 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Entity Typing in Hyperbolic Space
Jun 06, 2019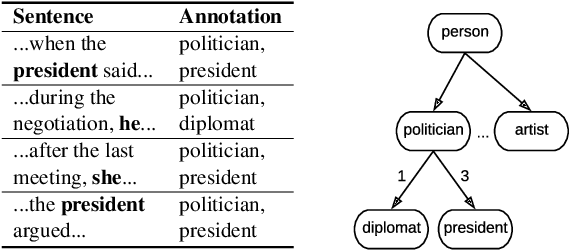
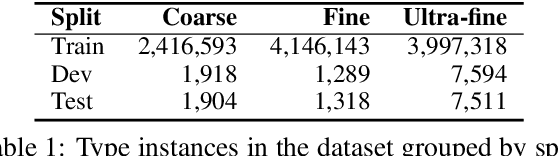
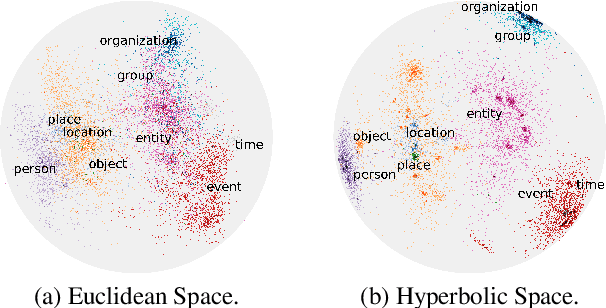
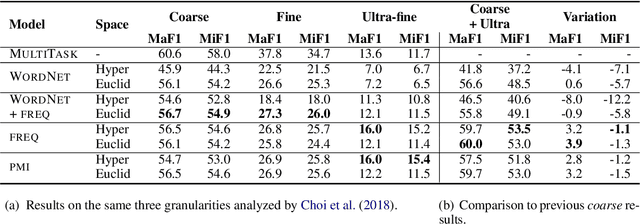
How can we represent hierarchical information present in large type inventories for entity typing? We study the ability of hyperbolic embeddings to capture hierarchical relations between mentions in context and their target types in a shared vector space. We evaluate on two datasets and investigate two different techniques for creating a large hierarchical entity type inventory: from an expert-generated ontology and by automatically mining type co-occurrences. We find that the hyperbolic model yields improvements over its Euclidean counterpart in some, but not all cases. Our analysis suggests that the adequacy of this geometry depends on the granularity of the type inventory and the way hierarchical relations are inferred.
Sequence Tagging with Contextual and Non-Contextual Subword Representations: A Multilingual Evaluation
Jun 04, 2019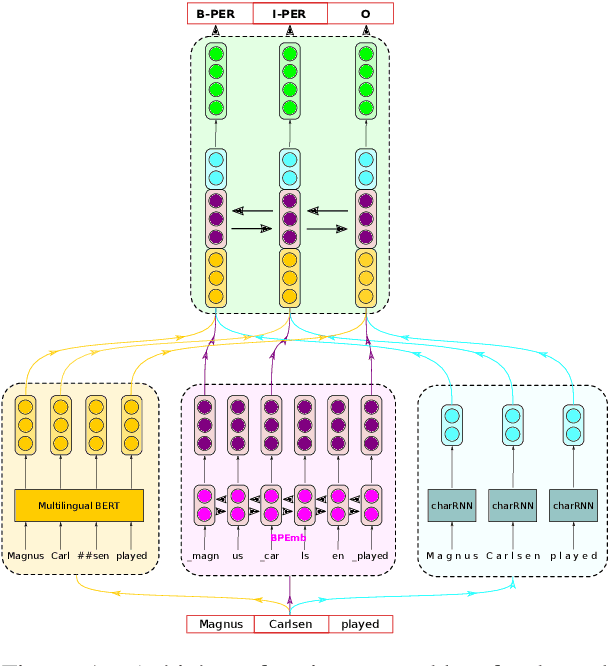
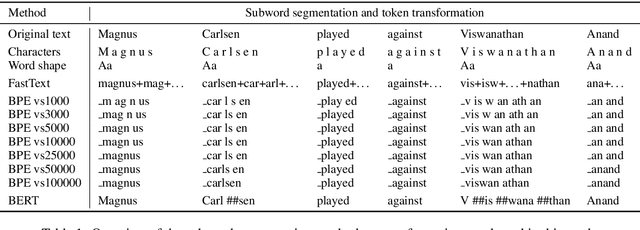

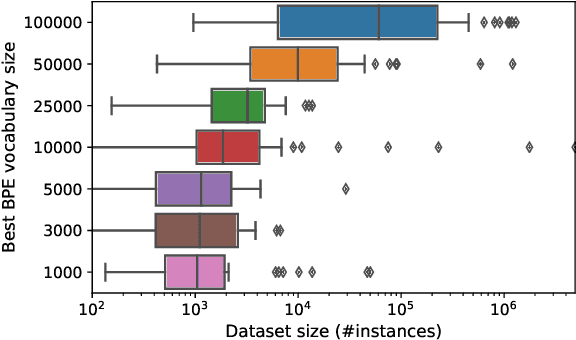
Pretrained contextual and non-contextual subword embeddings have become available in over 250 languages, allowing massively multilingual NLP. However, while there is no dearth of pretrained embeddings, the distinct lack of systematic evaluations makes it difficult for practitioners to choose between them. In this work, we conduct an extensive evaluation comparing non-contextual subword embeddings, namely FastText and BPEmb, and a contextual representation method, namely