 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformer attention alignment with human visual perception in aesthetic object evaluation
Jul 23, 2025Visual attention mechanisms play a crucial role in human perception and aesthetic evaluation. Recent advances in Vision Transformers (ViTs) have demonstrated remarkable capabilities in computer vision tasks, yet their alignment with human visual attention patterns remains underexplored, particularly in aesthetic contexts. This study investigates the correlation between human visual attention and ViT attention mechanisms when evaluating handcrafted objects. We conducted an eye-tracking experiment with 30 participants (9 female, 21 male, mean age 24.6 years) who viewed 20 artisanal objects comprising basketry bags and ginger jars. Using a Pupil Labs eye-tracker, we recorded gaze patterns and generated heat maps representing human visual attention. Simultaneously, we analyzed the same objects using a pre-trained ViT model with DINO (Self-DIstillation with NO Labels), extracting attention maps from each of the 12 attention heads. We compared human and ViT attention distributions using Kullback-Leibler divergence across varying Gaussian parameters (sigma=0.1 to 3.0). Statistical analysis revealed optimal correlation at sigma=2.4 +-0.03, with attention head #12 showing the strongest alignment with human visual patterns. Significant differences were found between attention heads, with heads #7 and #9 demonstrating the greatest divergence from human attention (p< 0.05, Tukey HSD test). Results indicate that while ViTs exhibit more global attention patterns compared to human focal attention, certain attention heads can approximate human visual behavior, particularly for specific object features like buckles in basketry items. These findings suggest potential applications of ViT attention mechanisms in product design and aesthetic evaluation, while highlighting fundamental differences in attention strategies between human perception and current AI models.
Level of agreement between emotions generated by Artificial Intelligence and human evaluation: a methodological proposal
Oct 10, 2024



Images are capable of conveying emotions, but emotional experience is highly subjective. Advances in artificial intelligence have enabled the generation of images based on emotional descriptions. However, the level of agreement between the generative images and human emotional responses has not yet been evaluated. To address this, 20 artistic landscapes were generated using StyleGAN2-ADA. Four variants evoking positive emotions (contentment, amusement) and negative emotions (fear, sadness) were created for each image, resulting in 80 pictures. An online questionnaire was designed using this material, in which 61 observers classified the generated images. Statistical analyses were performed on the collected data to determine the level of agreement among participants, between the observer's responses, and the AI-generated emotions. A generally good level of agreement was found, with better results for negative emotions. However, the study confirms the subjectivity inherent in emotional evaluation.
OWAdapt: An adaptive loss function for deep learning using OWA operators
May 30, 2023



In this paper, we propose a fuzzy adaptive loss function for enhancing deep learning performance in classification tasks. Specifically, we redefine the cross-entropy loss to effectively address class-level noise conditions, including the challenging problem of class imbalance. Our approach introduces aggregation operators, leveraging the power of fuzzy logic to improve classification accuracy. The rationale behind our proposed method lies in the iterative up-weighting of class-level components within the loss function, focusing on those with larger errors. To achieve this, we employ the ordered weighted average (OWA) operator and combine it with an adaptive scheme for gradient-based learning. Through extensive experimentation, our method outperforms other commonly used loss functions, such as the standard cross-entropy or focal loss, across various binary and multiclass classification tasks. Furthermore, we explore the influence of hyperparameters associated with the OWA operators and present a default configuration that performs well across different experimental settings.
Analysis of the use of color and its emotional relationship in visual creations based on experiences during the context of the COVID-19 pandemic
Mar 25, 2022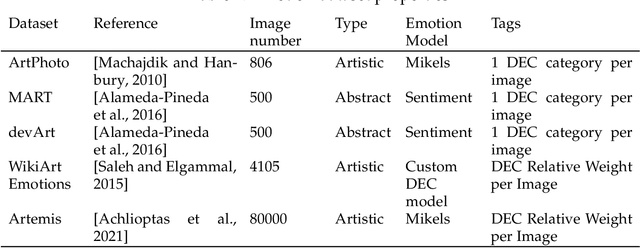

