER benchmark. In comparison to other widely used strategies for selecting important tokens, such as saliency and attention, our proposed method has a significantly lower false positive rate in generating rationales. Our code is freely available at https://github.com/amodaresi/AdapLeR .
An Isotropy Analysis in the Multilingual BERT Embedding Space
Oct 09, 2021
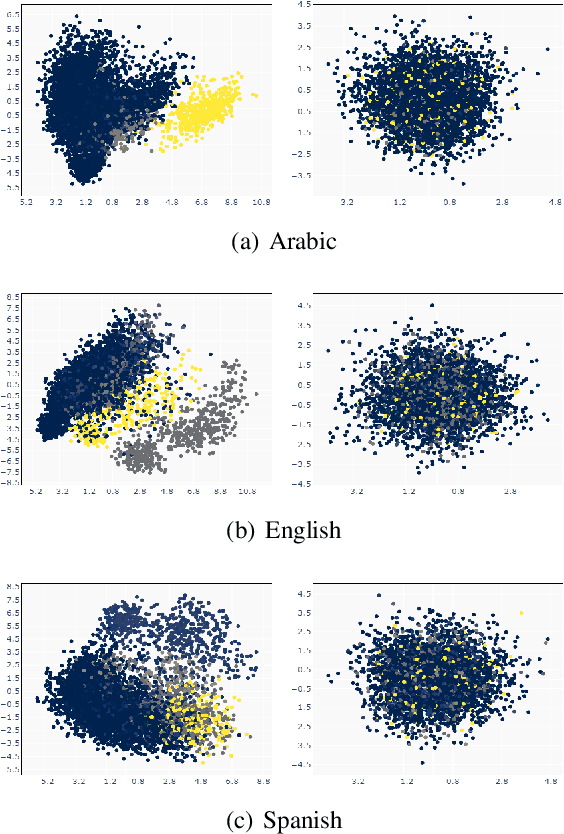


Several studies have explored various advantages of multilingual pre-trained models (e.g., multilingual BERT) in capturing shared linguistic knowledge. However, their limitations have not been paid enough attention. In this paper, we investigate the representation degeneration problem in multilingual contextual word representations (CWRs) of BERT and show that the embedding spaces of the selected languages suffer from anisotropy problem. Our experimental results demonstrate that, similarly to their monolingual counterparts, increasing the isotropy of multilingual embedding space can significantly improve its representation power and performance. Our analysis indicates that although the degenerated directions vary in different languages, they encode similar linguistic knowledge, suggesting a shared linguistic space among languages.
Not All Models Localize Linguistic Knowledge in the Same Place: A Layer-wise Probing on BERToids' Representations
Sep 15, 2021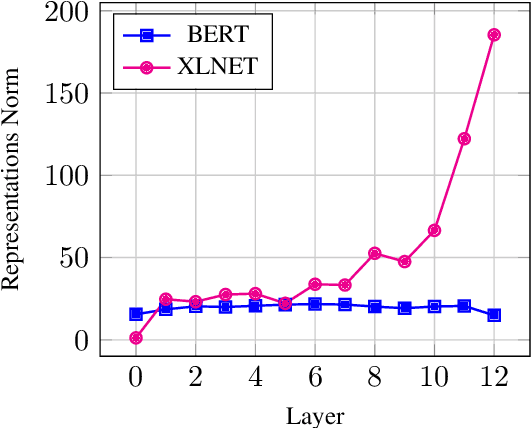

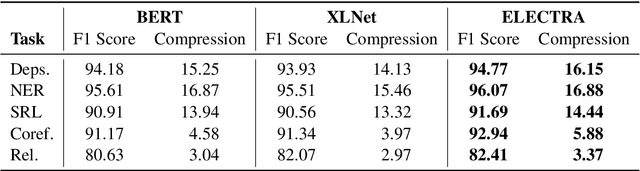
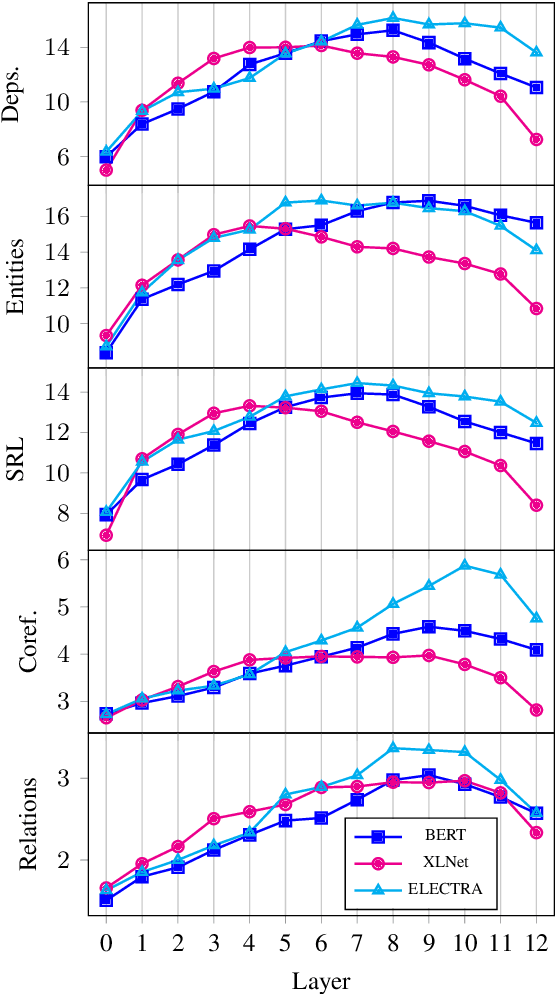
Most of the recent works on probing representations have focused on BERT, with the presumption that the findings might be similar to the other models. In this work, we extend the probing studies to two other models in the family, namely ELECTRA and XLNet, showing that variations in the pre-training objectives or architectural choices can result in different behaviors in encoding linguistic information in the representations. Most