BERT, on multilingual named entity recognition and part-of-speech tagging. We find that overall, a combination of BERT, BPEmb, and character representations works best across languages and tasks. A more detailed analysis reveals different strengths and weaknesses: Multilingual BERT performs well in medium- to high-resource languages, but is outperformed by non-contextual subword embeddings in a low-resource setting.
Using Linguistic Features to Improve the Generalization Capability of Neural Coreference Resolvers
Oct 12, 2018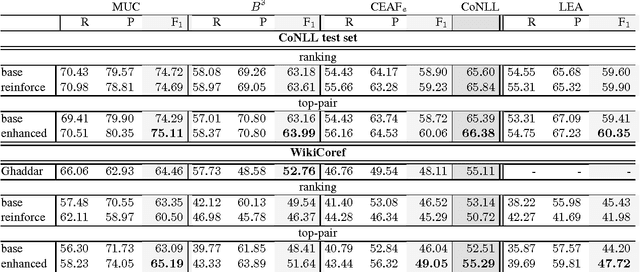
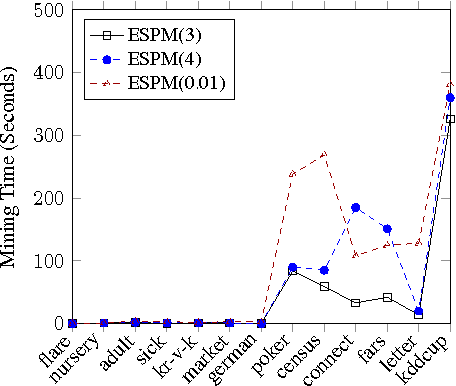
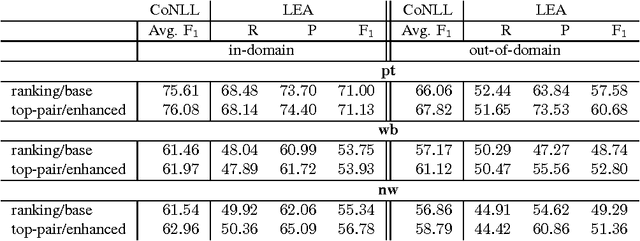
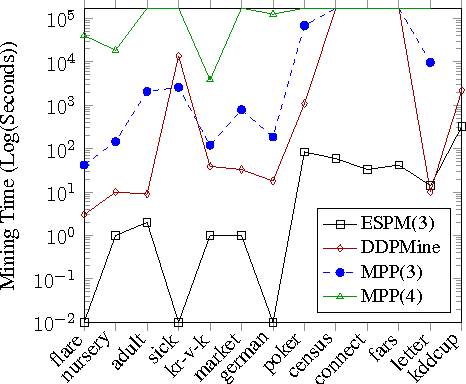
Coreference resolution is an intermediate step for text understanding. It is used in tasks and domains for which we do not necessarily have coreference annotated corpora. Therefore, generalization is of special importance for coreference resolution. However, while recent coreference resolvers have notable improvements on the CoNLL dataset, they struggle to generalize properly to new domains or datasets. In this paper, we investigate the role of linguistic features in building more generalizable coreference resolvers. We show that generalization improves only slightly by merely using a set of additional linguistic features. However, employing features and subsets of their values that are informative for coreference resolution, considerably improves generalization. Thanks to better generalization, our system achieves state-of-the-art results in out-of-domain evaluations, e.g., on WikiCoref, our system, which is trained on CoNLL, achieves on-par performance with a system designed for this dataset.
