 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation Fault: A Cheap Defense Against Adversarial Machine Learning
Aug 31, 2021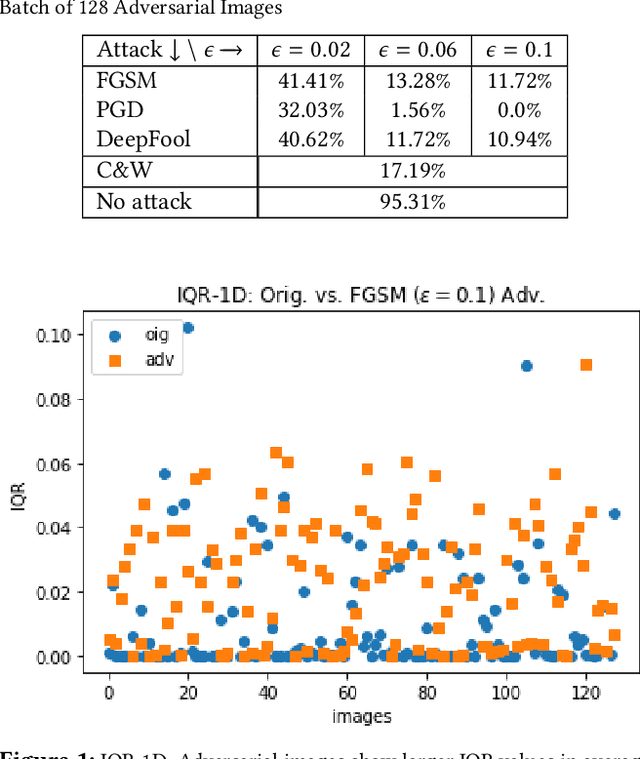
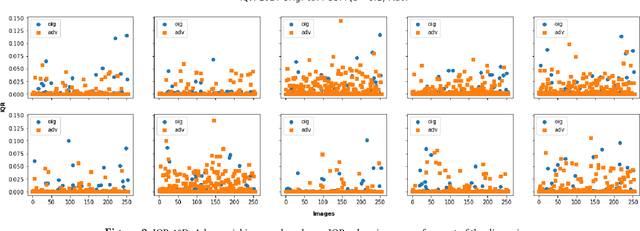

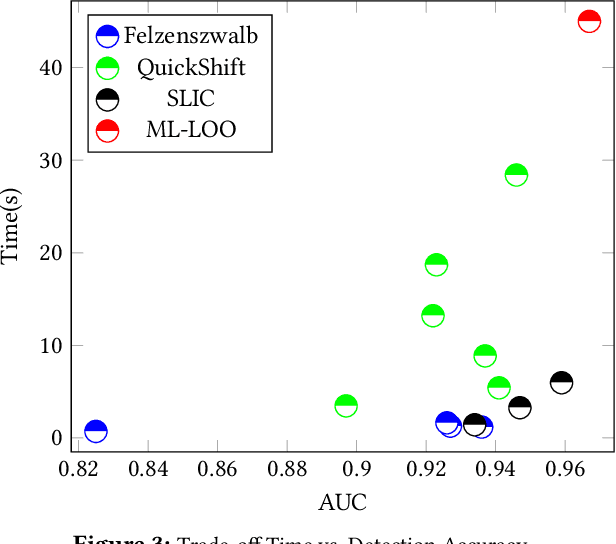
Recently published attacks against deep neural networks (DNNs) have stressed the importance of methodologies and tools to assess the security risks of using this technology in critical systems. Efficient techniques for detecting adversarial machine learning helps establishing trust and boost the adoption of deep learning in sensitive and security systems. In this paper, we propose a new technique for defending deep neural network classifiers, and convolutional ones in particular. Our defense is cheap in the sense that it requires less computation power despite a small cost to pay in terms of detection accuracy. The work refers to a recently published technique called ML-LOO. We replace the costly pixel by pixel leave-one-out approach of ML-LOO by adopting coarse-grained leave-one-out. We evaluate and compare the efficiency of different segmentation algorithms for this task. Our results show that a large gain in efficiency is possible, even though penalized by a marginal decrease in detection accuracy.