notably, we observe that ELECTRA tends to encode linguistic knowledge in the deeper layers, whereas XLNet instead concentrates that in the earlier layers. Also, the former model undergoes a slight change during fine-tuning, whereas the latter experiences significant adjustments. Moreover, we show that drawing conclusions based on the weight mixing evaluation strategy -- which is widely used in the context of layer-wise probing -- can be misleading given the norm disparity of the representations across different layers. Instead, we adopt an alternative information-theoretic probing with minimum description length, which has recently been proven to provide more reliable and informative results.
How Does Fine-tuning Affect the Geometry of Embedding Space: A Case Study on Isotropy
Sep 10, 2021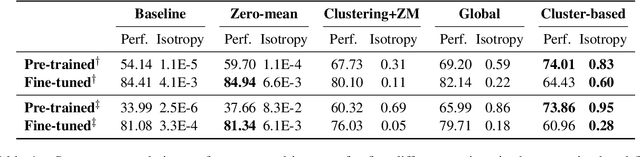
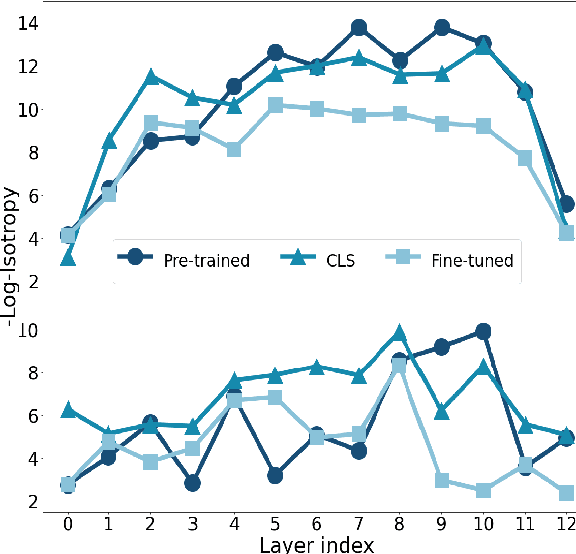

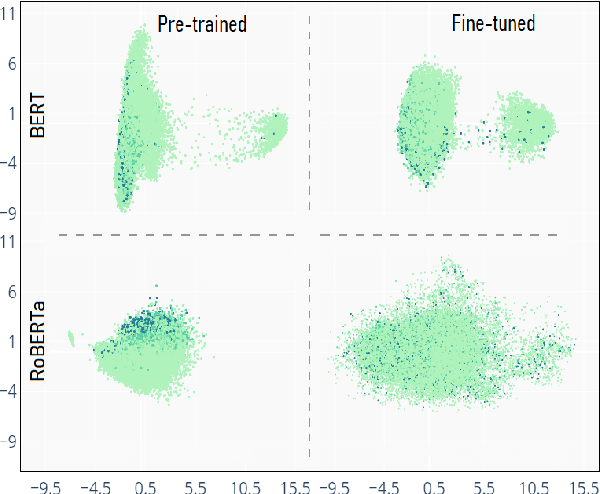
It is widely accepted that fine-tuning pre-trained language models usually brings about performance improvements in downstream tasks. However, there are limited studies on the reasons behind this effectiveness, particularly from the viewpoint of structural changes in the embedding space. Trying to fill this gap, in this paper, we analyze the extent to which the isotropy of the embedding space changes after fine-tuning. We demonstrate that, even though isotropy is a desirable geometrical property, fine-tuning does not necessarily result in isotropy enhancements. Moreover, local structures in pre-trained contextual word representations (CWRs), such as those encoding token types or frequency, undergo a massive change during fine-tuning. Our experiments show dramatic growth in the number of elongated directions in the embedding space, which, in contrast to pre-trained CWRs, carry the essential linguistic knowledge in the fine-tuned embedding space, making existing isotropy enhancement methods ineffective.
