 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormative Reasoning in Large Language Models: A Comparative Benchmark from Logical and Modal Perspectives
Oct 30, 2025



Normative reasoning is a type of reasoning that involves normative or deontic modality, such as obligation and permission. While large language models (LLMs) have demonstrated remarkable performance across various reasoning tasks, their ability to handle normative reasoning remains underexplored. In this paper, we systematically evaluate LLMs' reasoning capabilities in the normative domain from both logical and modal perspectives. Specifically, to assess how well LLMs reason with normative modals, we make a comparison between their reasoning with normative modals and their reasoning with epistemic modals, which share a common formal structure. To this end, we introduce a new dataset covering a wide range of formal patterns of reasoning in both normative and epistemic domains, while also incorporating non-formal cognitive factors that influence human reasoning. Our results indicate that, although LLMs generally adhere to valid reasoning patterns, they exhibit notable inconsistencies in specific types of normative reasoning and display cognitive biases similar to those observed in psychological studies of human reasoning. These findings highlight challenges in achieving logical consistency in LLMs' normative reasoning and provide insights for enhancing their reliability. All data and code are released publicly at https://github.com/kmineshima/NeuBAROCO.
Exploring Reasoning Biases in Large Language Models Through Syllogism: Insights from the NeuBAROCO Dataset
Aug 08, 2024



This paper explores the question of how accurately current large language models can perform logical reasoning in natural language, with an emphasis on whether these models exhibit reasoning biases similar to humans. Specifically, our study focuses on syllogistic reasoning, a form of deductive reasoning extensively studied in cognitive science as a natural form of human reasoning. We present a syllogism dataset called NeuBAROCO, which consists of syllogistic reasoning problems in English and Japanese. This dataset was originally designed for psychological experiments to assess human reasoning capabilities using various forms of syllogisms. Our experiments with leading large language models indicate that these models exhibit reasoning biases similar to humans, along with other error tendencies. Notably, there is significant room for improvement in reasoning problems where the relationship between premises and hypotheses is neither entailment nor contradiction. We also present experimental results and in-depth analysis using a new Chain-of-Thought prompting method, which asks LLMs to translate syllogisms into abstract logical expressions and then explain their reasoning process. Our analysis using this method suggests that the primary limitations of LLMs lie in the reasoning process itself rather than the interpretation of syllogisms.
Evaluating Large Language Models with NeuBAROCO: Syllogistic Reasoning Ability and Human-like Biases
Jun 21, 2023



This paper investigates whether current large language models exhibit biases in logical reasoning, similar to humans. Specifically, we focus on syllogistic reasoning, a well-studied form of inference in the cognitive science of human deduction. To facilitate our analysis, we introduce a dataset called NeuBAROCO, originally designed for psychological experiments that assess human logical abilities in syllogistic reasoning. The dataset consists of syllogistic inferences in both English and Japanese. We examine three types of biases observed in human syllogistic reasoning: belief biases, conversion errors, and atmosphere effects. Our findings demonstrate that current large language models struggle more with problems involving these three types of biases.
Sensor-Augmented Egocentric-Video Captioning with Dynamic Modal Attention
Sep 07, 2021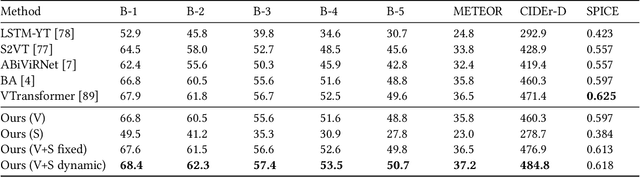
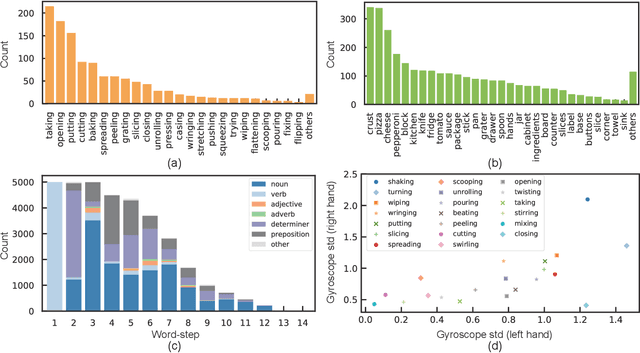

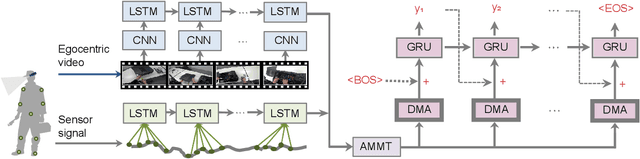
Automatically describing video, or video captioning, has been widely studied in the multimedia field. This paper proposes a new task of sensor-augmented egocentric-video captioning, a newly constructed dataset for it called MMAC Captions, and a method for the newly proposed task that effectively utilizes multi-modal data of video and motion sensors, or inertial measurement units (IMUs). While conventional video captioning tasks have difficulty in dealing with detailed descriptions of human activities due to the limited view of a fixed camera, egocentric vision has greater potential to be used for generating the finer-grained descriptions of human activities on the basis of a much closer view. In addition, we utilize wearable-sensor data as auxiliary information to mitigate the inherent problems in egocentric vision: motion blur, self-occlusion, and out-of-camera-range activities. We propose a method for effectively utilizing the sensor data in combination with the video data on the basis of an attention mechanism that dynamically determines the modality that requires more attention, taking the contextual information into account. We compared the proposed sensor-fusion method with strong baselines on the MMAC Captions dataset and found that using sensor data as supplementary information to the egocentric-video data was beneficial, and that our proposed method outperformed the strong baselines, demonstrating the effectiveness of the proposed method.