 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNever guess what I heard Rumor Detection in Finnish News: a Dataset and a Baseline
Jun 07, 2021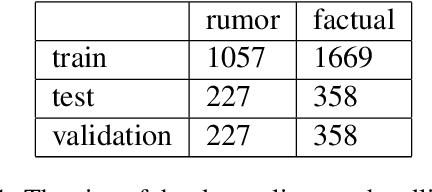

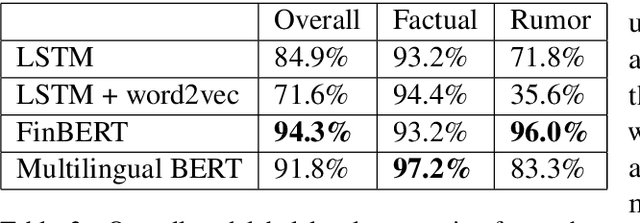
This study presents a new dataset on rumor detection in Finnish language news headlines. We have evaluated two different LSTM based models and two different BERT models, and have found very significant differences in the results. A fine-tuned FinBERT reaches the best overall accuracy of 94.3% and rumor label accuracy of 96.0% of the time. However, a model fine-tuned on Multilingual BERT reaches the best factual label accuracy of 97.2%. Our results suggest that the performance difference is due to a difference in the original training data. Furthermore, we find that a regular LSTM model works better than one trained with a pretrained word2vec model. These findings suggest that more work needs to be done for pretrained models in Finnish language as they have been trained on small and biased corpora.
Neural Morphology Dataset and Models for Multiple Languages, from the Large to the Endangered
May 26, 2021


We train neural models for morphological analysis, generation and lemmatization for morphologically rich languages. We present a method for automatically extracting substantially large amount of training data from FSTs for 22 languages, out of which 17 are endangered. The neural models follow the same tagset as the FSTs in order to make it possible to use them as fallback systems together with the FSTs. The source code, models and datasets have been released on Zenodo.
!Qué maravilla! Multimodal Sarcasm Detection in Spanish: a Dataset and a Baseline
May 12, 2021


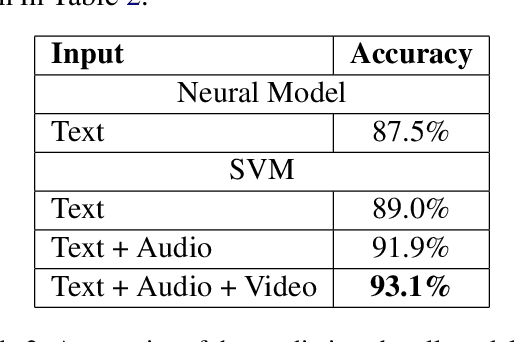
We construct the first ever multimodal sarcasm dataset for Spanish. The audiovisual dataset consists of sarcasm annotated text that is aligned with video and audio. The dataset represents two varieties of Spanish, a Latin American variety and a Peninsular Spanish variety, which ensures a wider dialectal coverage for this global language. We present several models for sarcasm detection that will serve as baselines in the future research. Our results show that results with text only (89%) are worse than when combining text with audio (91.9%). Finally, the best results are obtained when combining all the modalities: text, audio and video (93.1%).
The Great Misalignment Problem in Human Evaluation of NLP Methods
Apr 12, 2021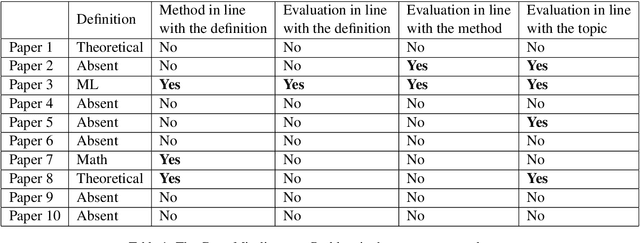
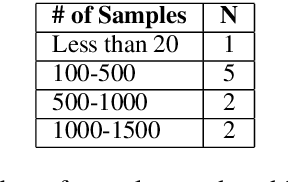
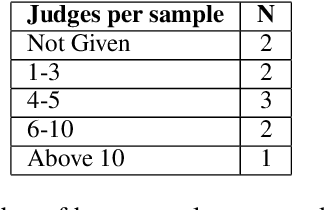
We outline the Great Misalignment Problem in natural language processing research, this means simply that the problem definition is not in line with the method proposed and the human evaluation is not in line with the definition nor the method. We study this misalignment problem by surveying 10 randomly sampled papers published in ACL 2020 that report results with human evaluation. Our results show that only one paper was fully in line in terms of problem definition, method and evaluation. Only two papers presented a human evaluation that was in line with what was modeled in the method. These results highlight that the Great Misalignment Problem is a major one and it affects the validity and reproducibility of results obtained by a human evaluation.
