 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Generation of Custom MedDRA Queries Using SafeTerm Medical Map
Dec 08, 2025In pre-market drug safety review, grouping related adverse event terms into standardised MedDRA queries or the FDA Office of New Drugs Custom Medical Queries (OCMQs) is critical for signal detection. We present a novel quantitative artificial intelligence system that understands and processes medical terminology and automatically retrieves relevant MedDRA Preferred Terms (PTs) for a given input query, ranking them by a relevance score using multi-criteria statistical methods. The system (SafeTerm) embeds medical query terms and MedDRA PTs in a multidimensional vector space, then applies cosine similarity and extreme-value clustering to generate a ranked list of PTs. Validation was conducted against the FDA OCMQ v3.0 (104 queries), restricted to valid MedDRA PTs. Precision, recall and F1 were computed across similarity-thresholds. High recall (>95%) is achieved at moderate thresholds. Higher thresholds improve precision (up to 86%). The optimal threshold (~0.70 - 0.75) yielded recall ~50% and precision ~33%. Narrow-term PT subsets performed similarly but required slightly higher similarity thresholds. The SafeTerm AI-driven system provides a viable supplementary method for automated MedDRA query generation. A similarity threshold of ~0.60 is recommended initially, with increased thresholds for refined term selection.
Performance of the SafeTerm AI-Based MedDRA Query System Against Standardised MedDRA Queries
Dec 08, 2025In pre-market drug safety review, grouping related adverse event terms into SMQs or OCMQs is critical for signal detection. We assess the performance of SafeTerm Automated Medical Query (AMQ) on MedDRA SMQs. The AMQ is a novel quantitative artificial intelligence system that understands and processes medical terminology and automatically retrieves relevant MedDRA Preferred Terms (PTs) for a given input query, ranking them by a relevance score (0-1) using multi-criteria statistical methods. The system (SafeTerm) embeds medical query terms and MedDRA PTs in a multidimensional vector space, then applies cosine similarity, and extreme-value clustering to generate a ranked list of PTs. Validation was conducted against tier-1 SMQs (110 queries, v28.1). Precision, recall and F1 were computed at multiple similarity-thresholds, defined either manually or using an automated method. High recall (94%)) is achieved at moderate similarity thresholds, indicative of good retrieval sensitivity. Higher thresholds filter out more terms, resulting in improved precision (up to 89%). The optimal threshold (0.70)) yielded an overall recall of (48%) and precision of (45%) across all 110 queries. Restricting to narrow-term PTs achieved slightly better performance at an increased (+0.05) similarity threshold, confirming increased relatedness of narrow versus broad terms. The automatic threshold (0.66) selection prioritizes recall (0.58) to precision (0.29). SafeTerm AMQ achieves comparable, satisfactory performance on SMQs and sanitized OCMQs. It is therefore a viable supplementary method for automated MedDRA query generation, balancing recall and precision. We recommend using suitable MedDRA PT terminology in query formulation and applying the automated threshold method to optimise recall. Increasing similarity scores allows refined, narrow terms selection.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020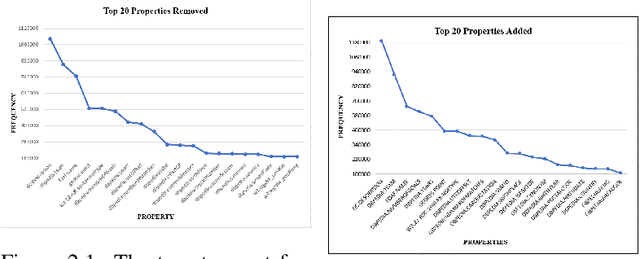
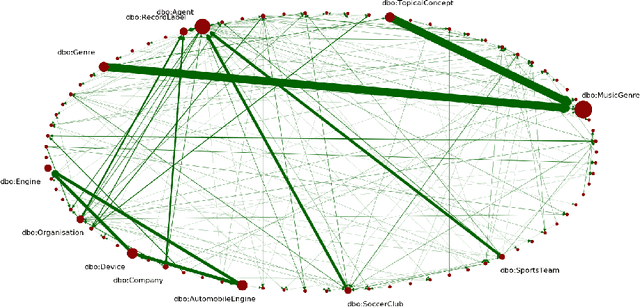

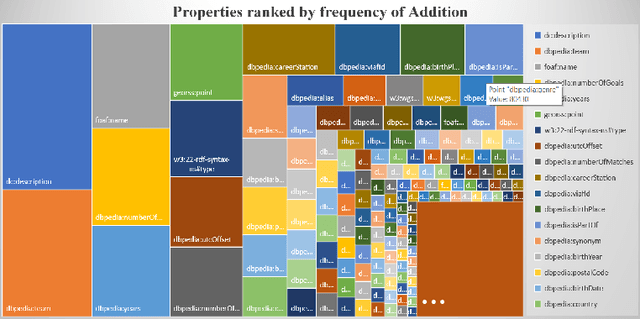
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.