 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlopPITy: Enabling self-consistent exoplanet atmospheric retrievals with machine learning
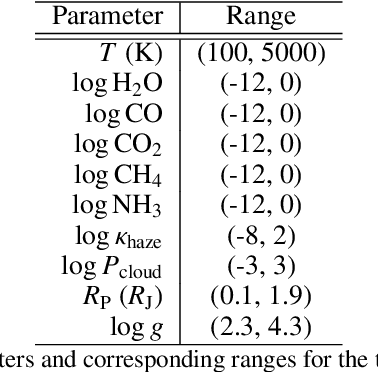
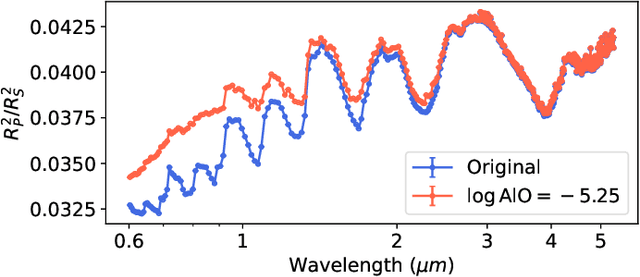
Jan 08, 2024Interpreting the observations of exoplanet atmospheres to constrain physical and chemical properties is typically done using Bayesian retrieval techniques. Because these methods require many model computations, a compromise is made between model complexity and run time. Reaching this compromise leads to the simplification of many physical and chemical processes (e.g. parameterised temperature structure). Here we implement and test sequential neural posterior estimation (SNPE), a machine learning inference algorithm, for exoplanet atmospheric retrievals. The goal is to speed up retrievals so they can be run with more computationally expensive atmospheric models, such as those computing the temperature structure using radiative transfer. We generate 100 synthetic observations using ARCiS (ARtful Modeling Code for exoplanet Science, an atmospheric modelling code with the flexibility to compute models in varying degrees of complexity) and perform retrievals on them to test the faithfulness of the SNPE posteriors. The faithfulness quantifies whether the posteriors contain the ground truth as often as we expect. We also generate a synthetic observation of a cool brown dwarf using the self-consistent capabilities of ARCiS and run a retrieval with self-consistent models to showcase the possibilities that SNPE opens. We find that SNPE provides faithful posteriors and is therefore a reliable tool for exoplanet atmospheric retrievals. We are able to run a self-consistent retrieval of a synthetic brown dwarf spectrum using only 50,000 forward model evaluations. We find that SNPE can speed up retrievals between $\sim2\times$ and $\geq10\times$ depending on the computational load of the forward model, the dimensionality of the observation, and the signal-to-noise ratio of the observation. We make the code publicly available for the community on Github.
Convolutional neural networks as an alternative to Bayesian retrievals
Mar 03, 2022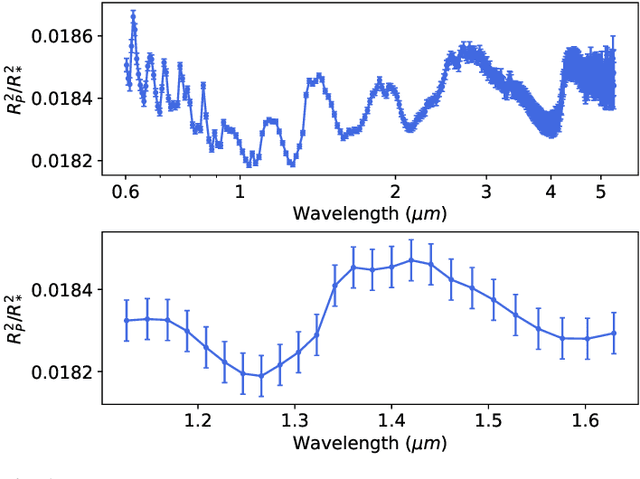
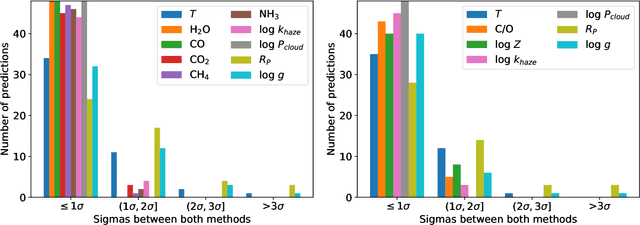
Exoplanet observations are currently analysed with Bayesian retrieval techniques. Due to the computational load of the models used, a compromise is needed between model complexity and computing time. Analysis of data from future facilities, will need more complex models which will increase the computational load of retrievals, prompting the search for a faster approach for interpreting exoplanet observations. Our goal is to compare machine learning retrievals of exoplanet transmission spectra with nested sampling, and understand if machine learning can be as reliable as Bayesian retrievals for a statistically significant sample of spectra while being orders of magnitude faster. We generate grids of synthetic transmission spectra and their corresponding planetary and atmospheric parameters, one using free chemistry models, and the other using equilibrium chemistry models. Each grid is subsequently rebinned to simulate both HST/WFC3 and JWST/NIRSpec observations, yielding four datasets in total. Convolutional neural networks (CNNs) are trained with each of the datasets. We perform retrievals on a 1,000 simulated observations for each combination of model type and instrument with nested sampling and machine learning. We also use both methods to perform retrievals on real WFC3 transmission spectra. Finally, we test how robust machine learning and nested sampling are against incorrect assumptions in our models. CNNs reach a lower coefficient of determination between predicted and true values of the parameters. Nested sampling underestimates the uncertainty in ~8% of retrievals, whereas CNNs estimate them correctly. For real WFC3 observations, nested sampling and machine learning agree within $2\sigma$ for ~86% of spectra. When doing retrievals with incorrect assumptions, nested sampling underestimates the uncertainty in ~12% to ~41% of cases, whereas this is always below ~10% for the CNN.