Transparent, Efficient, and Robust Word Embedding Access with WOMBAT
Jul 02, 2018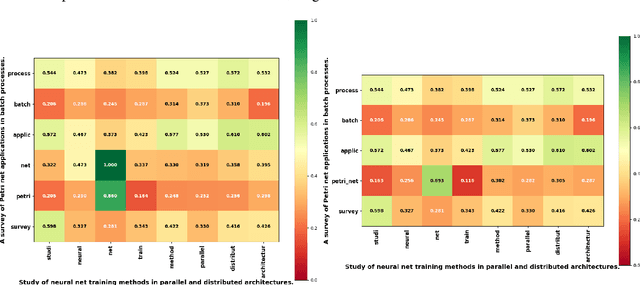
We present WOMBAT, a Python tool which supports NLP practitioners in accessing word embeddings from code. WOMBAT addresses common research problems, including unified access, scaling, and robust and reproducible preprocessing. Code that uses WOMBAT for accessing word embeddings is not only cleaner, more readable, and easier to reuse, but also much more efficient than code using standard in-memory methods: a Python script using WOMBAT for evaluating seven large word embedding collections (8.7M embedding vectors in total) on a simple SemEval sentence similarity task involving 250 raw sentence pairs completes in under ten seconds end-to-end on a standard notebook computer.
BPEmb: Tokenization-free Pre-trained Subword Embeddings in 275 Languages
Oct 05, 2017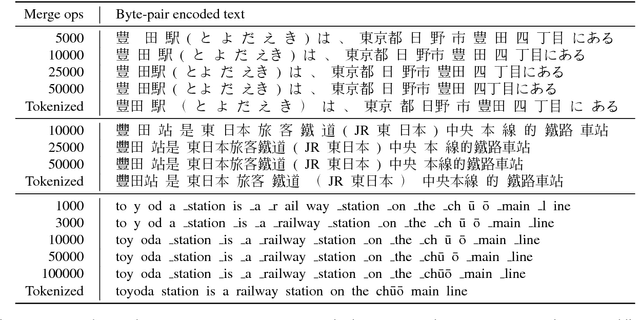
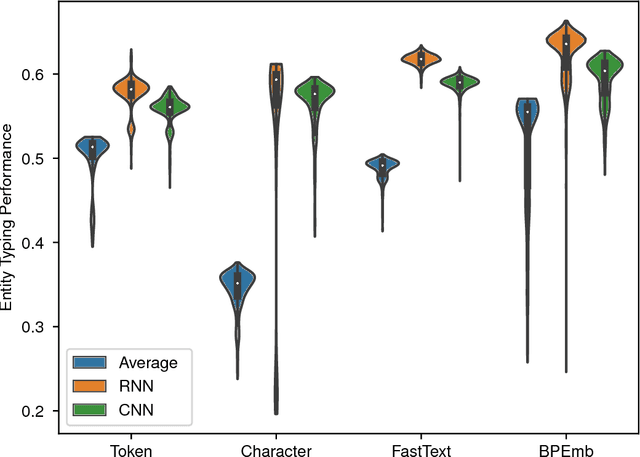
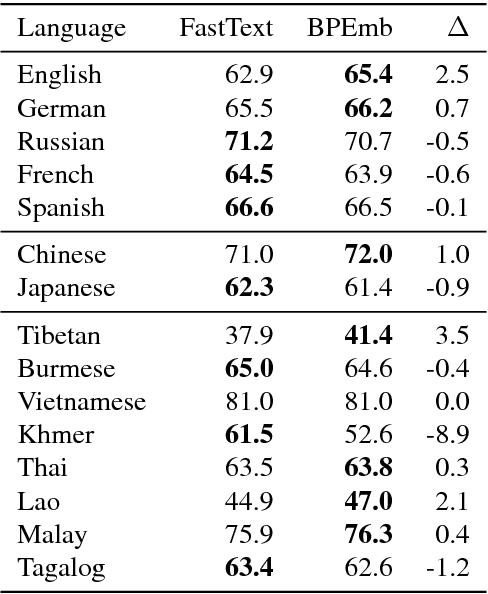
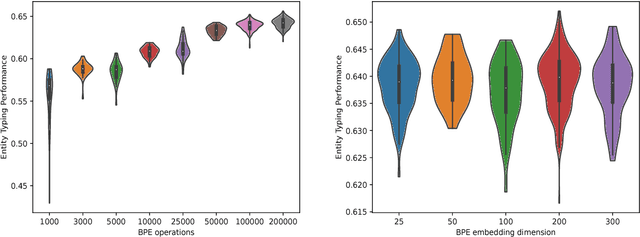
We present BPEmb, a collection of pre-trained subword unit embeddings in 275 languages, based on Byte-Pair Encoding (BPE). In an evaluation using fine-grained entity typing as testbed, BPEmb performs competitively, and for some languages bet- ter than alternative subword approaches, while requiring vastly fewer resources and no tokenization. BPEmb is available at https://github.com/bheinzerling/bpemb
Revisiting Selectional Preferences for Coreference Resolution
Jul 20, 2017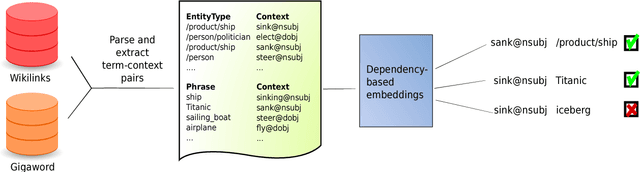