Don't Discard All the Biased Instances: Investigating a Core Assumption in Dataset Bias Mitigation Techniques
Sep 01, 2021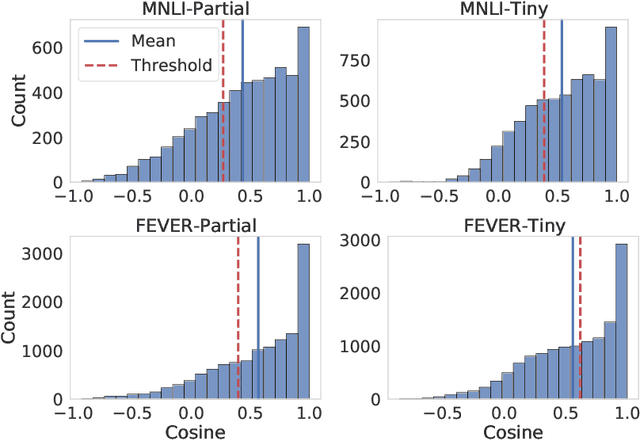
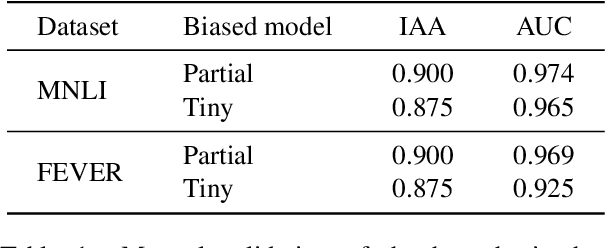
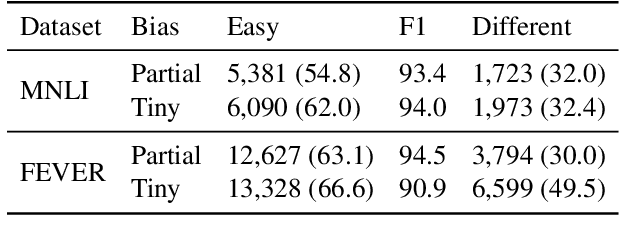
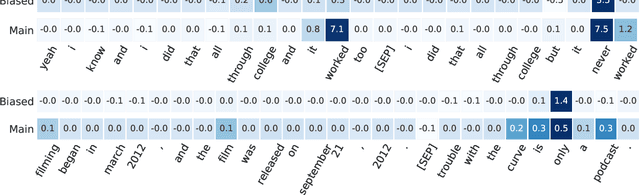
Existing techniques for mitigating dataset bias often leverage a biased model to identify biased instances. The role of these biased instances is then reduced during the training of the main model to enhance its robustness to out-of-distribution data. A common core assumption of these techniques is that the main model handles biased instances similarly to the biased model, in that it will resort to biases whenever available. In this paper, we show that this assumption does not hold in general. We carry out a critical investigation on two well-known datasets in the domain, MNLI and FEVER, along with two biased instance detection methods, partial-input and limited-capacity models. Our experiments show that in around a third to a half of instances, the biased model is unable to predict the main model's behavior, highlighted by the significantly different parts of the input on which they base their decisions. Based on a manual validation, we also show that this estimate is highly in line with human interpretation. Our findings suggest that down-weighting of instances detected by bias detection methods, which is a widely-practiced procedure, is an unnecessary waste of training data. We release our code to facilitate reproducibility and future research.
