 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLOG-CD: Curriculum Learning based on Oscillating Granularity of Class Decomposed Medical Image Classification
May 03, 2025



Curriculum learning strategies have been proven to be effective in various applications and have gained significant interest in the field of machine learning. It has the ability to improve the final model's performance and accelerate the training process. However, in the medical imaging domain, data irregularities can make the recognition task more challenging and usually result in misclassification between the different classes in the dataset. Class-decomposition approaches have shown promising results in solving such a problem by learning the boundaries within the classes of the data set. In this paper, we present a novel convolutional neural network (CNN) training method based on the curriculum learning strategy and the class decomposition approach, which we call CLOG-CD, to improve the performance of medical image classification. We evaluated our method on four different imbalanced medical image datasets, such as Chest X-ray (CXR), brain tumour, digital knee X-ray, and histopathology colorectal cancer (CRC). CLOG-CD utilises the learnt weights from the decomposition granularity of the classes, and the training is accomplished from descending to ascending order (i.e., anti-curriculum technique). We also investigated the classification performance of our proposed method based on different acceleration factors and pace function curricula. We used two pre-trained networks, ResNet-50 and DenseNet-121, as the backbone for CLOG-CD. The results with ResNet-50 show that CLOG-CD has the ability to improve classification performance with an accuracy of 96.08% for the CXR dataset, 96.91% for the brain tumour dataset, 79.76% for the digital knee X-ray, and 99.17% for the CRC dataset, compared to other training strategies. In addition, with DenseNet-121, CLOG-CD has achieved 94.86%, 94.63%, 76.19%, and 99.45% for CXR, brain tumour, digital knee X-ray, and CRC datasets, respectively
Overview of the First Workshop on Language Models for Low-Resource Languages (LoResLM 2025)
Dec 20, 2024


The first Workshop on Language Models for Low-Resource Languages (LoResLM 2025) was held in conjunction with the 31st International Conference on Computational Linguistics (COLING 2025) in Abu Dhabi, United Arab Emirates. This workshop mainly aimed to provide a forum for researchers to share and discuss their ongoing work on language models (LMs) focusing on low-resource languages, following the recent advancements in neural language models and their linguistic biases towards high-resource languages. LoResLM 2025 attracted notable interest from the natural language processing (NLP) community, resulting in 35 accepted papers from 52 submissions. These contributions cover a broad range of low-resource languages from eight language families and 13 diverse research areas, paving the way for future possibilities and promoting linguistic inclusivity in NLP.
Prune2Edge: A Multi-Phase Pruning Pipelines to Deep Ensemble Learning in IIoT
Apr 09, 2020
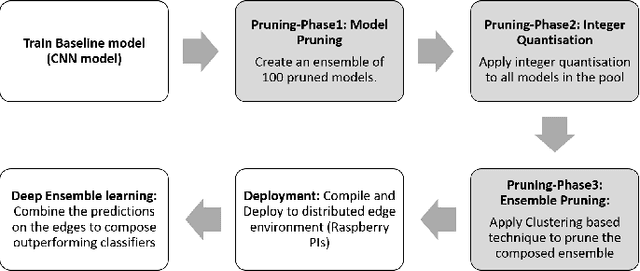

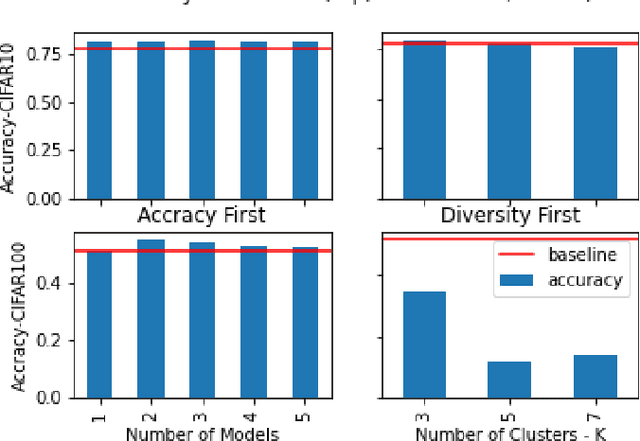
Most recently, with the proliferation of IoT devices, computational nodes in manufacturing systems IIoT(Industrial-Internet-of-things) and the lunch of 5G networks, there will be millions of connected devices generating a massive amount of data. In such an environment, the controlling systems need to be intelligent enough to deal with a vast amount of data to detect defects in a real-time process. Driven by such a need, artificial intelligence models such as deep learning have to be deployed into IIoT systems. However, learning and using deep learning models are computationally expensive, so an IoT device with limited computational power could not run such models. To tackle this issue, edge intelligence had emerged as a new paradigm towards running Artificial Intelligence models on edge devices. Although a considerable amount of studies have been proposed in this area, the research is still in the early stages. In this paper, we propose a novel edge-based multi-phase pruning pipelines to ensemble learning on IIoT devices. In the first phase, we generate a diverse ensemble of pruned models, then we apply integer quantisation, next we prune the generated ensemble using a clustering-based technique. Finally, we choose the best representative from each generated cluster to be deployed to a distributed IoT environment. On CIFAR-100 and CIFAR-10, our proposed approach was able to outperform the predictability levels of a baseline model (up to 7%), more importantly, the generated learners have small sizes (up to 90% reduction in the model size) that minimise the required computational capabilities to make an inference on the resource-constraint devices.