 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGNet: Scalable Embeddings for Signed Networks
Mar 22, 2018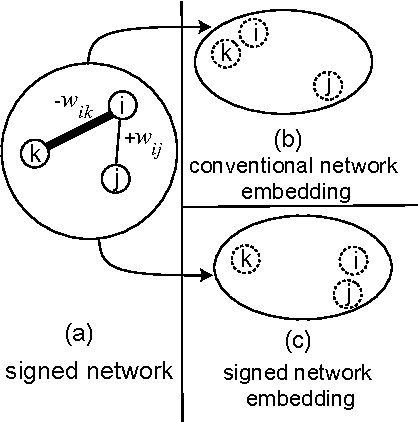
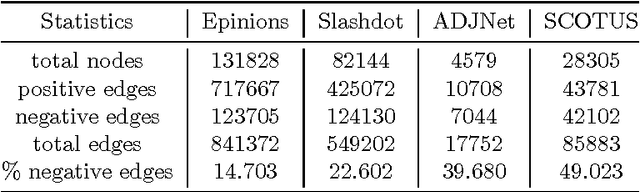
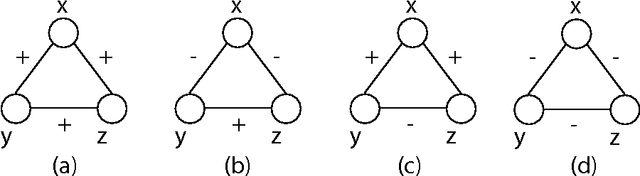
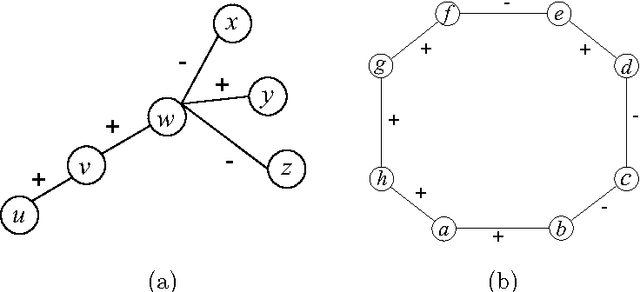
Recent successes in word embedding and document embedding have motivated researchers to explore similar representations for networks and to use such representations for tasks such as edge prediction, node label prediction, and community detection. Such network embedding methods are largely focused on finding distributed representations for unsigned networks and are unable to discover embeddings that respect polarities inherent in edges. We propose SIGNet, a fast scalable embedding method suitable for signed networks. Our proposed objective function aims to carefully model the social structure implicit in signed networks by reinforcing the principles of social balance theory. Our method builds upon the traditional word2vec family of embedding approaches and adds a new targeted node sampling strategy to maintain structural balance in higher-order neighborhoods. We demonstrate the superiority of SIGNet over state-of-the-art methods proposed for both signed and unsigned networks on several real world datasets from different domains. In particular, SIGNet offers an approach to generate a richer vocabulary of features of signed networks to support representation and reasoning.
