 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Hardware/Software Co-Design of Neural Accelerators
Oct 05, 2020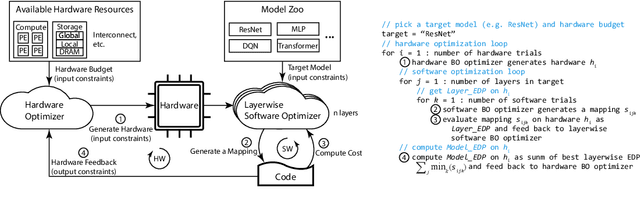
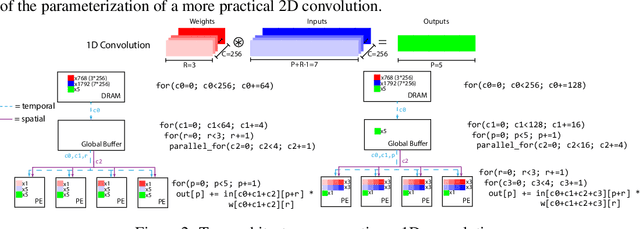
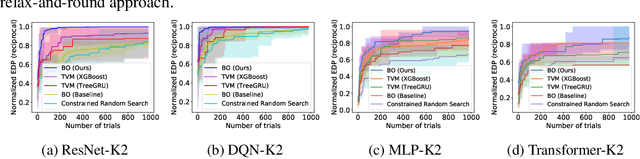
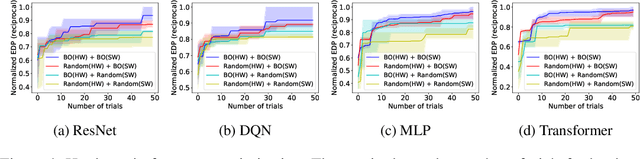
The use of deep learning has grown at an exponential rate, giving rise to numerous specialized hardware and software systems for deep learning. Because the design space of deep learning software stacks and hardware accelerators is diverse and vast, prior work considers software optimizations separately from hardware architectures, effectively reducing the search space. Unfortunately, this bifurcated approach means that many profitable design points are never explored. This paper instead casts the problem as hardware/software co-design, with the goal of automatically identifying desirable points in the joint design space. The key to our solution is a new constrained Bayesian optimization framework that avoids invalid solutions by exploiting the highly constrained features of this design space, which are semi-continuous/semi-discrete. We evaluate our optimization framework by applying it to a variety of neural models, improving the energy-delay product by 18% (ResNet) and 40% (DQN) over hand-tuned state-of-the-art systems, as well as demonstrating strong results on other neural network architectures, such as MLPs and Transformers.
An Imitation Learning Approach for Cache Replacement
Jul 09, 2020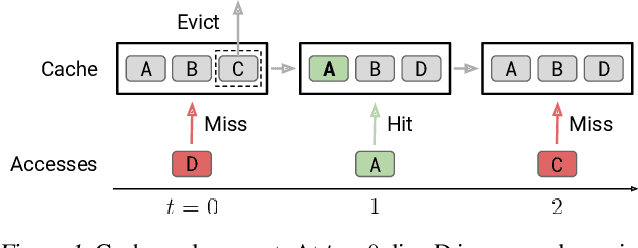
