 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Word Clouds with Background Corpus Normalization and t-distributed Stochastic Neighbor Embedding
Aug 11, 2017
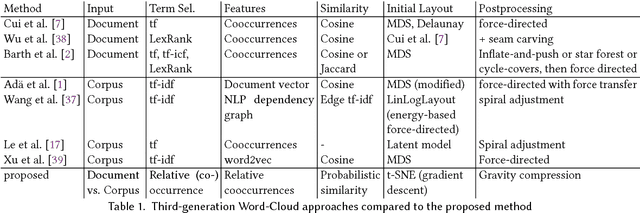

Many word clouds provide no semantics to the word placement, but use a random layout optimized solely for aesthetic purposes. We propose a novel approach to model word significance and word affinity within a document, and in comparison to a large background corpus. We demonstrate its usefulness for generating more meaningful word clouds as a visual summary of a given document. We then select keywords based on their significance and construct the word cloud based on the derived affinity. Based on a modified t-distributed stochastic neighbor embedding (t-SNE), we generate a semantic word placement. For words that cooccur significantly, we include edges, and cluster the words according to their cooccurrence. For this we designed a scalable and memory-efficient sketch-based approach usable on commodity hardware to aggregate the required corpus statistics needed for normalization, and for identifying keywords as well as significant cooccurences. We empirically validate our approch using a large Wikipedia corpus.
Robust Image Segmentation in Low Depth Of Field Images
Feb 15, 2013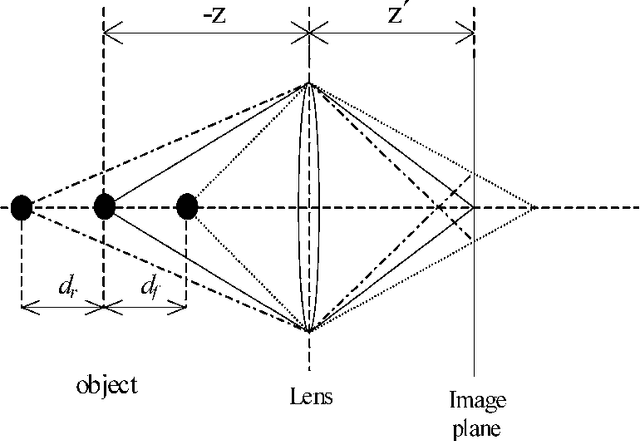

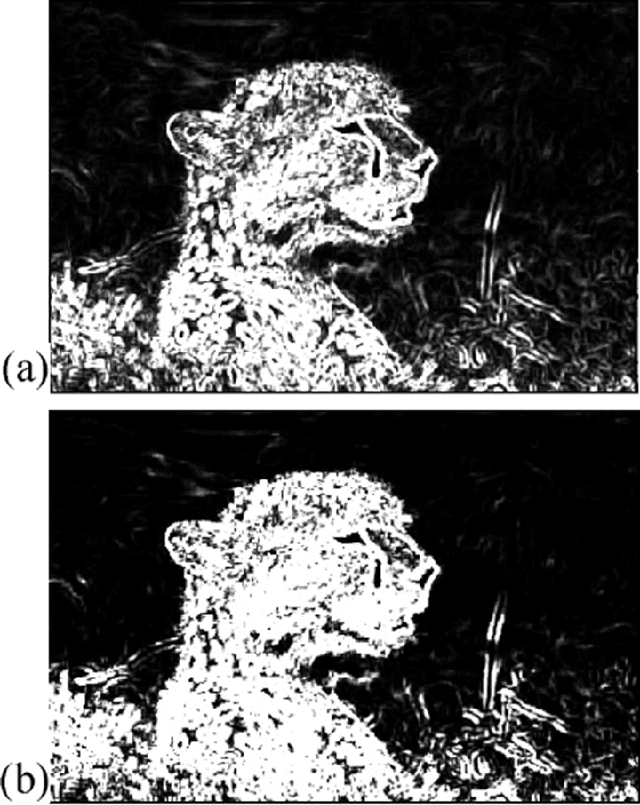

In photography, low depth of field (DOF) is an important technique to emphasize the object of interest (OOI) within an image. Thus, low DOF images are widely used in the application area of macro, portrait or sports photography. When viewing a low DOF image, the viewer implicitly concentrates on the regions that are sharper regions of the image and thus segments the image into regions of interest and non regions of interest which has a major impact on the perception of the image. Thus, a robust algorithm for the fully automatic detection of the OOI in low DOF images provides valuable information for subsequent image processing and image retrieval. In this paper we propose a robust and parameterless algorithm for the fully automatic segmentation of low DOF images. We compare our method with three similar methods and show the superior robustness even though our algorithm does not require any parameters to be set by hand. The experiments are conducted on a real world data set with high and low DOF images.
* Extended Version of the short paper published in "Robust Image Segmentation in Low Depth Of Field Images", IEEE International Conference on Image Processing 2011 (ICIP). The paper contains a lot more details about the algorithm and more evaluation