A Cluster-based Approach for Improving Isotropy in Contextual Embedding Space
Jun 02, 2021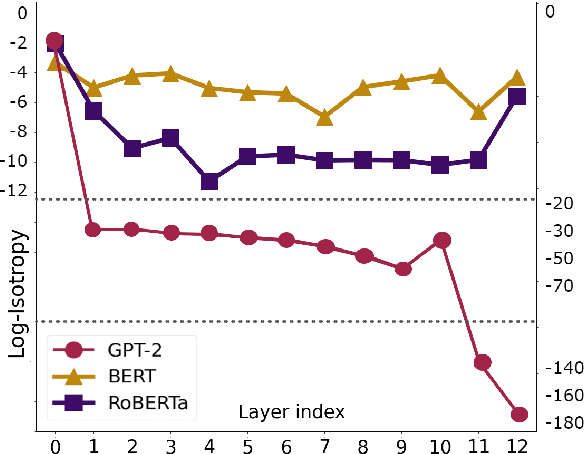
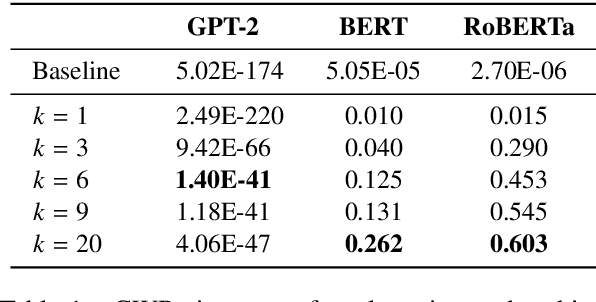
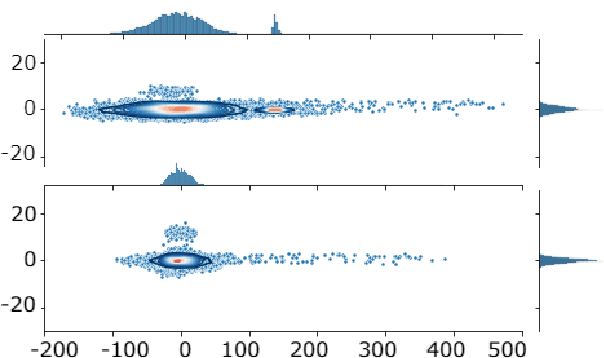
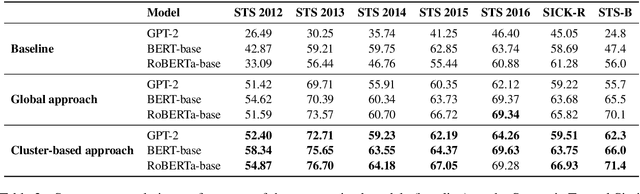
The representation degeneration problem in Contextual Word Representations (CWRs) hurts the expressiveness of the embedding space by forming an anisotropic cone where even unrelated words have excessively positive correlations. Existing techniques for tackling this issue require a learning process to re-train models with additional objectives and mostly employ a global assessment to study isotropy. Our quantitative analysis over isotropy shows that a local assessment could be more accurate due to the clustered structure of CWRs. Based on this observation, we propose a local cluster-based method to address the degeneration issue in contextual embedding spaces. We show that in clusters including punctuations and stop words, local dominant directions encode structural information, removing which can improve CWRs performance on semantic tasks. Moreover, we find that tense information in verb representations dominates sense semantics. We show that removing dominant directions of verb representations can transform the space to better suit semantic applications. Our experiments demonstrate that the proposed cluster-based method can mitigate the degeneration problem on multiple tasks.