From Plenipotentiary to Puddingless: Users and Uses of New Words in Early English Letters
Mar 17, 2021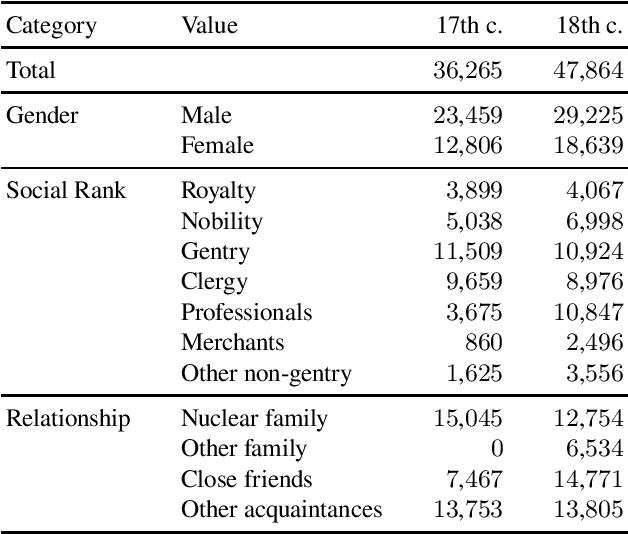

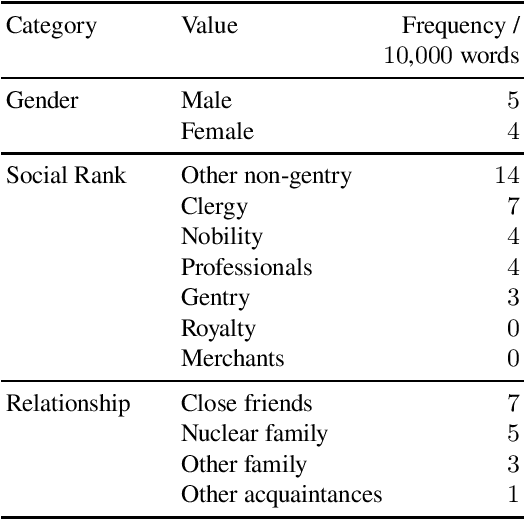
We study neologism use in two samples of early English correspondence, from 1640--1660 and 1760--1780. Of especial interest are the early adopters of new vocabulary, the social groups they represent, and the types and functions of their neologisms. We describe our computer-assisted approach and note the difficulties associated with massive variation in the corpus. Our findings include that while male letter-writers tend to use neologisms more frequently than women, the eighteenth century seems to have provided more opportunities for women and the lower ranks to participate in neologism use as well. In both samples, neologisms most frequently occur in letters written between close friends, which could be due to this less stable relationship triggering more creative language use. In the seventeenth-century sample, we observe the influence of the English Civil War, while the eighteenth-century sample appears to reflect the changing functions of letter-writing, as correspondence is increasingly being used as a tool for building and maintaining social relationships in addition to exchanging information.
Endangered Languages are not Low-Resourced!
Mar 17, 2021
The term low-resourced has been tossed around in the field of natural language processing to a degree that almost any language that is not English can be called "low-resourced"; sometimes even just for the sake of making a mundane or mediocre paper appear more interesting and insightful. In a field where English is a synonym for language and low-resourced is a synonym for anything not English, calling endangered languages low-resourced is a bit of an overstatement. In this paper, I inspect the relation of the endangered with the low-resourced from my own experiences.