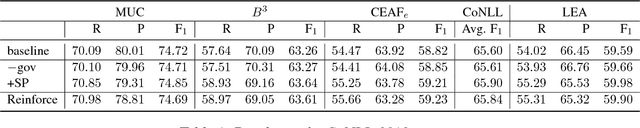
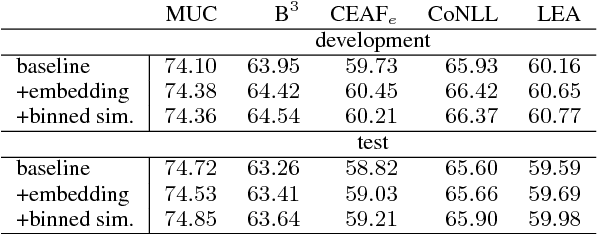
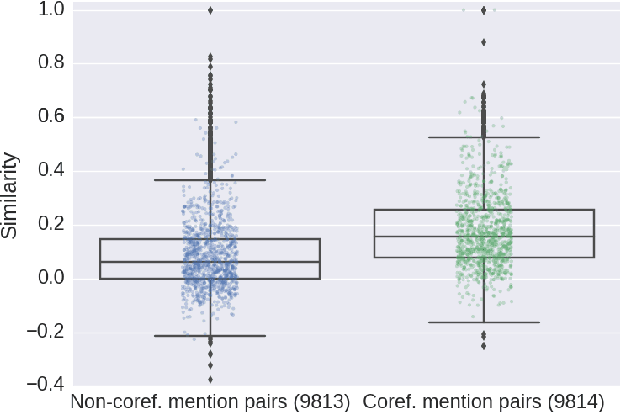
Selectional preferences have long been claimed to be essential for coreference resolution. However, they are mainly modeled only implicitly by current coreference resolvers. We propose a dependency-based embedding model of selectional preferences which allows fine-grained compatibility judgments with high coverage. We show that the incorporation of our model improves coreference resolution performance on the CoNLL dataset, matching the state-of-the-art results of a more complex system. However, it comes with a cost that makes it debatable how worthwhile such improvements are.
Lexical Features in Coreference Resolution: To be Used With Caution
Apr 22, 2017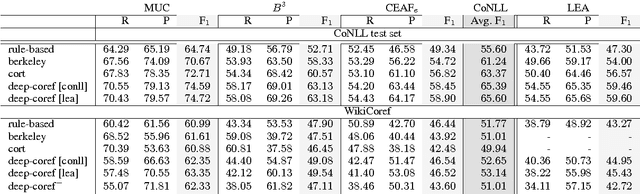

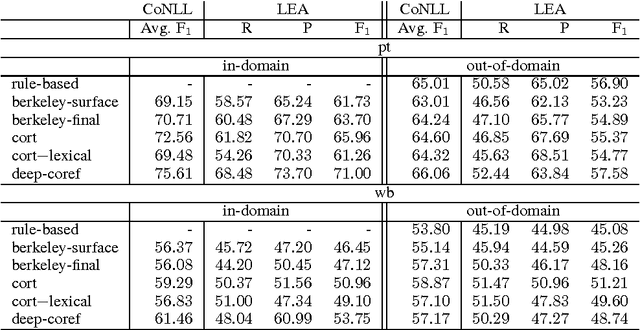

Lexical features are a major source of information in state-of-the-art coreference resolvers. Lexical features implicitly model some of the linguistic phenomena at a fine granularity level. They are especially useful for representing the context of mentions. In this paper we investigate a drawback of using many lexical features in state-of-the-art coreference resolvers. We show that if coreference resolvers mainly rely on lexical features, they can hardly generalize to unseen domains. Furthermore, we show that the current coreference resolution evaluation is clearly flawed by only evaluating on a specific split of a specific dataset in which there is a notable overlap between the training, development and test sets.
