 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Slice Interpolation for Reducing Through-Plane Anisotropy and Noise in Head CT
Jun 08, 2026Head computed tomography (CT) typically uses sub-millimeter in-plane resolution but 2-5 mm through-plane spacing, creating substantial anisotropy that degrades multiplanar reconstructions, volumetric measurements such as hematoma volume estimation, and downstream algorithms that assume near-isotropic voxels. We present a deep learning system that synthesizes intermediate CT slices from pairs of neighboring axial slices, halving the effective through-plane spacing. The system improves three-dimensional visualization while simultaneously producing inherently denoised outputs, yielding two complementary benefits from a single inference pass. To build a reliable system, we systematically evaluate pixel-wise losses, namely mean squared error (MSE) and mean absolute error (L1); structural-similarity losses, namely the structural similarity index (SSIM) and its multi-scale variant (MS-SSIM); and hybrid combinations. On a held-out test set, all converged models outperform classical interpolation baselines and pretrained video frame interpolation methods (RIFE, FILM) on all structural measures, with MS-SSIM+L1 offering the strongest balanced profile. We also document training instability in SSIM-family losses and identify partial remedies: the standard numerical fixes eliminate the dominant failure mode but leave residual divergence at smaller batch sizes. All results are reported with patient-level bootstrap confidence intervals and paired statistical tests. As an illustration, we apply the system to an out-of-distribution head CT series from Hospital Universitario Virgen del Rocío: the model synthesizes intermediate slices and exhibits on the real slices the implicit-denoising signature predicted by our theoretical analysis, supporting in a single external case that interpolation quality and implicit denoising are not confined to the training distribution.
Class-Dependent Hybrid Data Augmentation for Multiclass Migraine Classification under Severe Class Imbalance
May 22, 2026We conducted a reproducibility-oriented re-evaluation of prior migraine classification studies, correcting for data leakage and metric bias. We then introduced (i) a clinically motivated aggregation of two hemiplegic subtypes following ICHD-3 §1.2.3, (ii) a class-dependent hybrid augmentation strategy that assigns generation methods based on per-class sample size, and (iii) the concept of fidelity asymmetry, motivating proportionally constrained growth as an alternative to full class balance. Experiments were performed on a dataset of 400 patients across seven migraine subtypes under a two-stage protocol, including the six-class configuration described above. Models were evaluated using stratified 5-fold cross-validation with macro-averaged F1 as the primary metric. Correcting methodological flaws reduces previously inflated performance estimates, with the corrected macro-F1 baseline standing at 0.71. The proposed framework consistently outperformed individual augmenters in macro-F1 averaged across the eight evaluated classifiers (0.862 vs. 0.836 for Gaussian Copula, 0.815 for CTGAN, and 0.801 for the no-augmentation baseline), and achieved its peak result of 0.914 with FT-Transformer under proportional augmentation. The no-augmentation FT-Transformer baseline (0.896) shows that, at the per-classifier ceiling, clinically motivated class aggregation accounts for most of the absolute improvement; the framework's principal measurable contribution is the gain in average robustness across classifiers, highlighting the dominant role of problem formulation.
Interpretability of the Intent Detection Problem: A New Approach
Jan 23, 2026Intent detection, a fundamental text classification task, aims to identify and label the semantics of user queries, playing a vital role in numerous business applications. Despite the dominance of deep learning techniques in this field, the internal mechanisms enabling Recurrent Neural Networks (RNNs) to solve intent detection tasks are poorly understood. In this work, we apply dynamical systems theory to analyze how RNN architectures address this problem, using both the balanced SNIPS and the imbalanced ATIS datasets. By interpreting sentences as trajectories in the hidden state space, we first show that on the balanced SNIPS dataset, the network learns an ideal solution: the state space, constrained to a low-dimensional manifold, is partitioned into distinct clusters corresponding to each intent. The application of this framework to the imbalanced ATIS dataset then reveals how this ideal geometric solution is distorted by class imbalance, causing the clusters for low-frequency intents to degrade. Our framework decouples geometric separation from readout alignment, providing a novel, mechanistic explanation for real world performance disparities. These findings provide new insights into RNN dynamics, offering a geometric interpretation of how dataset properties directly shape a network's computational solution.