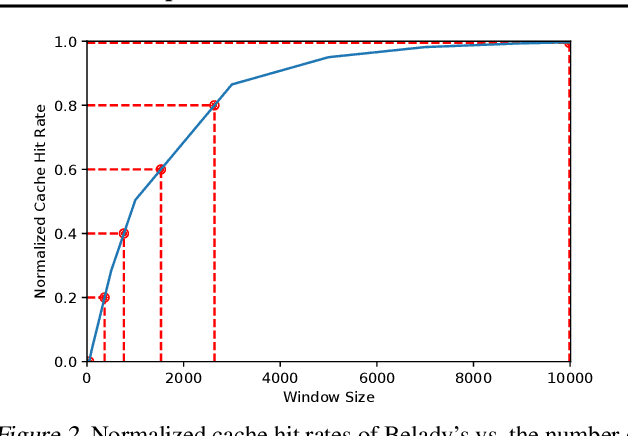
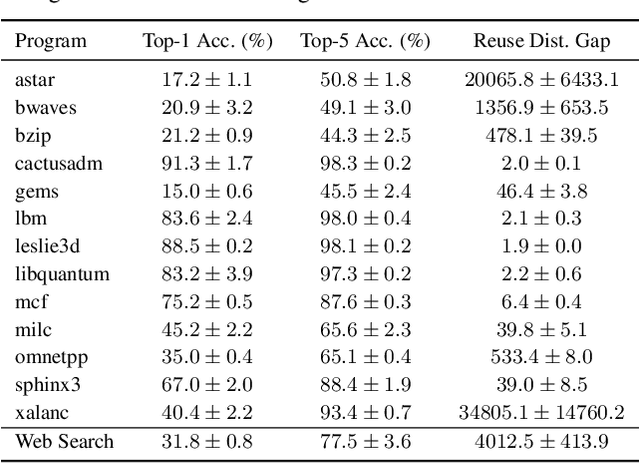
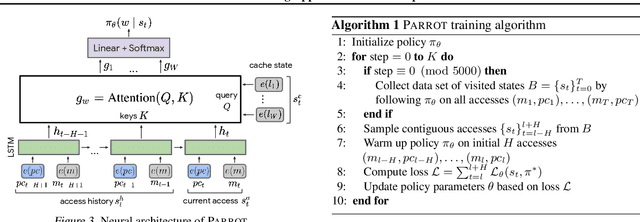
Program execution speed critically depends on increasing cache hits, as cache hits are orders of magnitude faster than misses. To increase cache hits, we focus on the problem of cache replacement: choosing which cache line to evict upon inserting a new line. This is challenging because it requires planning far ahead and currently there is no known practical solution. As a result, current replacement policies typically resort to heuristics designed for specific common access patterns, which fail on more diverse and complex access patterns. In contrast, we propose an imitation learning approach to automatically learn cache access patterns by leveraging Belady's, an oracle policy that computes the optimal eviction decision given the future cache accesses. While directly applying Belady's is infeasible since the future is unknown, we train a policy conditioned only on past accesses that accurately approximates Belady's even on diverse and complex access patterns, and call this approach Parrot. When evaluated on 13 of the most memory-intensive SPEC applications, Parrot increases cache miss rates by 20% over the current state of the art. In addition, on a large-scale web search benchmark, Parrot increases cache hit rates by 61% over a conventional LRU policy. We release a Gym environment to facilitate research in this area, as data is plentiful, and further advancements can have significant real-world impact.
