 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPOC: Safety-Aware Planning Under Partial Observability And Physical Constraints
Feb 25, 2026Embodied Task Planning with large language models faces safety challenges in real-world environments, where partial observability and physical constraints must be respected. Existing benchmarks often overlook these critical factors, limiting their ability to evaluate both feasibility and safety. We introduce SPOC, a benchmark for safety-aware embodied task planning, which integrates strict partial observability, physical constraints, step-by-step planning, and goal-condition-based evaluation. Covering diverse household hazards such as fire, fluid, injury, object damage, and pollution, SPOC enables rigorous assessment through both state and constraint-based online metrics. Experiments with state-of-the-art LLMs reveal that current models struggle to ensure safety-aware planning, particularly under implicit constraints. Code and dataset are available at https://github.com/khm159/SPOC
Model Comparison for Fast Domain Adaptation in Table Service Scenario
Mar 08, 2024In restaurants, many aspects of customer service, such as greeting customers, taking orders, and processing payments, are automated. Due to the various cuisines, required services, and different standards of each restaurant, one challenging part of making the entire automated process is inspecting and providing appropriate services at the table during a meal. In this paper, we demonstrate an approach for automatically checking and providing services at the table. We initially construct a base model to recognize common information to comprehend the context of the table, such as object category, remaining food quantity, and meal progress status. After that, we add a service recognition classifier and retrain the model using a small amount of local restaurant data. We gathered data capturing the restaurant table during the meal in order to find a suitable service recognition classifier. With different inputs, combinations, time series, and data choices, we carried out a variety of tests. Through these tests, we discovered that the model with few significant data points and trainable parameters is more crucial in the case of sparse and redundant retraining data.
LoTa-Bench: Benchmarking Language-oriented Task Planners for Embodied Agents
Feb 13, 2024



Large language models (LLMs) have recently received considerable attention as alternative solutions for task planning. However, comparing the performance of language-oriented task planners becomes difficult, and there exists a dearth of detailed exploration regarding the effects of various factors such as pre-trained model selection and prompt construction. To address this, we propose a benchmark system for automatically quantifying performance of task planning for home-service embodied agents. Task planners are tested on two pairs of datasets and simulators: 1) ALFRED and AI2-THOR, 2) an extension of Watch-And-Help and VirtualHome. Using the proposed benchmark system, we perform extensive experiments with LLMs and prompts, and explore several enhancements of the baseline planner. We expect that the proposed benchmark tool would accelerate the development of language-oriented task planners.
Uncertainty-Aware Shared Autonomy System with Hierarchical Conservative Skill Inference
Dec 05, 2023Shared autonomy imitation learning, in which robots share workspace with humans for learning, enables correct actions in unvisited states and the effective resolution of compounding errors through expert's corrections. However, it demands continuous human attention and supervision to lead the demonstrations, without considering the risks associated with human judgment errors and delayed interventions. This can potentially lead to high levels of fatigue for the demonstrator and the additional errors. In this work, we propose an uncertainty-aware shared autonomy system that enables the robot to infer conservative task skills considering environmental uncertainties and learning from expert demonstrations and corrections. To enhance generalization and scalability, we introduce a hierarchical structure-based skill uncertainty inference framework operating at more abstract levels. We apply this to robot motion to promote a more stable interaction. Although shared autonomy systems have demonstrated high-level results in recent research and play a critical role, specific system design details have remained elusive. This paper provides a detailed design proposal for a shared autonomy system considering various robot configurations. Furthermore, we experimentally demonstrate the system's capability to learn operational skills, even in dynamic environments with interference, through pouring and pick-and-place tasks. Our code will be released soon.
Nonverbal Social Behavior Generation for Social Robots Using End-to-End Learning
Nov 02, 2022



To provide effective and enjoyable human-robot interaction, it is important for social robots to exhibit nonverbal behaviors, such as a handshake or a hug. However, the traditional approach of reproducing pre-coded motions allows users to easily predict the reaction of the robot, giving the impression that the robot is a machine rather than a real agent. Therefore, we propose a neural network architecture based on the Seq2Seq model that learns social behaviors from human-human interactions in an end-to-end manner. We adopted a generative adversarial network to prevent invalid pose sequences from occurring when generating long-term behavior. To verify the proposed method, experiments were performed using the humanoid robot Pepper in a simulated environment. Because it is difficult to determine success or failure in social behavior generation, we propose new metrics to calculate the difference between the generated behavior and the ground-truth behavior. We used these metrics to show how different network architectural choices affect the performance of behavior generation, and we compared the performance of learning multiple behaviors and that of learning a single behavior. We expect that our proposed method can be used not only with home service robots, but also for guide robots, delivery robots, educational robots, and virtual robots, enabling the users to enjoy and effectively interact with the robots.
