 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGravity-Bench-v1: A Benchmark on Gravitational Physics Discovery for Agents
Jan 30, 2025



Modern science emerged from reasoning over repeatedly-observed planetary motions. We present Gravity-Bench-v1, an environment-based benchmark that challenges AI agents on tasks that parallel this historical development. Gravity-Bench-v1 evaluates agents on the discovery of physics concealed within a dynamic environment, using rigorous gravitational dynamics simulations. Gravity-Bench includes out-of-distribution cases, i.e. with physics that deviates from the real world, to evaluate true scientific generalization capabilities. Agents must plan to collect data within an experimental budget and must perform a dynamic form of data analysis and reasoning to solve tasks efficiently. Our benchmark admits an open-ended space of solutions. PhD-level solutions for each task are provided, to calibrate AI performance against human expertise. Technically at an upper-undergraduate level, our benchmark proves challenging to baseline AI agents. Gravity-Bench-v1 and planned extensions should help map out AI progress towards scientific discovery capabilities.
Physics simulation capabilities of LLMs
Dec 04, 2023[Abridged abstract] Large Language Models (LLMs) can solve some undergraduate-level to graduate-level physics textbook problems and are proficient at coding. Combining these two capabilities could one day enable AI systems to simulate and predict the physical world. We present an evaluation of state-of-the-art (SOTA) LLMs on PhD-level to research-level computational physics problems. We condition LLM generation on the use of well-documented and widely-used packages to elicit coding capabilities in the physics and astrophysics domains. We contribute $\sim 50$ original and challenging problems in celestial mechanics (with REBOUND), stellar physics (with MESA), 1D fluid dynamics (with Dedalus) and non-linear dynamics (with SciPy). Since our problems do not admit unique solutions, we evaluate LLM performance on several soft metrics: counts of lines that contain different types of errors (coding, physics, necessity and sufficiency) as well as a more "educational" Pass-Fail metric focused on capturing the salient physical ingredients of the problem at hand. As expected, today's SOTA LLM (GPT4) zero-shot fails most of our problems, although about 40\% of the solutions could plausibly get a passing grade. About $70-90 \%$ of the code lines produced are necessary, sufficient and correct (coding \& physics). Physics and coding errors are the most common, with some unnecessary or insufficient lines. We observe significant variations across problem class and difficulty. We identify several failure modes of GPT4 in the computational physics domain. Our reconnaissance work provides a snapshot of current computational capabilities in classical physics and points to obvious improvement targets if AI systems are ever to reach a basic level of autonomy in physics simulation capabilities.
A machine-generated catalogue of Charon's craters and implications for the Kuiper belt
Jun 16, 2022

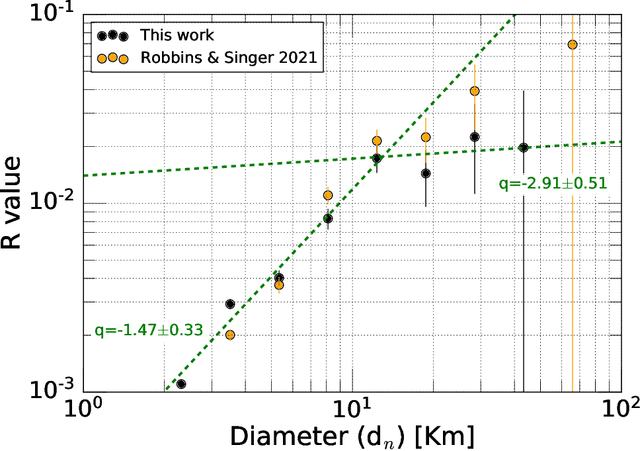
In this paper we investigate Charon's craters size distribution using a deep learning model. This is motivated by the recent results of Singer et al. (2019) who, using manual cataloging, found a change in the size distribution slope of craters smaller than 12 km in diameter, translating into a paucity of small Kuiper Belt objects. These results were corroborated by Robbins and Singer (2021), but opposed by Morbidelli et al. (2021), necessitating an independent review. Our MaskRCNN-based ensemble of models was trained on Lunar, Mercurian, and Martian crater catalogues and both optical and digital elevation images. We use a robust image augmentation scheme to force the model to generalize and transfer-learn into icy objects. With no prior bias or exposure to Charon, our model find best fit slopes of q =-1.47+-0.33 for craters smaller than 10 km, and q =-2.91+-0.51 for craters larger than 15 km. These values indicate a clear change in slope around 15 km as suggested by Singer et al. (2019) and thus independently confirm their conclusions. Our slopes however are both slightly flatter than those found more recently by Robbins and Singer (2021). Our trained models and relevant codes are available online on github.com/malidib/ACID .
Automated crater shape retrieval using weakly-supervised deep learning
Jun 20, 2019
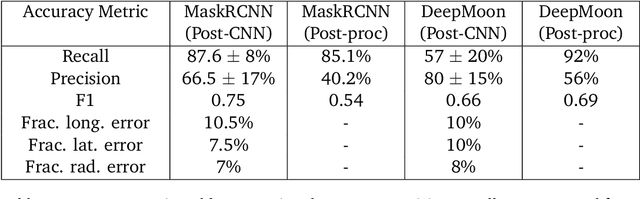
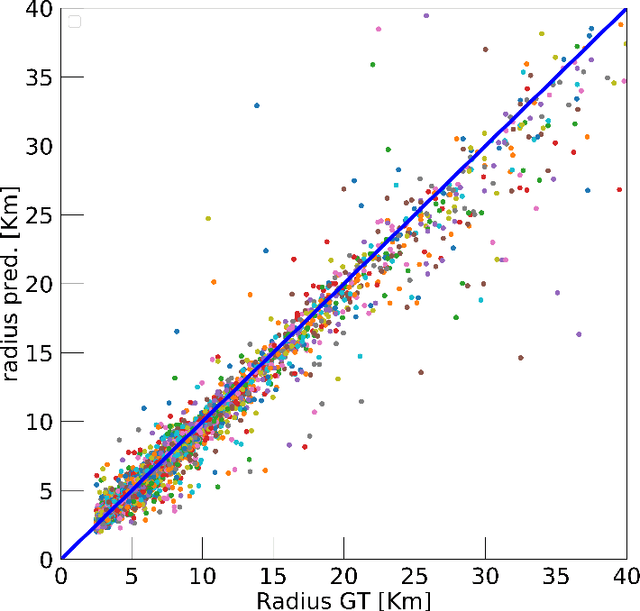
Crater shape determination is a complex and time consuming task that so far has evaded automation. We train a state of the art computer vision algorithm to identify craters on the moon and retrieve their sizes and shapes. The computational backbone of the model is MaskRCNN, an "instance segmentation" general framework that detects craters in an image while simultaneously producing a mask for each crater that traces its outer rim. Our post-processing pipeline then finds the closest fitting ellipse to these masks, allowing us to retrieve the crater ellipticities. Our model is able to correctly identify 87% of known craters in the holdout set, while predicting thousands of additional craters not present in our training data. Manual validation of a subset of these craters indicates that a majority of them are real, which we take as an indicator of the strength of our model in learning to identify craters, despite incomplete training data. The crater size, ellipticity, and depth distributions predicted by our model are consistent with human-generated results. The model allows us to perform a large scale search for differences in crater diameter and shape distributions between the lunar highlands and maria, and we exclude any such differences with a high statistical significance.