 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Convolutional Networks: Named Entity Recognition and Large Language Model Embedding in Document Clustering
Dec 19, 2024



Recent advances in machine learning, particularly Large Language Models (LLMs) such as BERT and GPT, provide rich contextual embeddings that improve text representation. However, current document clustering approaches often ignore the deeper relationships between named entities (NEs) and the potential of LLM embeddings. This paper proposes a novel approach that integrates Named Entity Recognition (NER) and LLM embeddings within a graph-based framework for document clustering. The method builds a graph with nodes representing documents and edges weighted by named entity similarity, optimized using a graph-convolutional network (GCN). This ensures a more effective grouping of semantically related documents. Experimental results indicate that our approach outperforms conventional co-occurrence-based methods in clustering, notably for documents rich in named entities.
More Discriminative Sentence Embeddings via Semantic Graph Smoothing
Feb 20, 2024



This paper explores an empirical approach to learn more discriminantive sentence representations in an unsupervised fashion. Leveraging semantic graph smoothing, we enhance sentence embeddings obtained from pretrained models to improve results for the text clustering and classification tasks. Our method, validated on eight benchmarks, demonstrates consistent improvements, showcasing the potential of semantic graph smoothing in improving sentence embeddings for the supervised and unsupervised document categorization tasks.
Graph Cuts with Arbitrary Size Constraints Through Optimal Transport
Feb 07, 2024



A common way of partitioning graphs is through minimum cuts. One drawback of classical minimum cut methods is that they tend to produce small groups, which is why more balanced variants such as normalized and ratio cuts have seen more success. However, we believe that with these variants, the balance constraints can be too restrictive for some applications like for clustering of imbalanced datasets, while not being restrictive enough for when searching for perfectly balanced partitions. Here, we propose a new graph cut algorithm for partitioning graphs under arbitrary size constraints. We formulate the graph cut problem as a regularized Gromov-Wasserstein problem. We then propose to solve it using accelerated proximal GD algorithm which has global convergence guarantees, results in sparse solutions and only incurs an additional ratio of $\mathcal{O}(\log(n))$ compared to the classical spectral clustering algorithm but was seen to be more efficient.
Scalable Multi-view Clustering via Explicit Kernel Features Maps
Feb 07, 2024A growing awareness of multi-view learning as an important component in data science and machine learning is a consequence of the increasing prevalence of multiple views in real-world applications, especially in the context of networks. In this paper we introduce a new scalability framework for multi-view subspace clustering. An efficient optimization strategy is proposed, leveraging kernel feature maps to reduce the computational burden while maintaining good clustering performance. The scalability of the algorithm means that it can be applied to large-scale datasets, including those with millions of data points, using a standard machine, in a few minutes. We conduct extensive experiments on real-world benchmark networks of various sizes in order to evaluate the performance of our algorithm against state-of-the-art multi-view subspace clustering methods and attributed-network multi-view approaches.
A survey on recent advances in named entity recognition
Jan 19, 2024Named Entity Recognition seeks to extract substrings within a text that name real-world objects and to determine their type (for example, whether they refer to persons or organizations). In this survey, we first present an overview of recent popular approaches, but we also look at graph- and transformer- based methods including Large Language Models (LLMs) that have not had much coverage in other surveys. Second, we focus on methods designed for datasets with scarce annotations. Third, we evaluate the performance of the main NER implementations on a variety of datasets with differing characteristics (as regards their domain, their size, and their number of classes). We thus provide a deep comparison of algorithms that are never considered together. Our experiments shed some light on how the characteristics of datasets affect the behavior of the methods that we compare.
Spectral Clustering via Ensemble Deep Autoencoder Learning (SC-EDAE)
Jan 08, 2019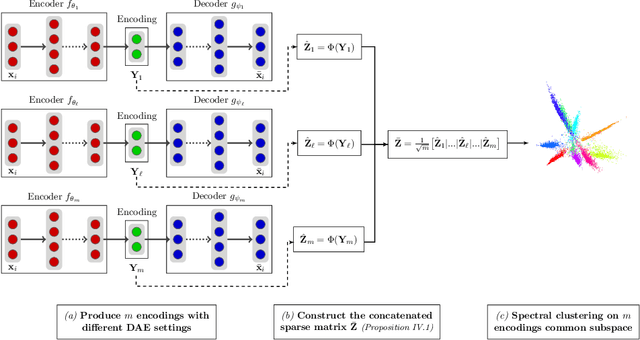
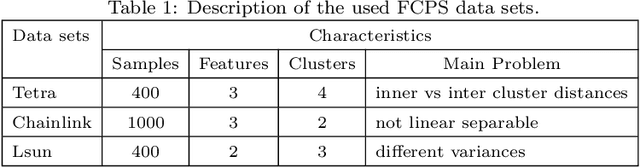
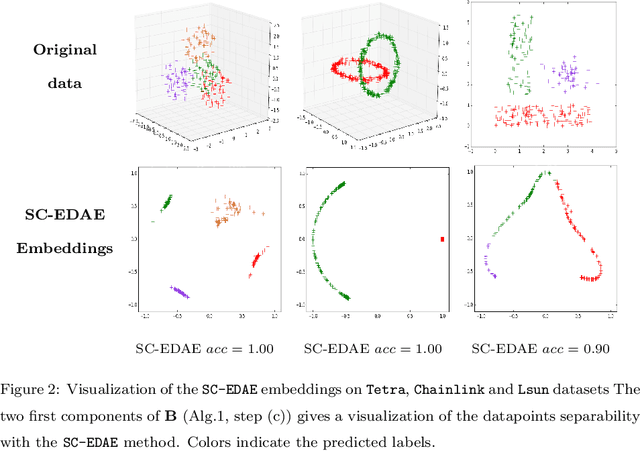
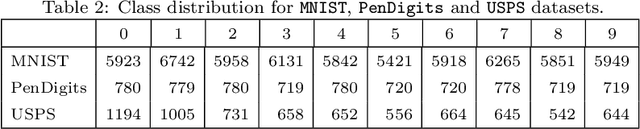
Recently, a number of works have studied clustering strategies that combine classical clustering algorithms and deep learning methods. These approaches follow either a sequential way, where a deep representation is learned using a deep autoencoder before obtaining clusters with k-means, or a simultaneous way, where deep representation and clusters are learned jointly by optimizing a single objective function. Both strategies improve clustering performance, however the robustness of these approaches is impeded by several deep autoencoder setting issues, among which the weights initialization, the width and number of layers or the number of epochs. To alleviate the impact of such hyperparameters setting on the clustering performance, we propose a new model which combines the spectral clustering and deep autoencoder strengths in an ensemble learning framework. Extensive experiments on various benchmark datasets demonstrate the potential and robustness of our approach compared to state-of-the art deep clustering methods.