Exploring the Role of BERT Token Representations to Explain Sentence Probing Results
Apr 03, 2021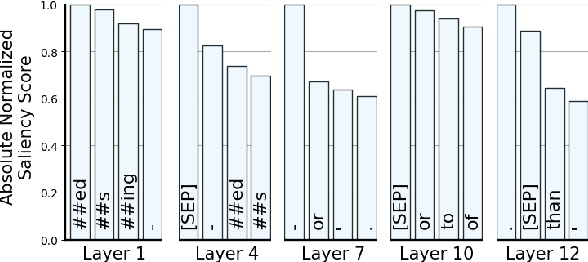
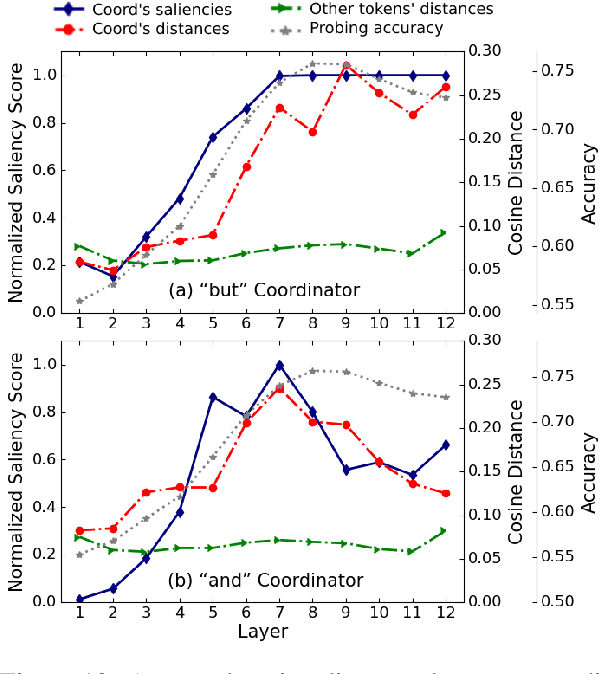
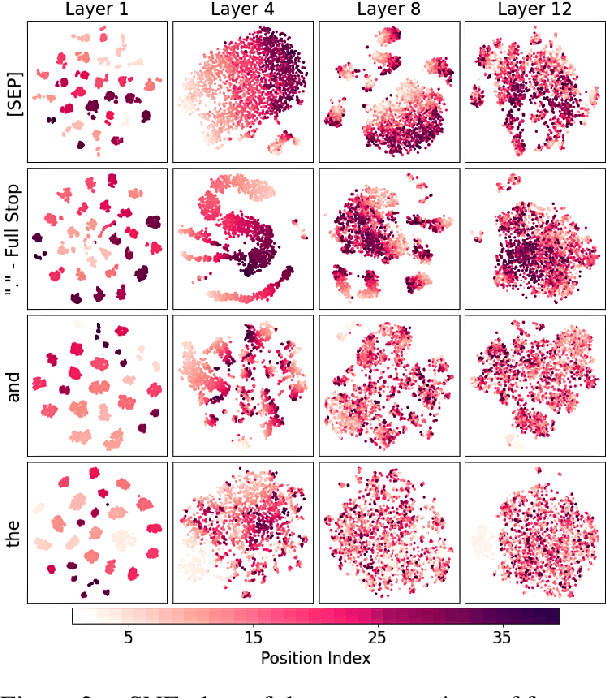
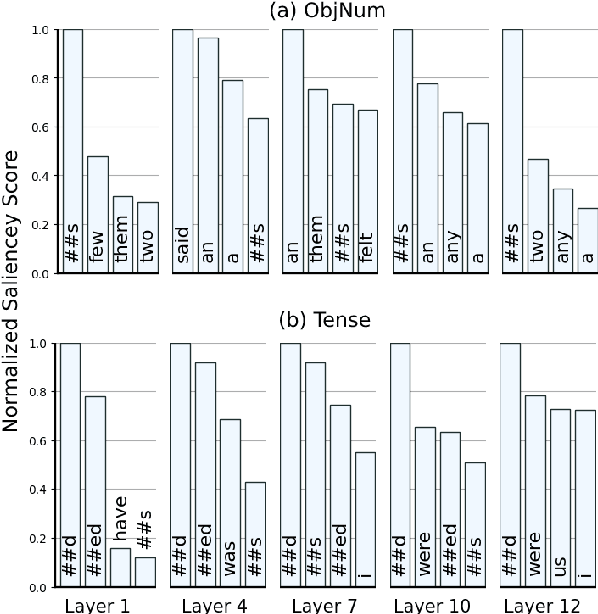
Several studies have been carried out on revealing linguistic features captured by BERT. This is usually achieved by training a diagnostic classifier on the representations obtained from different layers of BERT. The subsequent classification accuracy is then interpreted as the ability of the model in encoding the corresponding linguistic property. Despite providing insights, these studies have left out the potential role of token representations. In this paper, we provide an analysis on the representation space of BERT in search for distinct and meaningful subspaces that can explain probing results. Based on a set of probing tasks and with the help of attribution methods we show that BERT tends to encode meaningful knowledge in specific token representations (which are often ignored in standard classification setups), allowing the model to detect syntactic and semantic abnormalities, and to distinctively separate grammatical number and tense subspaces.
