 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRosetta Stone at KSAA-RD Shared Task: A Hop From Language Modeling To Word--Definition Alignment
Oct 24, 2023



A Reverse Dictionary is a tool enabling users to discover a word based on its provided definition, meaning, or description. Such a technique proves valuable in various scenarios, aiding language learners who possess a description of a word without its identity, and benefiting writers seeking precise terminology. These scenarios often encapsulate what is referred to as the "Tip-of-the-Tongue" (TOT) phenomena. In this work, we present our winning solution for the Arabic Reverse Dictionary shared task. This task focuses on deriving a vector representation of an Arabic word from its accompanying description. The shared task encompasses two distinct subtasks: the first involves an Arabic definition as input, while the second employs an English definition. For the first subtask, our approach relies on an ensemble of finetuned Arabic BERT-based models, predicting the word embedding for a given definition. The final representation is obtained through averaging the output embeddings from each model within the ensemble. In contrast, the most effective solution for the second subtask involves translating the English test definitions into Arabic and applying them to the finetuned models originally trained for the first subtask. This straightforward method achieves the highest score across both subtasks.
How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation
Feb 18, 2023



Generative Pre-trained Transformer (GPT) models have shown remarkable capabilities for natural language generation, but their performance for machine translation has not been thoroughly investigated. In this paper, we present a comprehensive evaluation of GPT models for machine translation, covering various aspects such as quality of different GPT models in comparison with state-of-the-art research and commercial systems, effect of prompting strategies, robustness towards domain shifts and document-level translation. We experiment with eighteen different translation directions involving high and low resource languages, as well as non English-centric translations, and evaluate the performance of three GPT models: ChatGPT, GPT3.5 (text-davinci-003), and text-davinci-002. Our results show that GPT models achieve very competitive translation quality for high resource languages, while having limited capabilities for low resource languages. We also show that hybrid approaches, which combine GPT models with other translation systems, can further enhance the translation quality. We perform comprehensive analysis and human evaluation to further understand the characteristics of GPT translations. We hope that our paper provides valuable insights for researchers and practitioners in the field and helps to better understand the potential and limitations of GPT models for translation.
Adapting MARBERT for Improved Arabic Dialect Identification: Submission to the NADI 2021 Shared Task
Mar 01, 2021

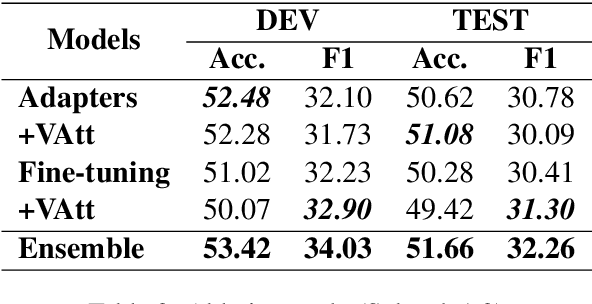
In this paper, we tackle the Nuanced Arabic Dialect Identification (NADI) shared task (Abdul-Mageed et al., 2021) and demonstrate state-of-the-art results on all of its four subtasks. Tasks are to identify the geographic origin of short Dialectal (DA) and Modern Standard Arabic (MSA) utterances at the levels of both country and province. Our final model is an ensemble of variants built on top of MARBERT that achieves an F1-score of 34.03% for DA at the country-level development set -- an improvement of 7.63% from previous work.
Deep Diacritization: Efficient Hierarchical Recurrence for Improved Arabic Diacritization
Nov 01, 2020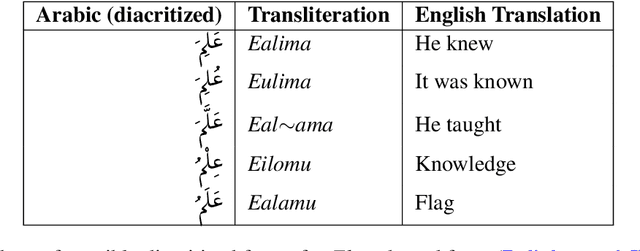
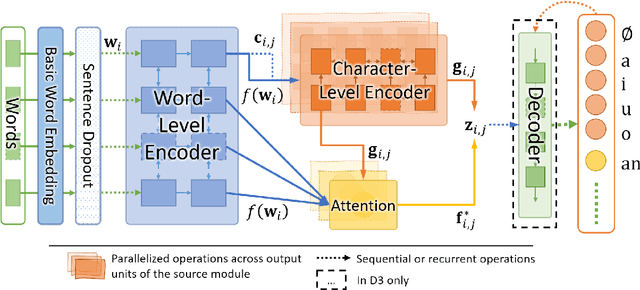
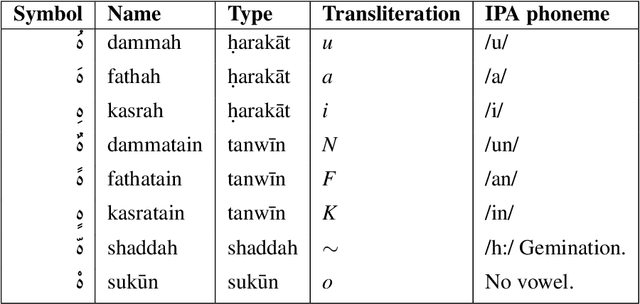
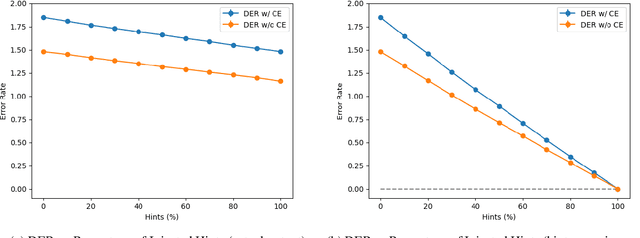
We propose a novel architecture for labelling character sequences that achieves state-of-the-art results on the Tashkeela Arabic diacritization benchmark. The core is a two-level recurrence hierarchy that operates on the word and character levels separately---enabling faster training and inference than comparable traditional models. A cross-level attention module further connects the two, and opens the door for network interpretability. The task module is a softmax classifier that enumerates valid combinations of diacritics. This architecture can be extended with a recurrent decoder that optionally accepts priors from partially diacritized text, which improves results. We employ extra tricks such as sentence dropout and majority voting to further boost the final result. Our best model achieves a WER of 5.34%, outperforming the previous state-of-the-art with a 30.56% relative error reduction.