VOTE400: A Speech Dataset to Study Voice Interface for Elderly-Care
Jan 20, 2021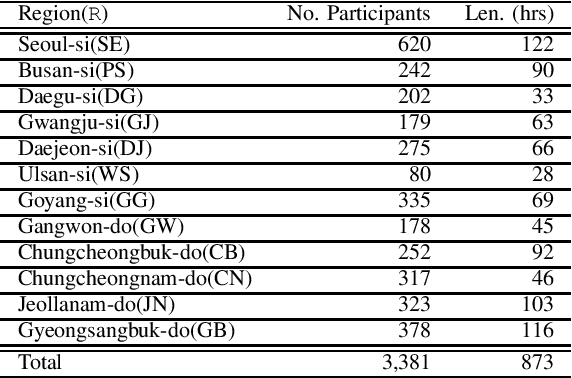
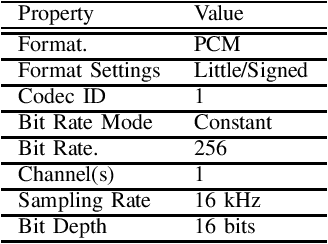
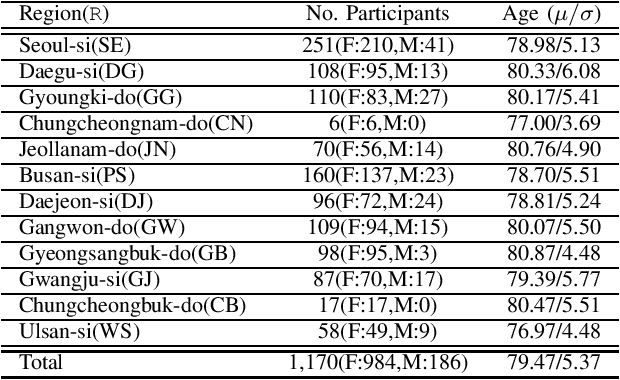
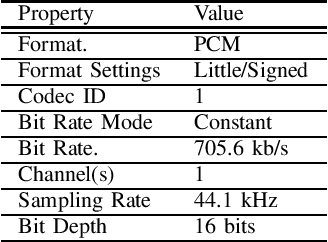
This paper introduces a large-scale Korean speech dataset, called VOTE400, that can be used for analyzing and recognizing voices of the elderly people. The dataset includes about 300 hours of continuous dialog speech and 100 hours of read speech, both recorded by the elderly people aged 65 years or over. A preliminary experiment showed that speech recognition system trained with VOTE400 can outperform conventional systems in speech recognition of elderly people's voice. This work is a multi-organizational effort led by ETRI and MINDs Lab Inc. for the purpose of advancing the speech recognition performance of the elderly-care robots.
Speech Gesture Generation from the Trimodal Context of Text, Audio, and Speaker Identity
Sep 04, 2020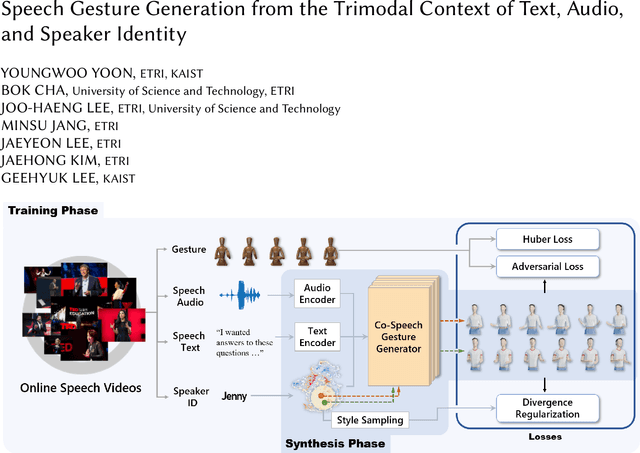
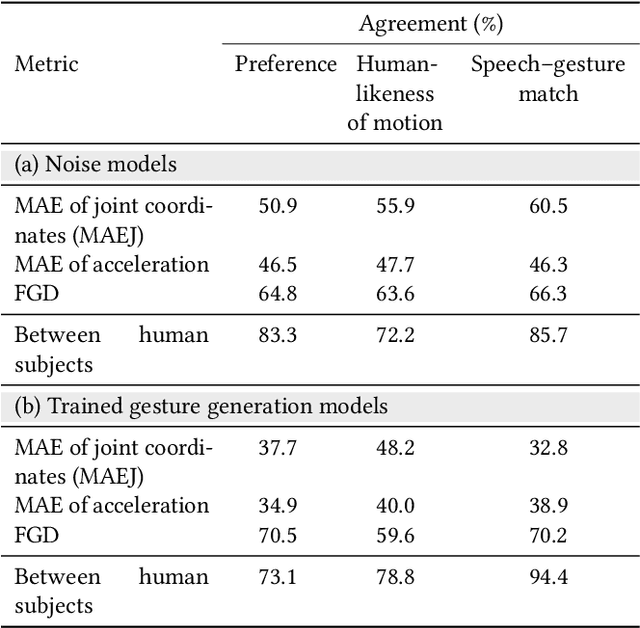
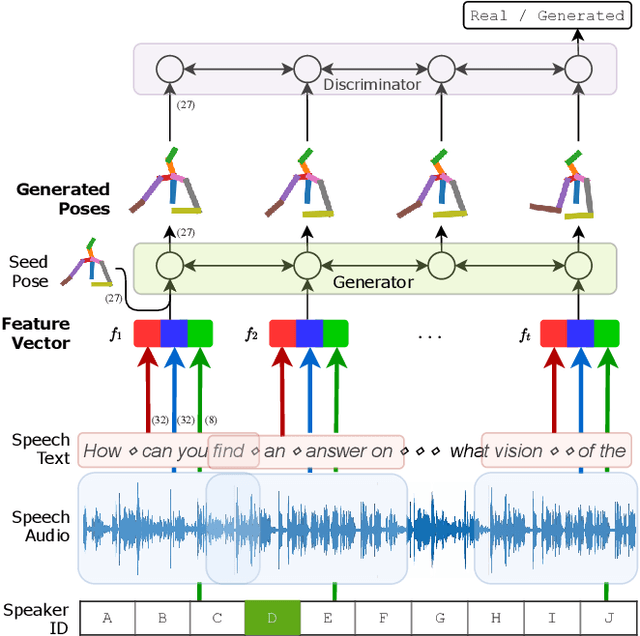

For human-like agents, including virtual avatars and social robots, making proper gestures while speaking is crucial in human--agent interaction. Co-speech gestures enhance interaction experiences and make the agents look alive. However, it is difficult to generate human-like gestures due to the lack of understanding of how people gesture. Data-driven approaches attempt to learn gesticulation skills from human demonstrations, but the ambiguous and individual nature of gestures hinders learning. In this paper, we present an automatic gesture generation model that uses the multimodal context of speech text, audio, and speaker identity to reliably generate gestures. By incorporating a multimodal context and an adversarial training scheme, the proposed model outputs gestures that are human-like and that match with speech content and rhythm. We also introduce a new quantitative evaluation metric for gesture generation models. Experiments with the introduced metric and subjective human evaluation showed that the proposed gesture generation model is better than existing end-to-end generation models. We further confirm that our model is able to work with synthesized audio in a scenario where contexts are constrained, and show that different gesture styles can be generated for the same speech by specifying different speaker identities in the style embedding space that is learned from videos of various speakers. All the code and data is available at https://github.com/ai4r/Gesture-Generation-from-Trimodal-Context.