Neural Execution Engines: Learning to Execute Subroutines
Jun 23, 2020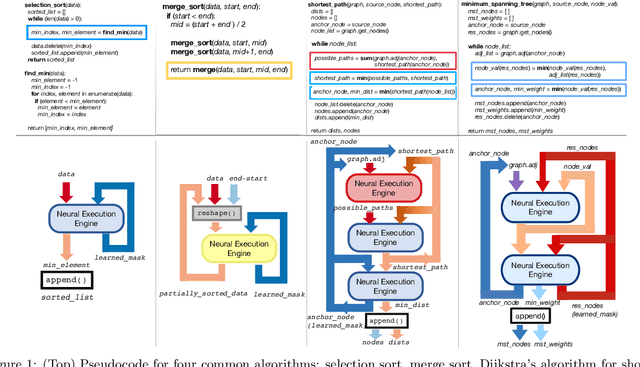
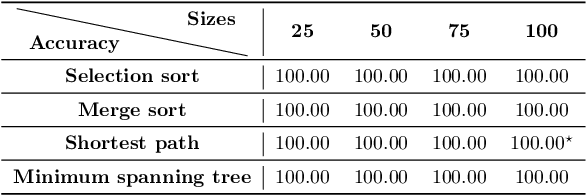
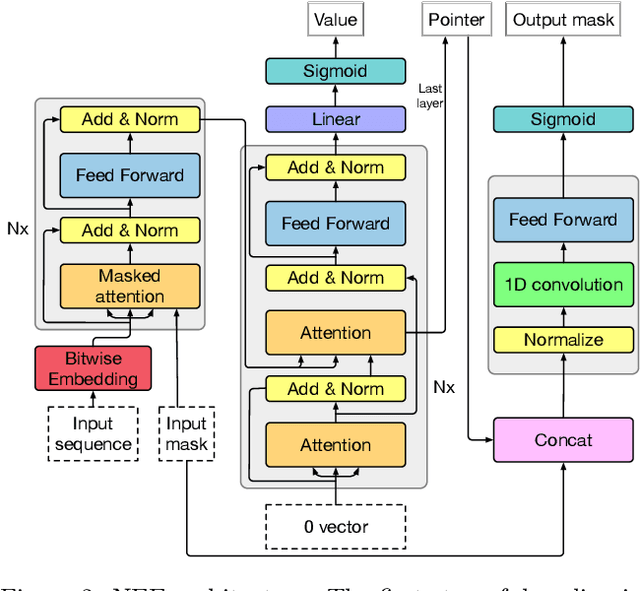
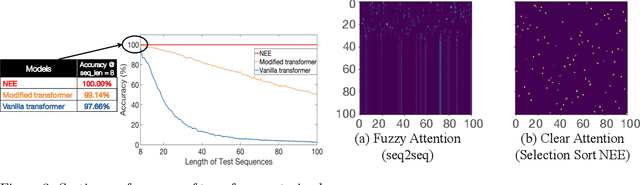
A significant effort has been made to train neural networks that replicate algorithmic reasoning, but they often fail to learn the abstract concepts underlying these algorithms. This is evidenced by their inability to generalize to data distributions that are outside of their restricted training sets, namely larger inputs and unseen data. We study these generalization issues at the level of numerical subroutines that comprise common algorithms like sorting, shortest paths, and minimum spanning trees. First, we observe that transformer-based sequence-to-sequence models can learn subroutines like sorting a list of numbers, but their performance rapidly degrades as the length of lists grows beyond those found in the training set. We demonstrate that this is due to attention weights that lose fidelity with longer sequences, particularly when the input numbers are numerically similar. To address the issue, we propose a learned conditional masking mechanism, which enables the model to strongly generalize far outside of its training range with near-perfect accuracy on a variety of algorithms. Second, to generalize to unseen data, we show that encoding numbers with a binary representation leads to embeddings with rich structure once trained on downstream tasks like addition or multiplication. This allows the embedding to handle missing data by faithfully interpolating numbers not seen during training.