XL-WiC: A Multilingual Benchmark for Evaluating Semantic Contextualization
Oct 13, 2020
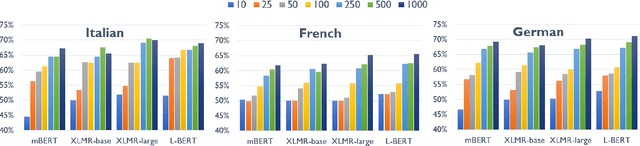
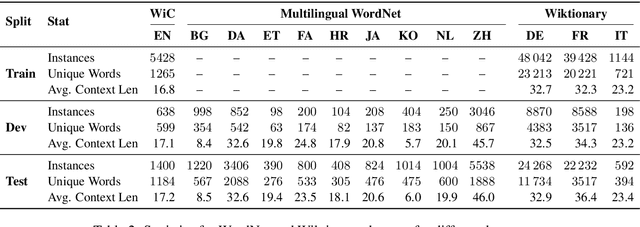
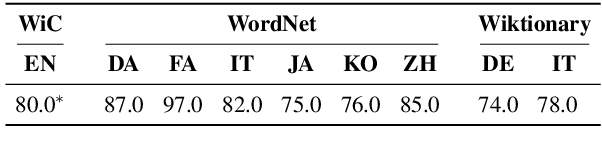
The ability to correctly model distinct meanings of a word is crucial for the effectiveness of semantic representation techniques. However, most existing evaluation benchmarks for assessing this criterion are tied to sense inventories (usually WordNet), restricting their usage to a small subset of knowledge-based representation techniques. The Word-in-Context dataset (WiC) addresses the dependence on sense inventories by reformulating the standard disambiguation task as a binary classification problem; but, it is limited to the English language. We put forward a large multilingual benchmark, XL-WiC, featuring gold standards in 12 new languages from varied language families and with different degrees of resource availability, opening room for evaluation scenarios such as zero-shot cross-lingual transfer. We perform a series of experiments to determine the reliability of the datasets and to set performance baselines for several recent contextualized multilingual models. Experimental results show that even when no tagged instances are available for a target language, models trained solely on the English data can attain competitive performance in the task of distinguishing different meanings of a word, even for distant languages. XL-WiC is available at https://pilehvar.github.io/xlwic/.
Language Models and Word Sense Disambiguation: An Overview and Analysis
Aug 26, 2020
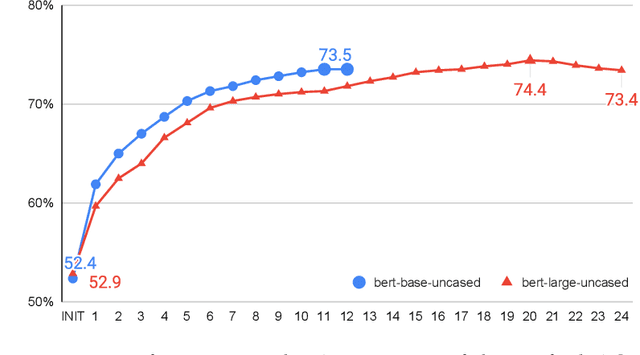

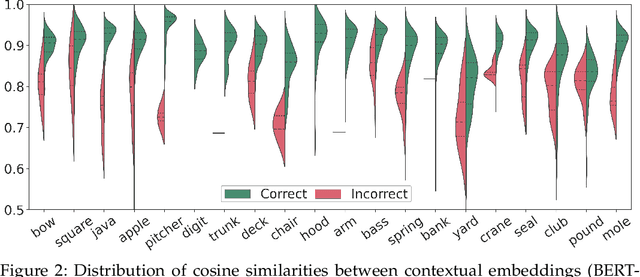
Transformer-based language models have taken many fields in NLP by storm. BERT and its derivatives dominate most of the existing evaluation benchmarks, including those for Word Sense Disambiguation (WSD), thanks to their ability in capturing context-sensitive semantic nuances. However, there is still little knowledge about their capabilities and potential limitations for encoding and recovering word senses. In this article, we provide an in-depth quantitative and qualitative analysis of the celebrated BERT model with respect to lexical ambiguity. One of the main conclusions of our analysis is that BERT performs a decent job in capturing high-level sense distinctions, even when a limited number of examples is available for each word sense. Our analysis also reveals that in some cases language models come close to solving coarse-grained noun disambiguation under ideal conditions in terms of availability of training data and computing resources. However, this scenario rarely occurs in real-world settings and, hence, many practical challenges remain even in the coarse-grained setting. We also perform an in-depth comparison of the two main language model based WSD strategies, i.e., fine-tuning and feature extraction, finding that the latter approach is more robust with respect to sense bias and it can better exploit limited available training data.