Interpretation of the Intent Detection Problem as Dynamics in a Low-dimensional Space
Aug 05, 2024



Intent detection is a text classification task whose aim is to recognize and label the semantics behind a users query. It plays a critical role in various business applications. The output of the intent detection module strongly conditions the behavior of the whole system. This sequence analysis task is mainly tackled using deep learning techniques. Despite the widespread use of these techniques, the internal mechanisms used by networks to solve the problem are poorly understood. Recent lines of work have analyzed the computational mechanisms learned by RNNs from a dynamical systems perspective. In this work, we investigate how different RNN architectures solve the SNIPS intent detection problem. Sentences injected into trained networks can be interpreted as trajectories traversing a hidden state space. This space is constrained to a low-dimensional manifold whose dimensionality is related to the embedding and hidden layer sizes. To generate predictions, RNN steers the trajectories towards concrete regions, spatially aligned with the output layer matrix rows directions. Underlying the system dynamics, an unexpected fixed point topology has been identified with a limited number of attractors. Our results provide new insights into the inner workings of networks that solve the intent detection task.
SIMAP: A simplicial-map layer for neural networks
Mar 22, 2024



In this paper, we present SIMAP, a novel layer integrated into deep learning models, aimed at enhancing the interpretability of the output. The SIMAP layer is an enhanced version of Simplicial-Map Neural Networks (SMNNs), an explainable neural network based on support sets and simplicial maps (functions used in topology to transform shapes while preserving their structural connectivity). The novelty of the methodology proposed in this paper is two-fold: Firstly, SIMAP layers work in combination with other deep learning architectures as an interpretable layer substituting classic dense final layers. Secondly, unlike SMNNs, the support set is based on a fixed maximal simplex, the barycentric subdivision being efficiently computed with a matrix-based multiplication algorithm.
Explainability in Simplicial Map Neural Networks
May 29, 2023



Simplicial map neural networks (SMNNs) are topology-based neural networks with interesting properties such as universal approximation capability and robustness to adversarial examples under appropriate conditions. However, SMNNs present some bottlenecks for their possible application in high dimensions. First, no SMNN training process has been defined so far. Second, SMNNs require the construction of a convex polytope surrounding the input dataset. In this paper, we propose a SMNN training procedure based on a support subset of the given dataset and a method based on projection to a hypersphere as a replacement for the convex polytope construction. In addition, the explainability capacity of SMNNs is also introduced for the first time in this paper.
Dynamic Price of Parking Service based on Deep Learning
Jan 11, 2022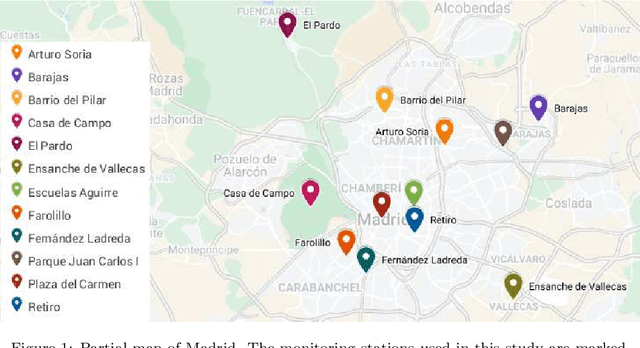
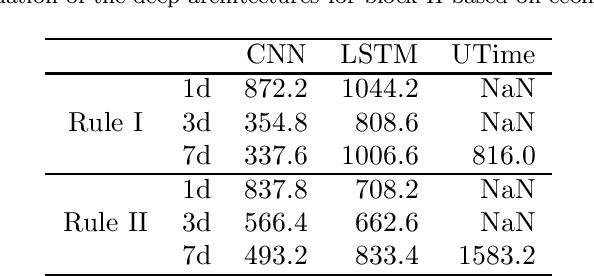
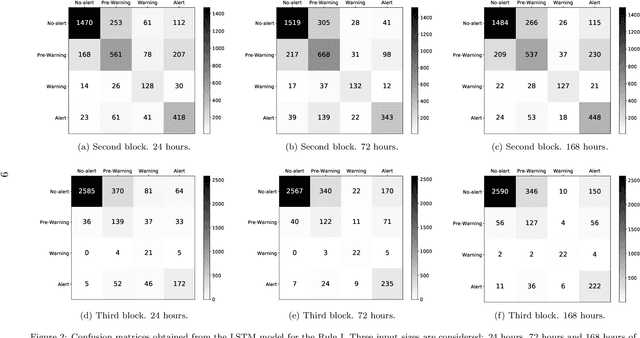
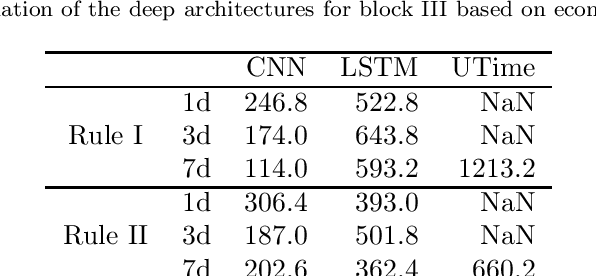
The improvement of air-quality in urban areas is one of the main concerns of public government bodies. This concern emerges from the evidence between the air quality and the public health. Major efforts from government bodies in this area include monitoring and forecasting systems, banning more pollutant motor vehicles, and traffic limitations during the periods of low-quality air. In this work, a proposal for dynamic prices in regulated parking services is presented. The dynamic prices in parking service must discourage motor vehicles parking when low-quality episodes are predicted. For this purpose, diverse deep learning strategies are evaluated. They have in common the use of collective air-quality measurements for forecasting labels about air quality in the city. The proposal is evaluated by using economic parameters and deep learning quality criteria at Madrid (Spain).
