 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Discrepancy Acquisition for Pool-Based Active Learning
May 04, 2026The effectiveness of active learning hinges on the choice of the acquisition criterion by which a learning algorithm selects potentially informative data points whose label is subsequently queried. This paper proposes a novel gradient-based acquisition criterion, derived from a generalization bound introduced by Luo et al. (2022). This criterion can be applied in lieu of uncertainty measures in uncertainty sampling, or incorporated into diversity-based methods that consider the spread of sampled points in addition to the uncertainty of their labels. We provide a theoretical justification of the proposed acquisition criterion, and demonstrate its effectiveness in an empirical evaluation.
Selective Prediction from Agreement: A Lipschitz-Consistent Version Space Approach
May 04, 2026We consider selective classification with abstention in the fixed-pool (or transductive) setting, where the unlabeled pool is given beforehand and only a subset of points can be queried for labels. Our main insight is to view selective prediction through agreement: given queried labels and Lipschitz margin constraints in an embedding space, the version space of Lipschitz-consistent classification heads is well defined. We obtain upper and lower Lipschitz margin bounds that define, for each pool point, a set of certified valid labels containing the prediction of every head in the version space. The model therefore predicts only when the label is forced (i.e., all consistent heads agree), and abstains otherwise. We also propose a monotone submodular geometric proxy for budgeted querying, and show that a greedy algorithm retains the standard approximation factor.
Actively Learning Deep Neural Networks with Uncertainty Sampling Based on Sum-Product Networks
Jun 20, 2022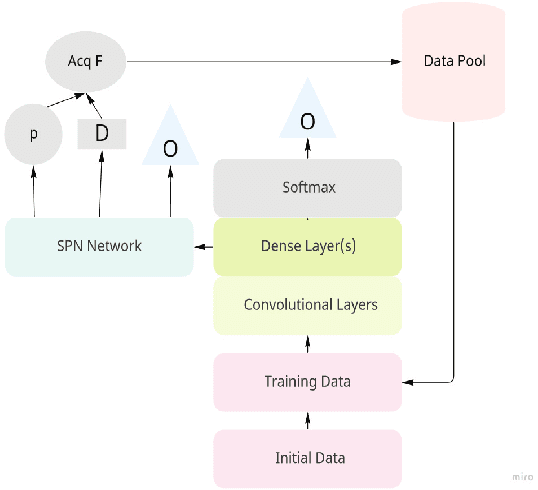

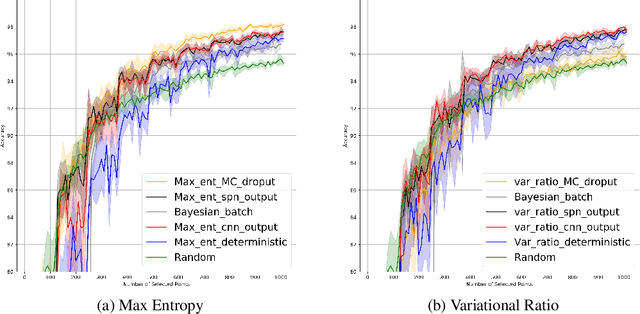
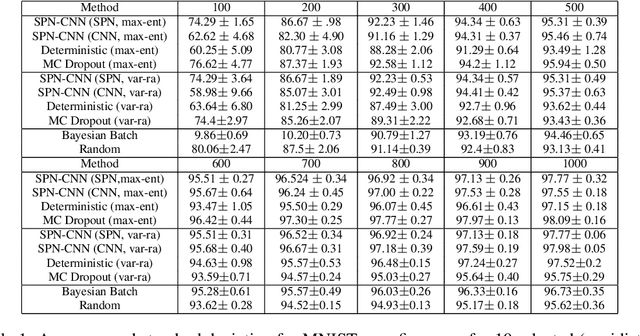
Active learning is popular approach for reducing the amount of data in training deep neural network model. Its success hinges on the choice of an effective acquisition function, which ranks not yet labeled data points according to their expected informativeness. In uncertainty sampling, the uncertainty that the current model has about a point's class label is the main criterion for this type of ranking. This paper proposes a new approach to uncertainty sampling in training a Convolutional Neural Network (CNN). The main idea is to use feature representation extracted extracted by the CNN as data for training a Sum-Product Network (SPN). Since SPNs are typically used for estimating the distribution of a dataset, they are well suited to the task of estimating class probabilities that can be used directly by standard acquisition functions such as max entropy and variational ratio. Moreover, we enhance these acquisition functions by weights calculated with the help of the SPN model; these weights make the acquisition function more sensitive to the diversity of conceivable class labels for data points. The effectiveness of our method is demonstrated in an experimental study on the MNIST, Fashion-MNIST and CIFAR-10 datasets, where we compare it to the state-of-the-art methods MC Dropout and Bayesian Batch.