AIR-Act2Act: Human-human interaction dataset for teaching non-verbal social behaviors to robots
Sep 04, 2020

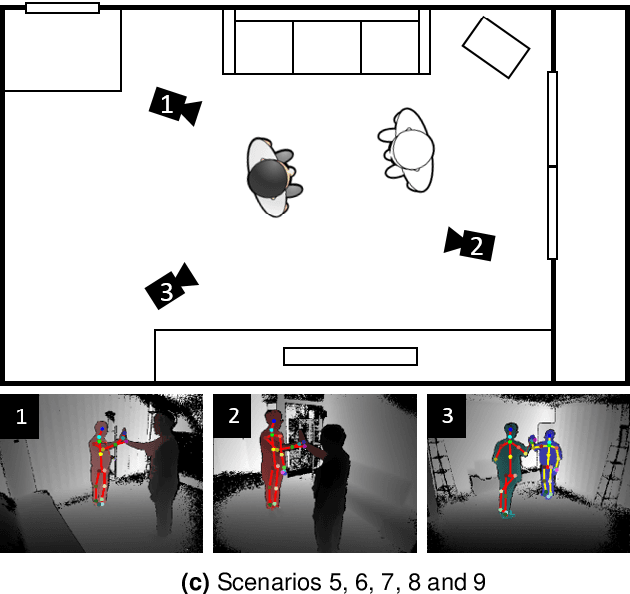
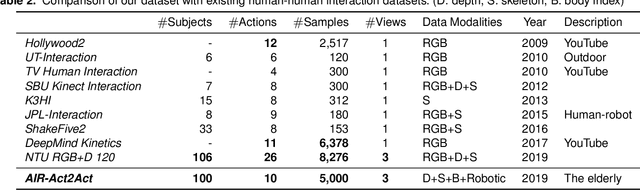
To better interact with users, a social robot should understand the users' behavior, infer the intention, and respond appropriately. Machine learning is one way of implementing robot intelligence. It provides the ability to automatically learn and improve from experience instead of explicitly telling the robot what to do. Social skills can also be learned through watching human-human interaction videos. However, human-human interaction datasets are relatively scarce to learn interactions that occur in various situations. Moreover, we aim to use service robots in the elderly-care domain; however, there has been no interaction dataset collected for this domain. For this reason, we introduce a human-human interaction dataset for teaching non-verbal social behaviors to robots. It is the only interaction dataset that elderly people have participated in as performers. We recruited 100 elderly people and two college students to perform 10 interactions in an indoor environment. The entire dataset has 5,000 interaction samples, each of which contains depth maps, body indexes and 3D skeletal data that are captured with three Microsoft Kinect v2 cameras. In addition, we provide the joint angles of a humanoid NAO robot which are converted from the human behavior that robots need to learn. The dataset and useful python scripts are available for download at https://github.com/ai4r/AIR-Act2Act. It can be used to not only teach social skills to robots but also benchmark action recognition algorithms.
ETRI-Activity3D: A Large-Scale RGB-D Dataset for Robots to Recognize Daily Activities of the Elderly
Mar 11, 2020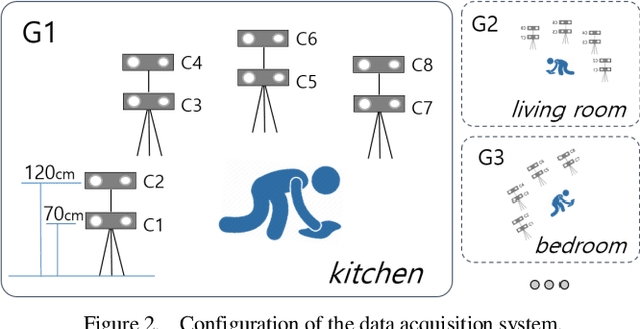
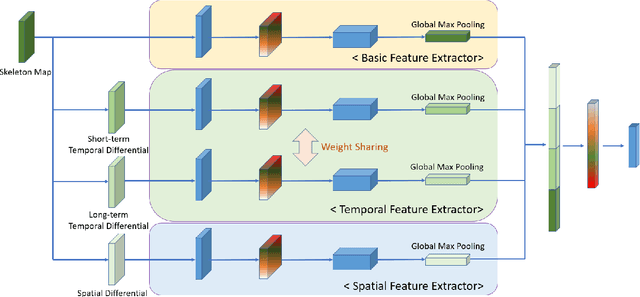
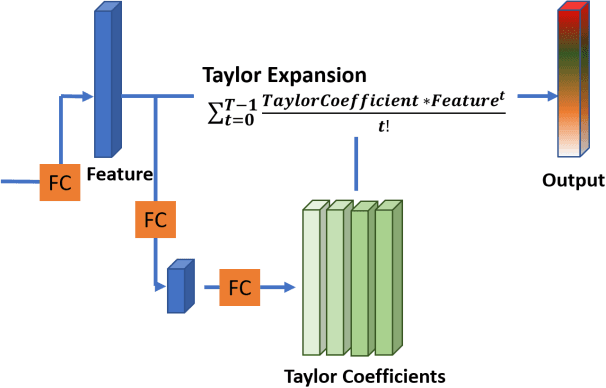
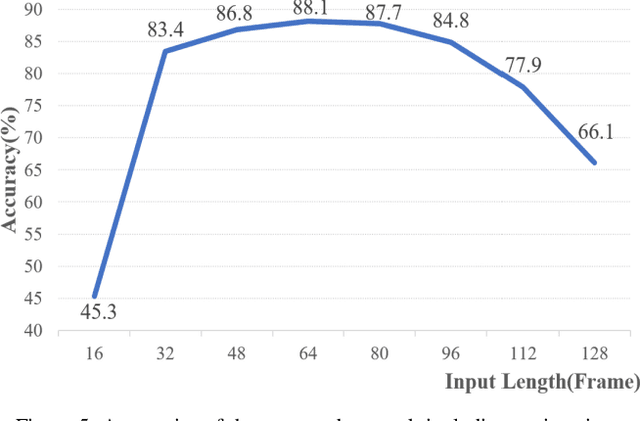