Hack The Box: Fooling Deep Learning Abstraction-Based Monitors
Jul 18, 2021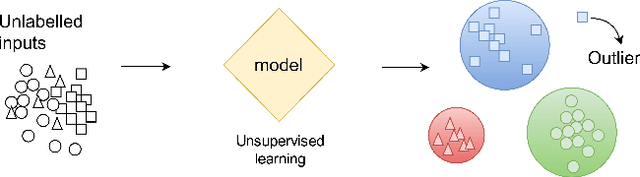
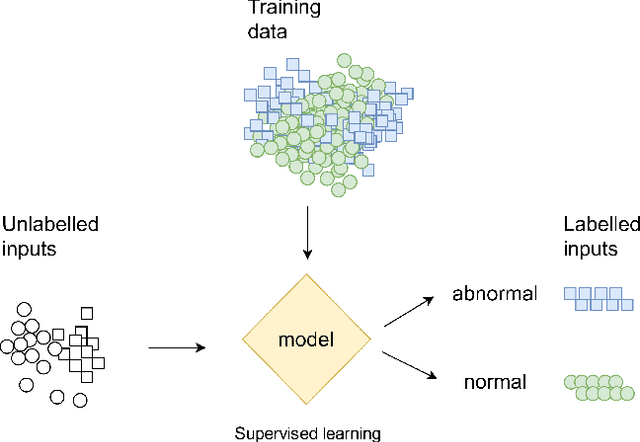
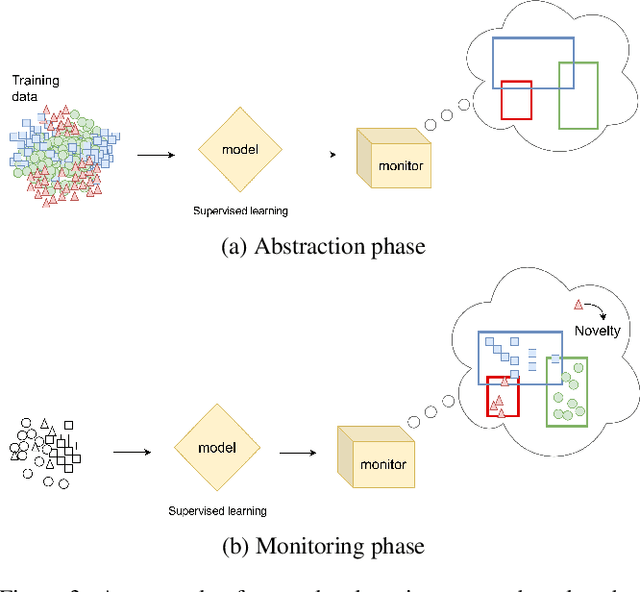
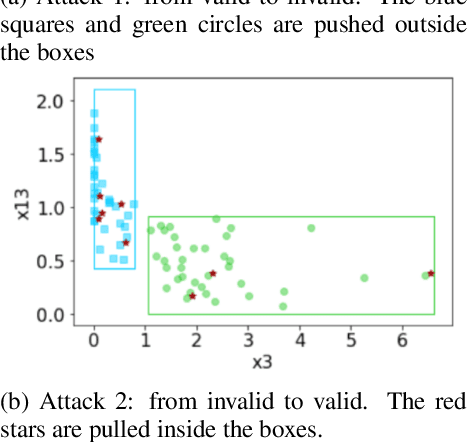
Deep learning is a type of machine learning that adapts a deep hierarchy of concepts. Deep learning classifiers link the most basic version of concepts at the input layer to the most abstract version of concepts at the output layer, also known as a class or label. However, once trained over a finite set of classes, some deep learning models do not have the power to say that a given input does not belong to any of the classes and simply cannot be linked. Correctly invalidating the prediction of unrelated classes is a challenging problem that has been tackled in many ways in the literature. Novelty detection gives deep learning the ability to output "do not know" for novel/unseen classes. Still, no attention has been given to the security aspects of novelty detection. In this paper, we consider the case study of abstraction-based novelty detection and show that it is not robust against adversarial samples. Moreover, we show the feasibility of crafting adversarial samples that fool the deep learning classifier and bypass the novelty detection monitoring at the same time. In other words, these monitoring boxes are hackable. We demonstrate that novelty detection itself ends up as an attack surface.
Throttling Malware Families in 2D
Jan 29, 2019
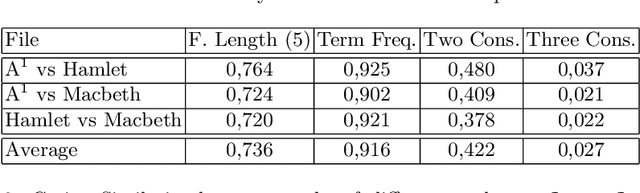
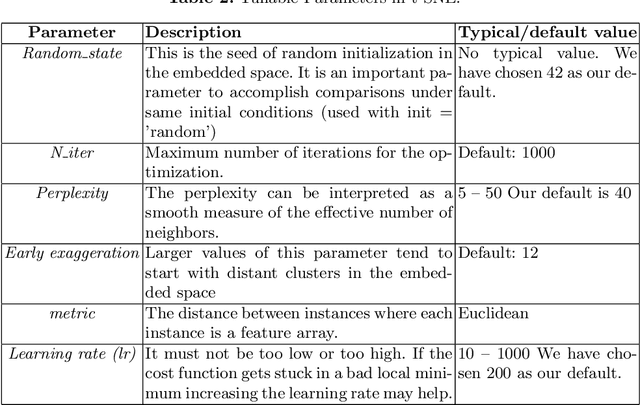
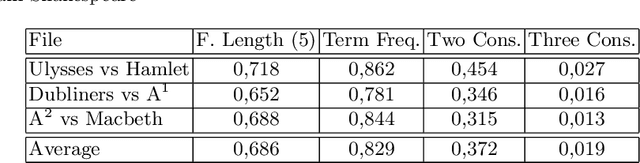
Malicious software are categorized into families based on their static and dynamic characteristics, infection methods, and nature of threat. Visual exploration of malware instances and families in a low dimensional space helps in giving a first overview about dependencies and relationships among these instances, detecting their groups and isolating outliers. Furthermore, visual exploration of different sets of features is useful in assessing the quality of these sets to carry a valid abstract representation, which can be later used in classification and clustering algorithms to achieve a high accuracy. In this paper, we investigate one of the best dimensionality reduction techniques known as t-SNE to reduce the malware representation from a high dimensional space consisting of thousands of features to a low dimensional space. We experiment with different feature sets and depict malware clusters in 2-D. Surprisingly, t-SNE does not only provide nice 2-D drawings, but also dramatically increases the generalization power of SVM classifiers. Moreover, obtained results showed that cross-validation accuracy is much better using the 2-D embedded representation of samples than using the original high-dimensional representation.