Learning Execution through Neural Code Fusion
Jun 17, 2019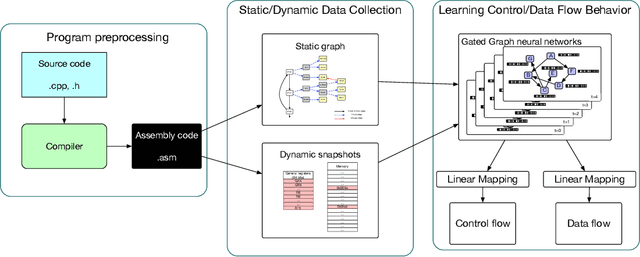
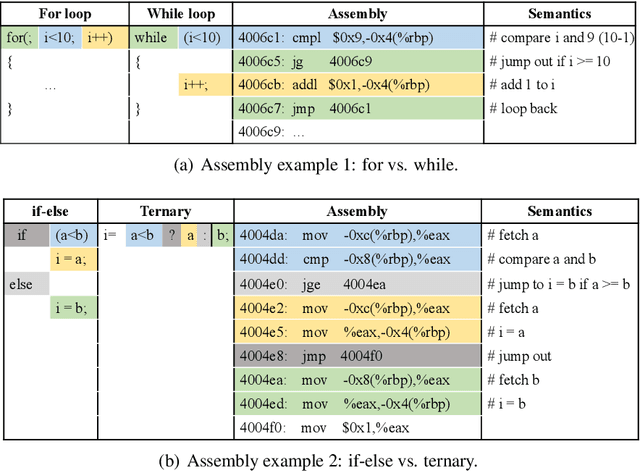
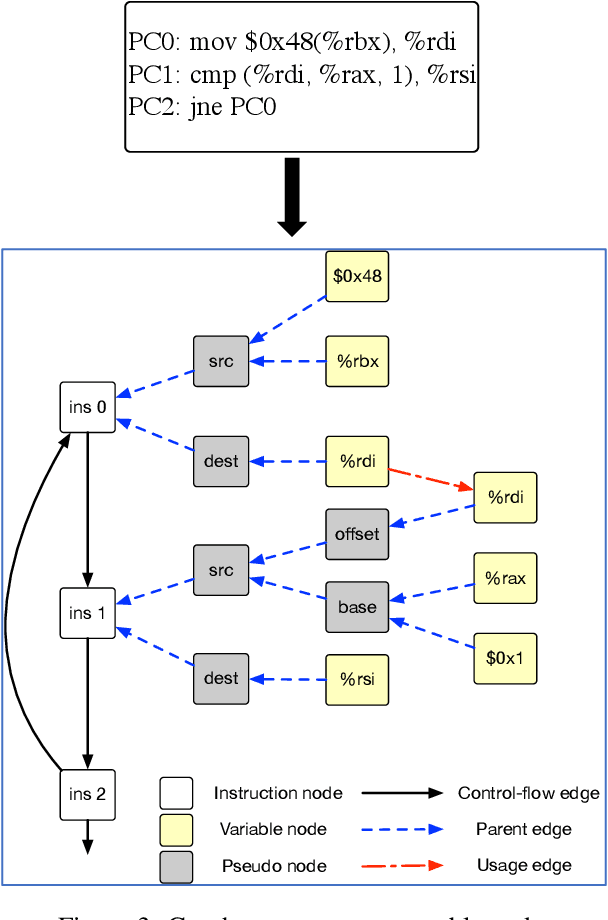
As the performance of computer systems stagnates due to the end of Moore's Law, there is a need for new models that can understand and optimize the execution of general purpose code. While there is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of source code, these representations do not understand how code dynamically executes. In this work, we propose a new approach to use GNNs to learn fused representations of general source code and its execution. Our approach defines a multi-task GNN over low-level representations of source code and program state (i.e., assembly code and dynamic memory states), converting complex source code constructs and complex data structures into a simpler, more uniform format. We show that this leads to improved performance over similar methods that do not use execution and it opens the door to applying GNN models to new tasks that would not be feasible from static code alone. As an illustration of this, we apply the new model to challenging dynamic tasks (branch prediction and prefetching) from the SPEC CPU benchmark suite, outperforming the state-of-the-art by 26% and 45% respectively. Moreover, we use the learned fused graph embeddings to demonstrate transfer learning with high performance on an indirectly related task (algorithm classification).