Deep learning, based on which many modern algorithms operate, is well known to be data-hungry. In particular, the datasets appropriate for the intended application are difficult to obtain. To cope with this situation, we introduce a new dataset called ETRI-Activity3D, focusing on the daily activities of the elderly in robot-view. The major characteristics of the new dataset are as follows: 1) practical action categories that are selected from the close observation of the daily lives of the elderly; 2) realistic data collection, which reflects the robot's working environment and service situations; and 3) a large-scale dataset that overcomes the limitations of the current 3D activity analysis benchmark datasets. The proposed dataset contains 112,620 samples including RGB videos, depth maps, and skeleton sequences. During the data acquisition, 100 subjects were asked to perform 55 daily activities. Additionally, we propose a novel network called four-stream adaptive CNN (FSA-CNN). The proposed FSA-CNN has three main properties: robustness to spatio-temporal variations, input-adaptive activation function, and extension of the conventional two-stream approach. In the experiment section, we confirmed the superiority of the proposed FSA-CNN using NTU RGB+D and ETRI-Activity3D. Further, the domain difference between both groups of age was verified experimentally. Finally, the extension of FSA-CNN to deal with the multimodal data was investigated.
Robots Learn Social Skills: End-to-End Learning of Co-Speech Gesture Generation for Humanoid Robots
Oct 30, 2018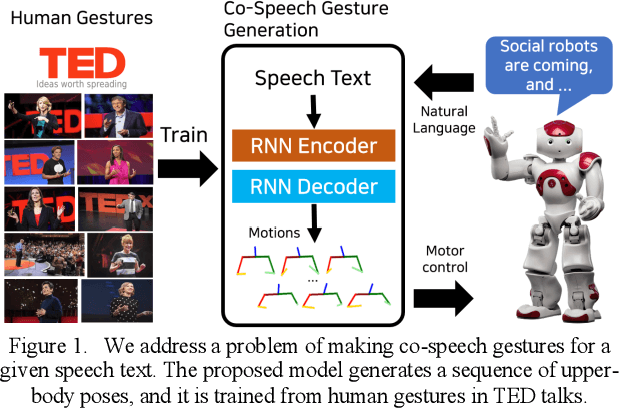

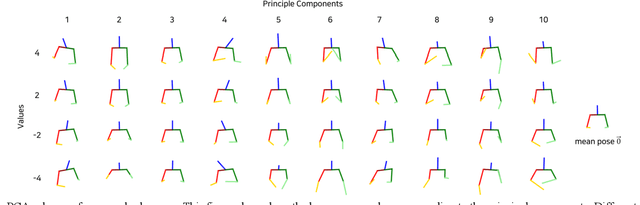
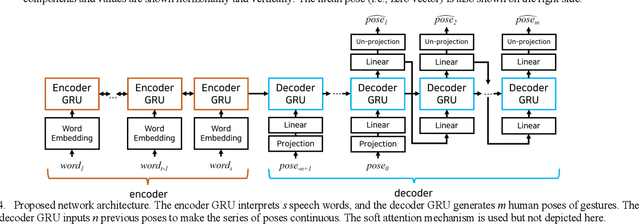
Co-speech gestures enhance interaction experiences between humans as well as between humans and robots. Existing robots use rule-based speech-gesture association, but this requires human labor and prior knowledge of experts to be implemented. We present a learning-based co-speech gesture generation that is learned from 52 h of TED talks. The proposed end-to-end neural network model consists of an encoder for speech text understanding and a decoder to generate a sequence of gestures. The model successfully produces various gestures including iconic, metaphoric, deictic, and beat gestures. In a subjective evaluation, participants reported that the gestures were human-like and matched the speech content. We also demonstrate a co-speech gesture with a NAO robot working in real time.