Towards a Philological Metric through a Topological Data Analysis Approach
Jan 11, 2020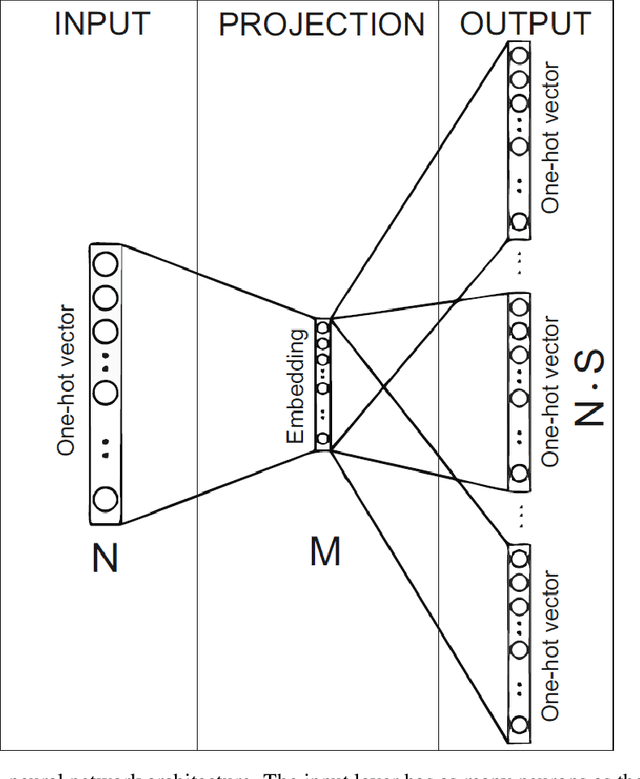

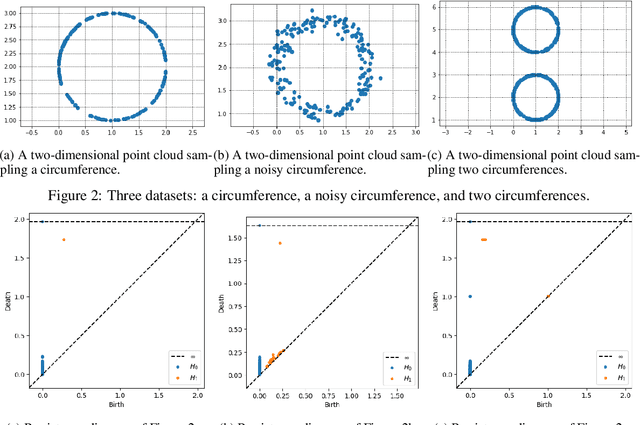
The canon of the baroque Spanish literature has been thoroughly studied with philological techniques. The major representatives of the poetry of this epoch are Francisco de Quevedo and Luis de G\'ongora y Argote. They are commonly classified by the literary experts in two different streams: Quevedo belongs to the Conceptismo and G\'ongora to the Culteranismo. Besides, traditionally, even if Quevedo is considered the most representative of the Conceptismo, Lope de Vega is also considered to be, at least, closely related to this literary trend. In this paper, we use Topological Data Analysis techniques to provide a first approach to a metric distance between the literary style of these poets. As a consequence, we reach results that are under the literary experts' criteria, locating the literary style of Lope de Vega, closer to the one of Quevedo than to the one of G\'ongora.
