 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWide Boosting
Aug 22, 2020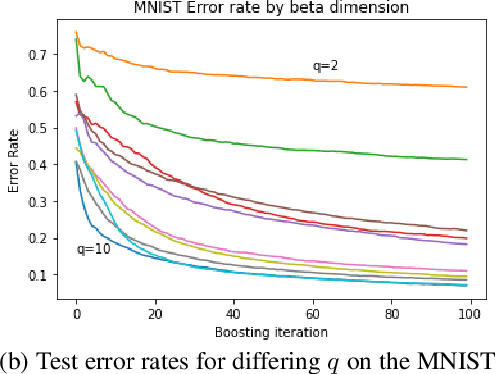
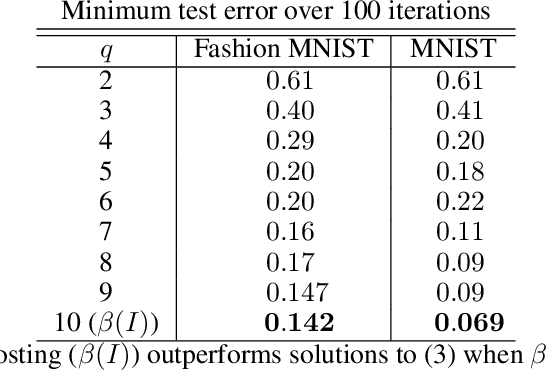
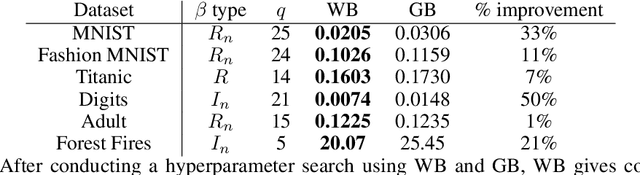
Gradient boosting (GB) is a popular methodology used to solve prediction problems through minimization of a differentiable loss function, $L$. GB is especially performant in low and medium dimension problems. This paper presents a simple adjustment to GB motivated in part by artificial neural networks. Specifically, our adjustment inserts a square or rectangular matrix multiplication between the output of a GB model and the loss, $L$. This allows the output of a GB model to have increased dimension prior to being fed into the loss and is thus "wider" than standard GB implementations. We provide performance comparisons on several publicly available datasets. When using the same tuning methodology and same maximum boosting rounds, Wide Boosting outperforms standard GB in every dataset we try.