Interactive Storytelling over Document Collections
Feb 21, 2016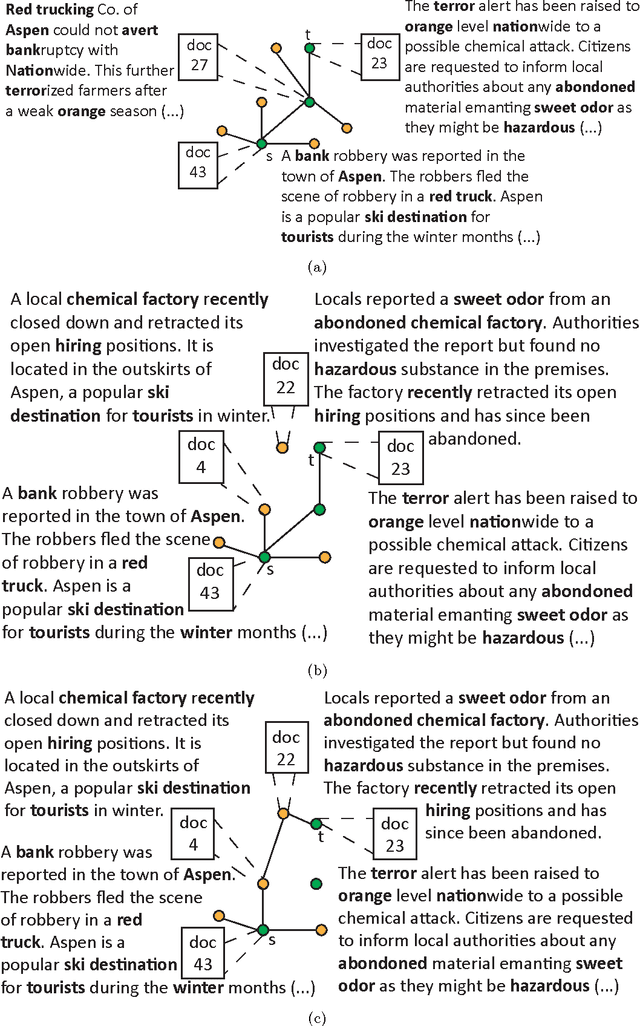
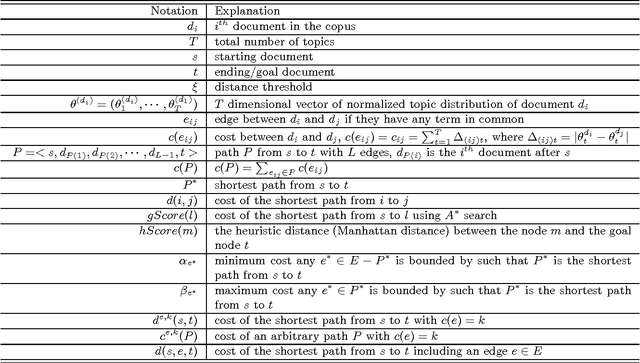
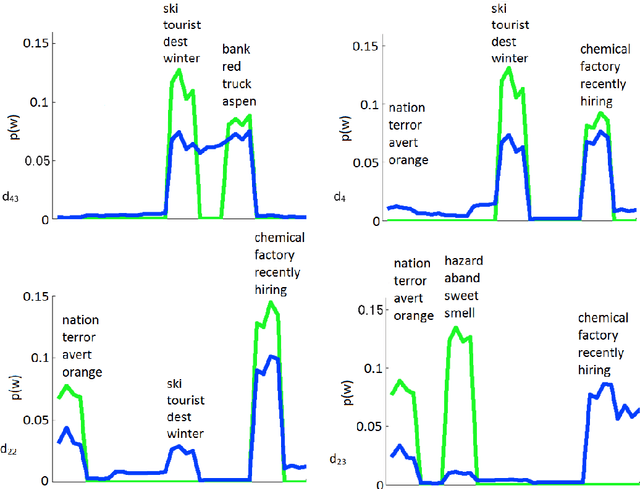
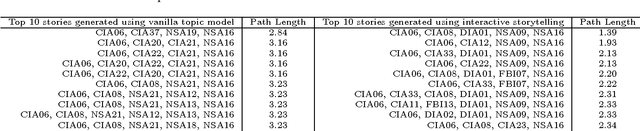
Storytelling algorithms aim to 'connect the dots' between disparate documents by linking starting and ending documents through a series of intermediate documents. Existing storytelling algorithms are based on notions of coherence and connectivity, and thus the primary way by which users can steer the story construction is via design of suitable similarity functions. We present an alternative approach to storytelling wherein the user can interactively and iteratively provide 'must use' constraints to preferentially support the construction of some stories over others. The three innovations in our approach are distance measures based on (inferred) topic distributions, the use of constraints to define sets of linear inequalities over paths, and the introduction of slack and surplus variables to condition the topic distribution to preferentially emphasize desired terms over others. We describe experimental results to illustrate the effectiveness of our interactive storytelling approach over multiple text datasets.