Two-hidden-layer Feedforward Neural Networks are Universal Approximators: A Constructive Approach
Jul 26, 2019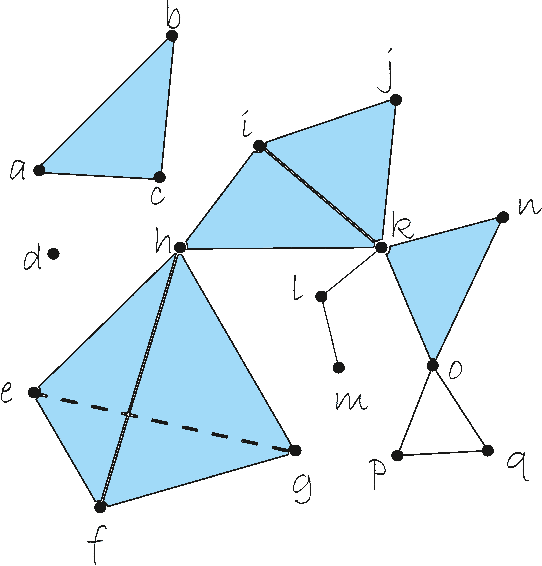
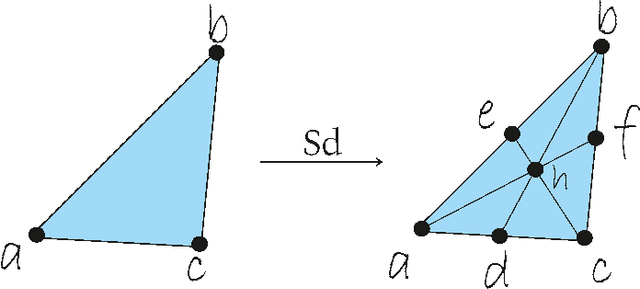
It is well known that Artificial Neural Networks are universal approximators. The classical result proves that, given a continuous function on a compact set on an n-dimensional space, then there exists a one-hidden-layer feedforward network which approximates the function. Such result proves the existence, but it does not provide a method for finding it. In this paper, a constructive approach to the proof of this property is given for the case of two-hidden-layer feedforward networks. This approach is based on an approximation of continuous functions by simplicial maps. Once a triangulation of the space is given, a concrete architecture and set of weights can be obtained. The quality of the approximation depends on the refinement of the covering of the space by simplicial complexes.
Representative Datasets: The Perceptron Case
Mar 20, 2019

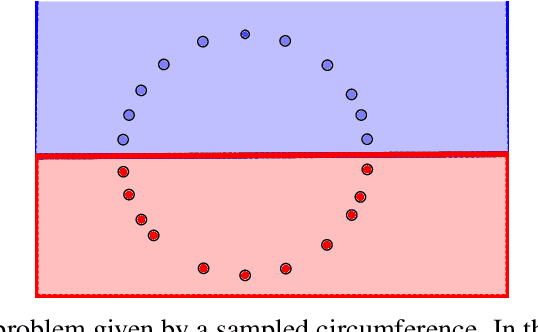
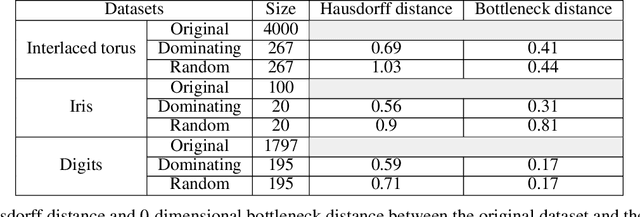
One of the main drawbacks of the practical use of neural networks is the long time needed in the training process. Such training process consists in an iterative change of parameters trying to minimize a loss function. These changes are driven by a dataset, which can be seen as a set of labeled points in an n-dimensional space. In this paper, we explore the concept of it representative dataset which is smaller than the original dataset and satisfies a nearness condition independent of isometric transformations. The representativeness is measured using persistence diagrams due to its computational efficiency. We also prove that the accuracy of the learning process of a neural network on a representative dataset is comparable with the accuracy on the original dataset when the neural network architecture is a perceptron and the loss function is the mean squared error. These theoretical results accompanied with experimentation open a door to the size reduction of the dataset in order to gain time in the training process of any neural network.