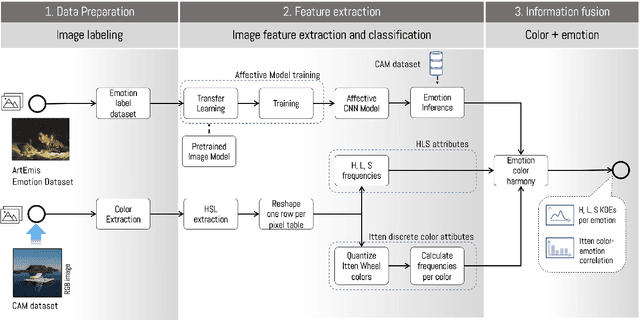

Color is a complex communicative element that helps us understand and evaluate our environment. At the level of artistic creation, this component influences both the formal aspects of the composition and the symbolic weight, directly affecting the construction and transmission of the message that you want to communicate, creating a specific emotional reaction. During the COVID-19 pandemic, people generated countless images transmitting this event's subjective experiences. Using the repository of images created in the Instagram account CAM (The COVID Art Museum), we propose a methodology to understand the use of color and its emotional relationship in this context. The process considers two stages in parallel that are then combined. First, emotions are extracted and classified from the CAM dataset images through a convolutional neural network. Second, we extract the colors and their harmonies through a clustering process. Once both processes are completed, we combine the results generating an expanded discussion on the usage of color, harmonies, and emotion. The results indicate that warm colors are prevalent in the sample, with a preference for analog compositions over complementary ones. The relationship between emotions and these compositions shows a trend in positive emotions, reinforced by the results of the algorithm a priori and the emotional relationship analysis of the attributes of color (hue, chroma, and lighting).
Quantitative analysis of visual representation of sign elements in COVID-19 context
Dec 15, 2021

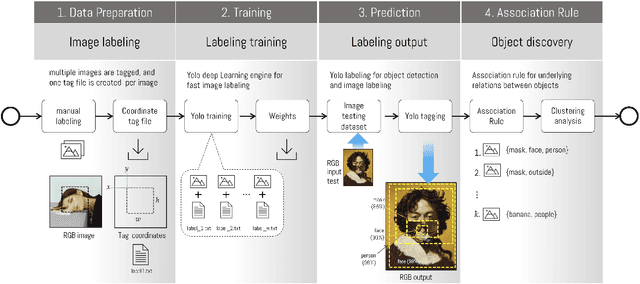
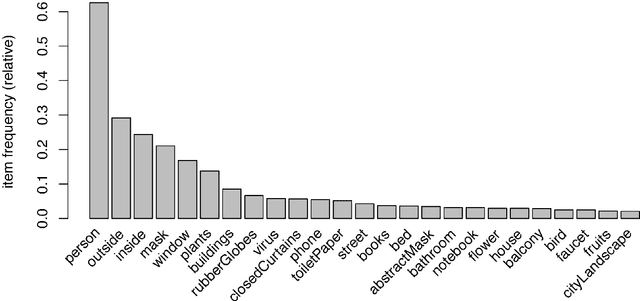
Representation is the way in which human beings re-present the reality of what is happening, both externally and internally. Thus, visual representation as a means of communication uses elements to build a narrative, just as spoken and written language do. We propose using computer analysis to perform a quantitative analysis of the elements used in the visual creations that have been produced in reference to the epidemic, using the images compiled in The Covid Art Museum's Instagram account to analyze the different elements used to represent subjective experiences with regard to a global event. This process has been carried out with techniques based on machine learning to detect objects in the images so that the algorithm can be capable of learning and detecting the objects contained in each study image. This research reveals that the elements that are repeated in images to create narratives and the relations of association that are established in the sample, concluding that, despite the subjectivity that all creation entails, there are certain parameters of shared and reduced decisions when it comes to selecting objects to be included in visual representations