 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATCHFed: Efficient Unlabeled Data Utilization for Semi-Supervised Federated Learning in Limited Labels Environments
Nov 19, 2025Federated learning is a promising paradigm that utilizes distributed client resources while preserving data privacy. Most existing FL approaches assume clients possess labeled data, however, in real-world scenarios, client-side labels are often unavailable. Semi-supervised Federated learning, where only the server holds labeled data, addresses this issue. However, it experiences significant performance degradation as the number of labeled data decreases. To tackle this problem, we propose \textit{CATCHFed}, which introduces client-aware adaptive thresholds considering class difficulty, hybrid thresholds to enhance pseudo-label quality, and utilizes unpseudo-labeled data for consistency regularization. Extensive experiments across various datasets and configurations demonstrate that CATCHFed effectively leverages unlabeled client data, achieving superior performance even in extremely limited-label settings.
GC-Fed: Gradient Centralized Federated Learning with Partial Client Participation
Mar 17, 2025Multi-source information fusion (MSIF) leverages diverse data streams to enhance decision-making, situational awareness, and system resilience. Federated Learning (FL) enables MSIF while preserving privacy but suffers from client drift under high data heterogeneity, leading to performance degradation. Traditional mitigation strategies rely on reference-based gradient adjustments, which can be unstable in partial participation settings. To address this, we propose Gradient Centralized Federated Learning (GC-Fed), a reference-free gradient correction method inspired by Gradient Centralization (GC). We introduce Local GC and Global GC, applying GC during local training and global aggregation, respectively. Our hybrid GC-Fed approach selectively applies GC at the feature extraction layer locally and at the classifier layer globally, improving training stability and model performance. Theoretical analysis and empirical results demonstrate that GC-Fed mitigates client drift and achieves state-of-the-art accuracy gains of up to 20% in heterogeneous settings.
FedShift: Tackling Dual Heterogeneity Problem of Federated Learning via Weight Shift Aggregation
Feb 02, 2024Federated Learning (FL) offers a compelling method for training machine learning models with a focus on preserving data privacy. The presence of system heterogeneity and statistical heterogeneity, recognized challenges in FL, arises from the diversity of client hardware, network, and dataset distribution. This diversity can critically affect the training pace and the performance of models. While many studies address either system or statistical heterogeneity by introducing communication-efficient or stable convergence algorithms, addressing these challenges in isolation often leads to compromises due to unaddressed heterogeneity. In response, this paper introduces FedShift, a novel algorithm designed to enhance both the training speed and the models' accuracy in a dual heterogeneity scenario. Our solution can improve client engagement through quantization and mitigate the adverse effects on performance typically associated with quantization by employing a shifting technique. This technique has proven to enhance accuracy by an average of 3.9% in diverse heterogeneity environments.
Application of End-to-End Deep Learning in Wireless Communications Systems
Aug 07, 2018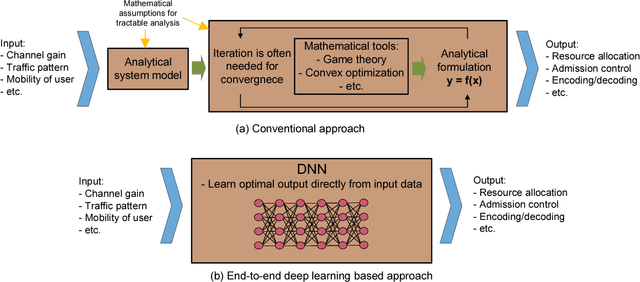
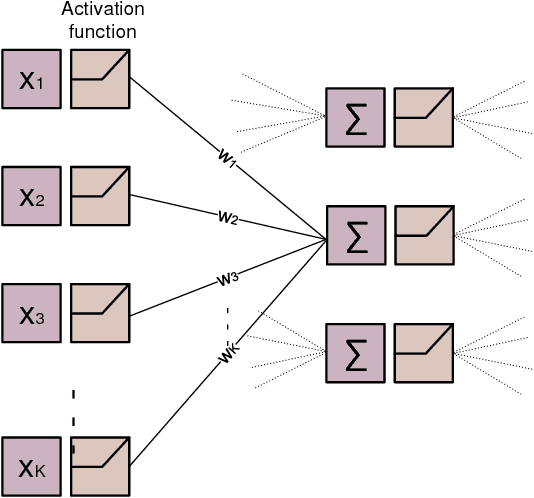
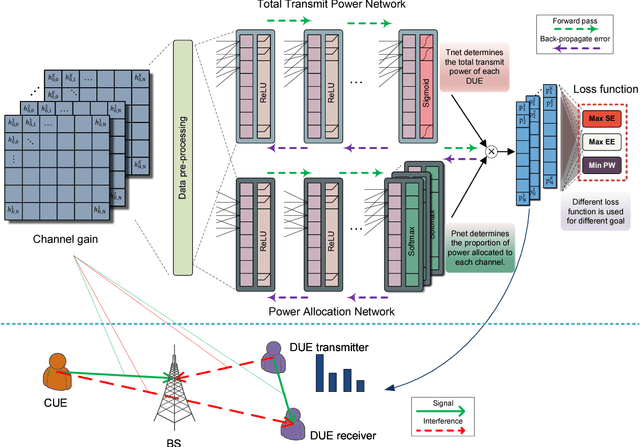
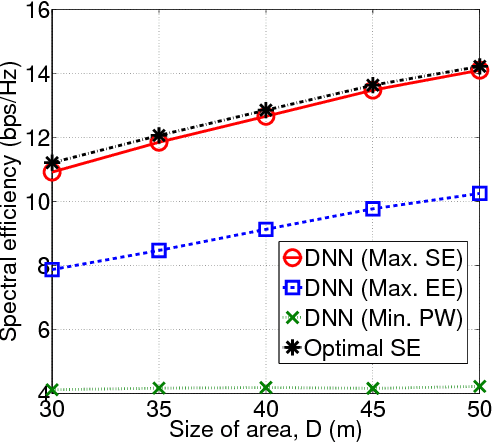
Deep learning is a potential paradigm changer for the design of wireless communications systems (WCS), from conventional handcrafted schemes based on sophisticated mathematical models with assumptions to autonomous schemes based on the end-to-end deep learning using a large number of data. In this article, we present a basic concept of the deep learning and its application to WCS by investigating the resource allocation (RA) scheme based on a deep neural network (DNN) where multiple goals with various constraints can be satisfied through the end-to-end deep learning. Especially, the optimality and feasibility of the DNN based RA are verified through simulation. Then, we discuss the technical challenges regarding the application of deep learning in WCS.