 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleash the Potential of Long Semantic IDs for Generative Recommendation
Feb 14, 2026Semantic ID-based generative recommendation represents items as sequences of discrete tokens, but it inherently faces a trade-off between representational expressiveness and computational efficiency. Residual Quantization (RQ)-based approaches restrict semantic IDs to be short to enable tractable sequential modeling, while Optimized Product Quantization (OPQ)-based methods compress long semantic IDs through naive rigid aggregation, inevitably discarding fine-grained semantic information. To resolve this dilemma, we propose ACERec, a novel framework that decouples the granularity gap between fine-grained tokenization and efficient sequential modeling. It employs an Attentive Token Merger to distill long expressive semantic tokens into compact latents and introduces a dedicated Intent Token serving as a dynamic prediction anchor. To capture cohesive user intents, we guide the learning process via a dual-granularity objective, harmonizing fine-grained token prediction with global item-level semantic alignment. Extensive experiments on six real-world benchmarks demonstrate that ACERec consistently outperforms state-of-the-art baselines, achieving an average improvement of 14.40\% in NDCG@10, effectively reconciling semantic expressiveness and computational efficiency.
Rethinking Gradient Operator for Exposing AI-enabled Face Forgeries
May 02, 2022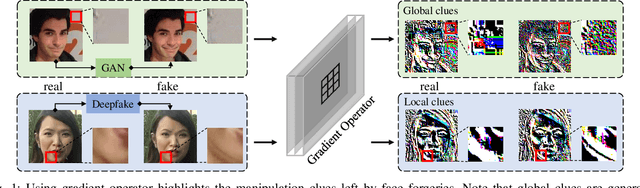
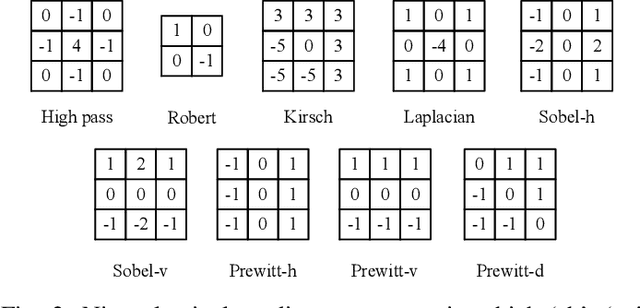
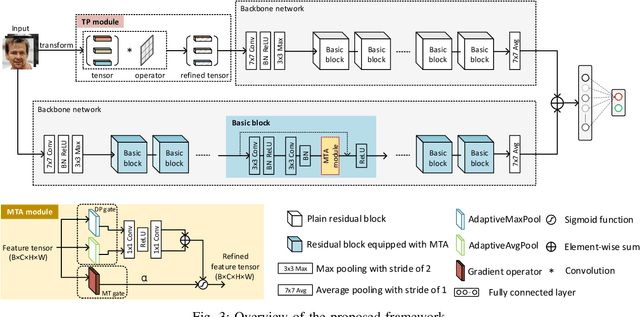

For image forensics, convolutional neural networks (CNNs) tend to learn content features rather than subtle manipulation traces, which limits forensic performance. Existing methods predominantly solve the above challenges by following a general pipeline, that is, subtracting the original pixel value from the predicted pixel value to make CNNs pay attention to the manipulation traces. However, due to the complicated learning mechanism, these methods may bring some unnecessary performance losses. In this work, we rethink the advantages of gradient operator in exposing face forgery, and design two plug-and-play modules by combining gradient operator with CNNs, namely tensor pre-processing (TP) and manipulation trace attention (MTA) module. Specifically, TP module refines the feature tensor of each channel in the network by gradient operator to highlight the manipulation traces and improve the feature representation. Moreover, MTA module considers two dimensions, namely channel and manipulation traces, to force the network to learn the distribution of manipulation traces. These two modules can be seamlessly integrated into CNNs for end-to-end training. Experiments show that the proposed network achieves better results than prior works on five public datasets. Especially, TP module greatly improves the accuracy by at least 4.60% compared with the existing pre-processing module only via simple tensor refinement. The code is available at: https://github.com/EricGzq/GocNet-pytorch.