Learning Memory Access Patterns
Mar 06, 2018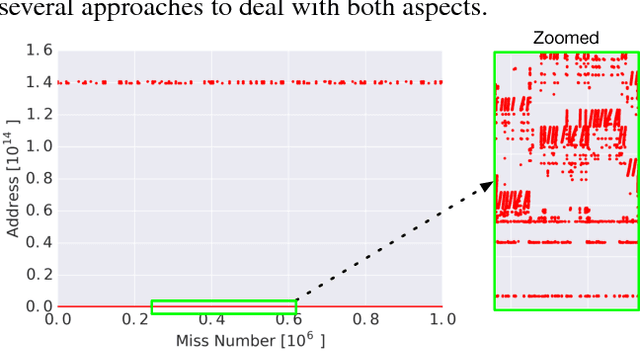
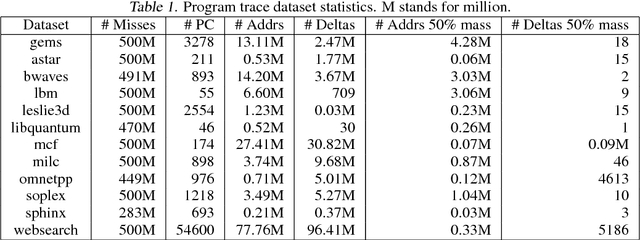
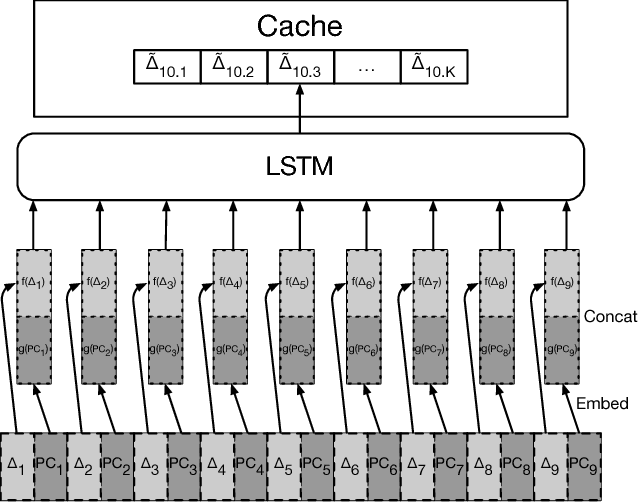
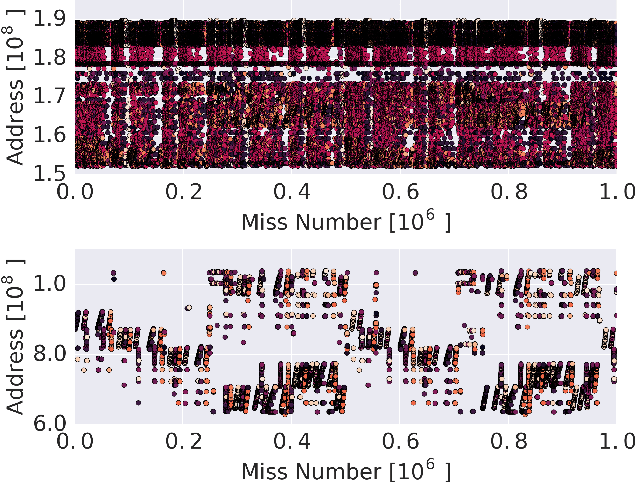
The explosion in workload complexity and the recent slow-down in Moore's law scaling call for new approaches towards efficient computing. Researchers are now beginning to use recent advances in machine learning in software optimizations, augmenting or replacing traditional heuristics and data structures. However, the space of machine learning for computer hardware architecture is only lightly explored. In this paper, we demonstrate the potential of deep learning to address the von Neumann bottleneck of memory performance. We focus on the critical problem of learning memory access patterns, with the goal of constructing accurate and efficient memory prefetchers. We relate contemporary prefetching strategies to n-gram models in natural language processing, and show how recurrent neural networks can serve as a drop-in replacement. On a suite of challenging benchmark datasets, we find that neural networks consistently demonstrate superior performance in terms of precision and recall. This work represents the first step towards practical neural-network based prefetching, and opens a wide range of exciting directions for machine learning in computer architecture research.