Speech Recognition for Endangered and Extinct Samoyedic languages
Dec 09, 2020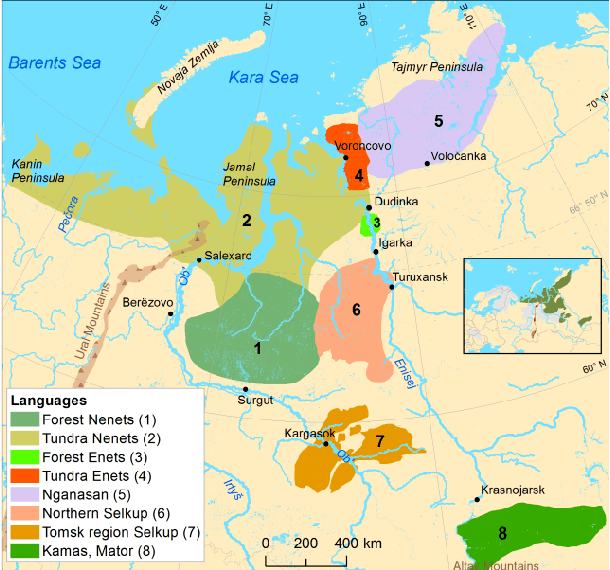
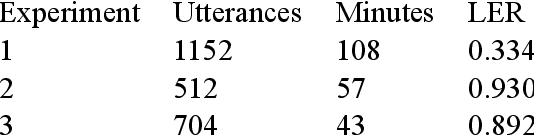

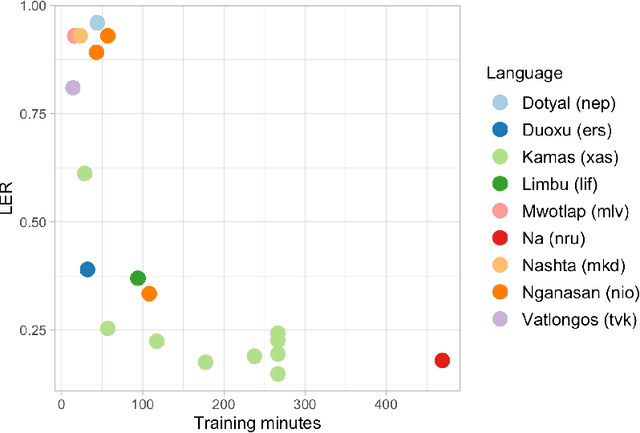
Our study presents a series of experiments on speech recognition with endangered and extinct Samoyedic languages, spoken in Northern and Southern Siberia. To best of our knowledge, this is the first time a functional ASR system is built for an extinct language. We achieve with Kamas language a Label Error Rate of 15\%, and conclude through careful error analysis that this quality is already very useful as a starting point for refined human transcriptions. Our results with related Nganasan language are more modest, with best model having the error rate of 33\%. We show, however, through experiments where Kamas training data is enlarged incrementally, that Nganasan results are in line with what is expected under low-resource circumstances of the language. Based on this, we provide recommendations for scenarios in which further language documentation or archive processing activities could benefit from modern ASR technology. All training data and processing scripts haven been published on Zenodo with clear licences to ensure further work in this important topic.
Normalization of Different Swedish Dialects Spoken in Finland
Dec 09, 2020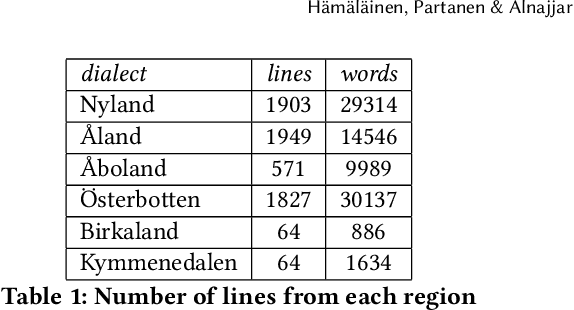
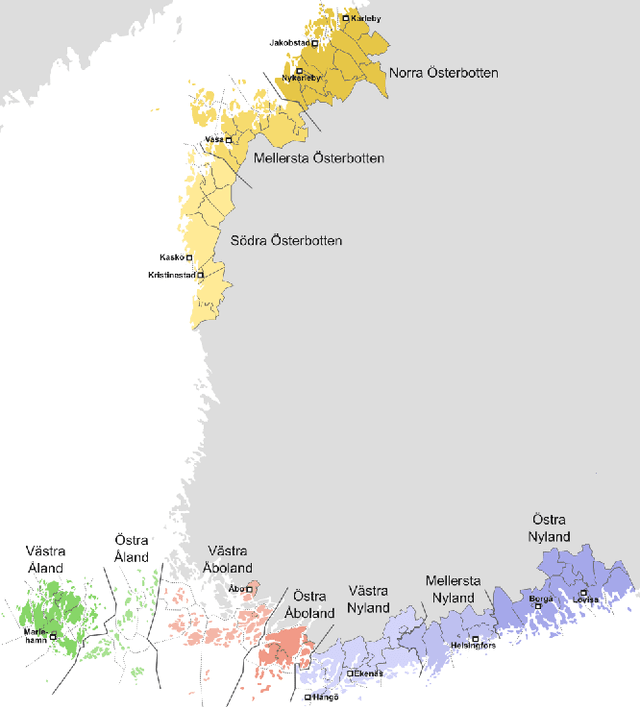

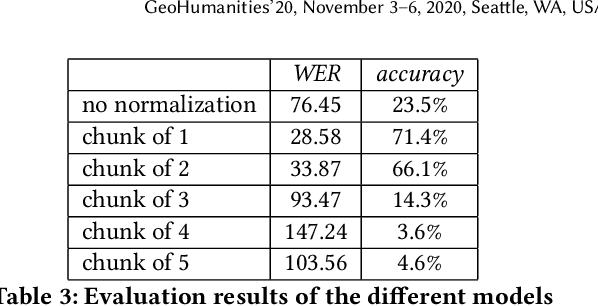
Our study presents a dialect normalization method for different Finland Swedish dialects covering six regions. We tested 5 different models, and the best model improved the word error rate from 76.45 to 28.58. Contrary to results reported in earlier research on Finnish dialects, we found that training the model with one word at a time gave best results. We believe this is due to the size of the training data available for the model. Our models are accessible as a Python package. The study provides important information about the adaptability of these methods in different contexts, and gives important baselines for further study.
