 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAM: Merging Improves Pruning of Experts in LLMs
Apr 06, 2026Mixture-of-Experts (MoE) large language models (LLMs) are among the top-performing architectures. The largest models, often with hundreds of billions of parameters, pose significant memory challenges for deployment. Traditional approaches to reduce memory requirements include weight pruning and quantization. Motivated by the Router-weighted Expert Activation Pruning (REAP) that prunes experts, we propose a novel method, Router-weighted Expert Activation Merging (REAM). Instead of removing experts, REAM groups them and merges their weights, better preserving original performance. We evaluate REAM against REAP and other baselines across multiple MoE LLMs on diverse multiple-choice (MC) question answering and generative (GEN) benchmarks. Our results reveal a trade-off between MC and GEN performance that depends on the mix of calibration data. By controlling the mix of general, math and coding data, we examine the Pareto frontier of this trade-off and show that REAM often outperforms the baselines and in many cases is comparable to the original uncompressed models.
Adaptable Multi-Domain Language Model for Transformer ASR
Aug 14, 2020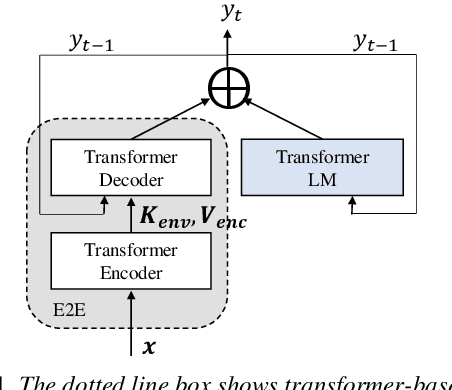
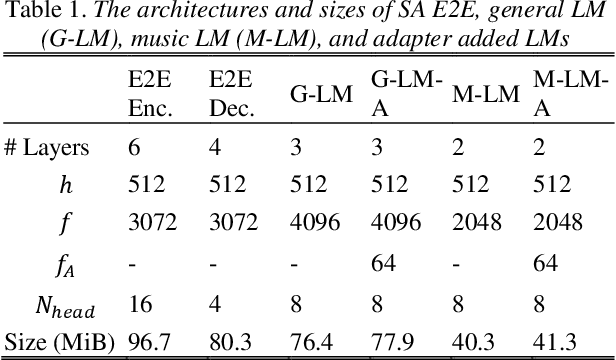
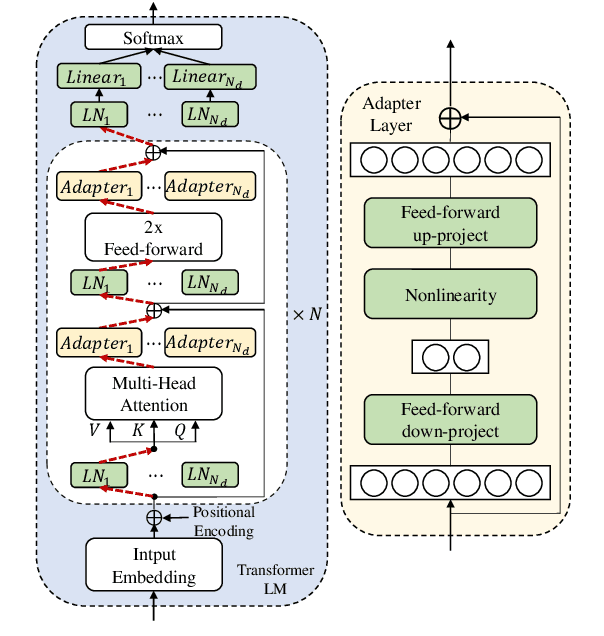
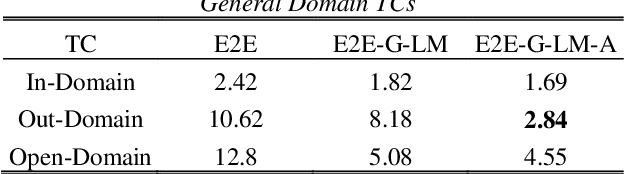
We propose an adapter based multi-domain Transformer based language model (LM) for Transformer ASR. The model consists of a big size common LM and small size adapters. The model can perform multi-domain adaptation with only the small size adapters and its related layers. The proposed model can reuse the full fine-tuned LM which is fine-tuned using all layers of an original model. The proposed LM can be expanded to new domains by adding about 2% of parameters for a first domain and 13% parameters for after second domain. The proposed model is also effective in reducing the model maintenance cost because it is possible to omit the costly and time-consuming common LM pre-training process. Using proposed adapter based approach, we observed that a general LM with adapter can outperform a dedicated music domain LM in terms of word error rate (WER).