Ve'rdd. Narrowing the Gap between Paper Dictionaries, Low-Resource NLP and Community Involvement
Dec 04, 2020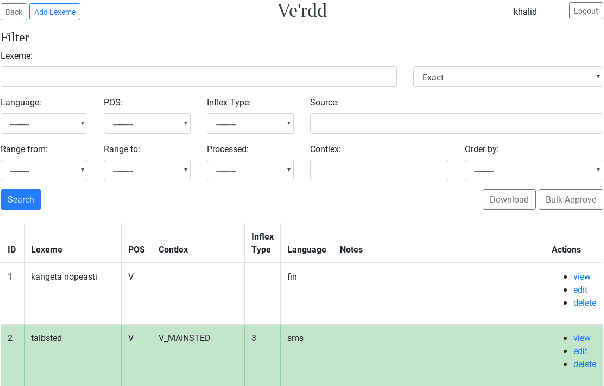
We present an open-source online dictionary editing system, Ve'rdd, that offers a chance to re-evaluate and edit grassroots dictionaries that have been exposed to multiple amateur editors. The idea is to incorporate community activities into a state-of-the-art finite-state language description of a seriously endangered minority language, Skolt Sami. Problems involve getting the community to take part in things above the pencil-and-paper level. At times, it seems that the native speakers and the dictionary oriented are lacking technical understanding to utilize the infrastructures which might make their work more meaningful in the future, i.e. multiple reuse of all of their input. Therefore, our system integrates with the existing tools and infrastructures for Uralic language masking the technical complexities behind a user-friendly UI.
An Unsupervised method for OCR Post-Correction and Spelling Normalisation for Finnish
Nov 06, 2020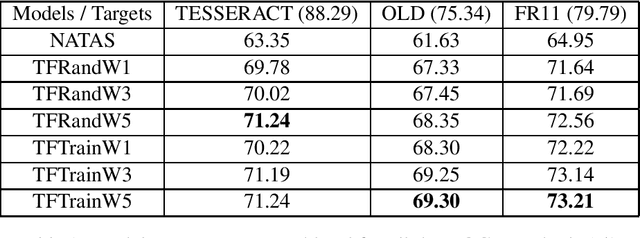
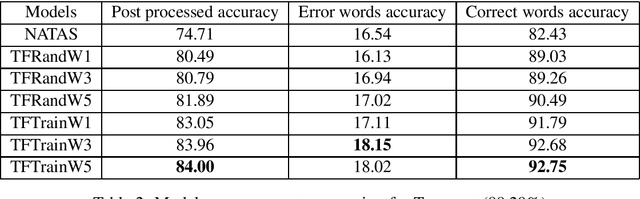
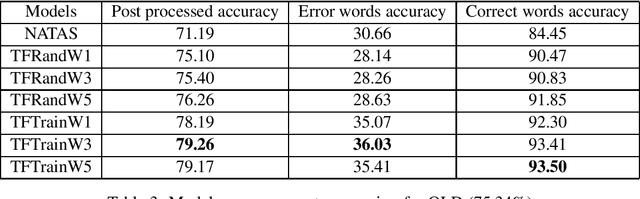
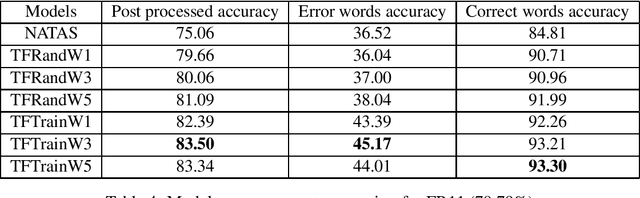
Historical corpora are known to contain errors introduced by OCR (optical character recognition) methods used in the digitization process, often said to be degrading the performance of NLP systems. Correcting these errors manually is a time-consuming process and a great part of the automatic approaches have been relying on rules or supervised machine learning. We build on previous work on fully automatic unsupervised extraction of parallel data to train a character-based sequence-to-sequence NMT (neural machine translation) model to conduct OCR error correction designed for English, and adapt it to Finnish by proposing solutions that take the rich morphology of the language into account. Our new method shows increased performance while remaining fully unsupervised, with the added benefit of spelling normalisation. The source code and models are available on GitHub and Zenodo.