Use Generalized Representations, But Do Not Forget Surface Features
Feb 24, 2017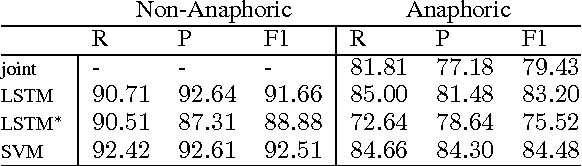
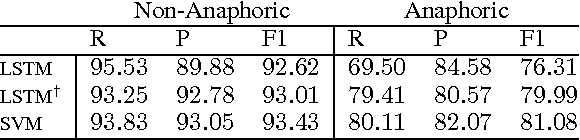
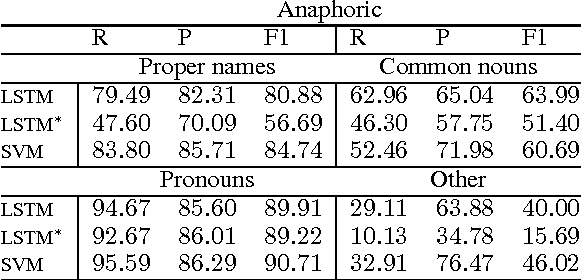
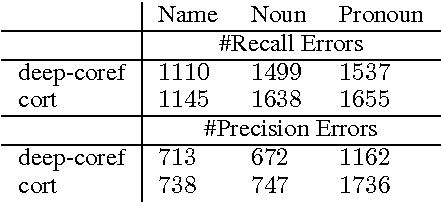
Only a year ago, all state-of-the-art coreference resolvers were using an extensive amount of surface features. Recently, there was a paradigm shift towards using word embeddings and deep neural networks, where the use of surface features is very limited. In this paper, we show that a simple SVM model with surface features outperforms more complex neural models for detecting anaphoric mentions. Our analysis suggests that using generalized representations and surface features have different strength that should be both taken into account for improving coreference resolution.
Never Look Back: An Alternative to Centering
Jun 25, 1998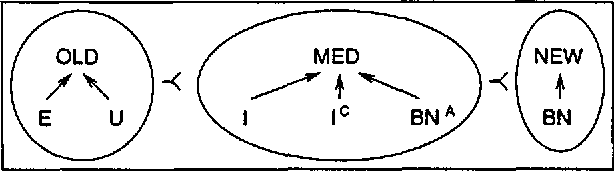



I propose a model for determining the hearer's attentional state which depends solely on a list of salient discourse entities (S-list). The ordering among the elements of the S-list covers also the function of the backward-looking center in the centering model. The ranking criteria for the S-list are based on the distinction between hearer-old and hearer-new discourse entities and incorporate preferences for inter- and intra-sentential anaphora. The model is the basis for an algorithm which operates incrementally, word by word.
* 7 pages, uses colacl.sty, epsfig.sty, times.sty, lingmacros.sty
Centering in-the-large: Computing referential discourse segments
Apr 30, 1997
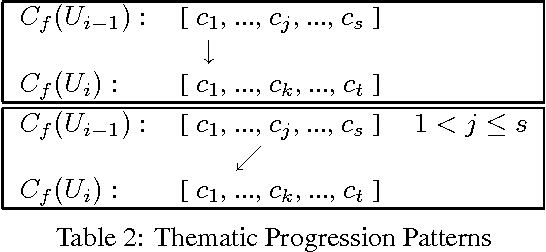
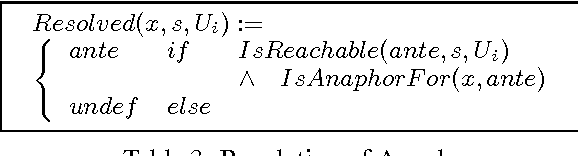
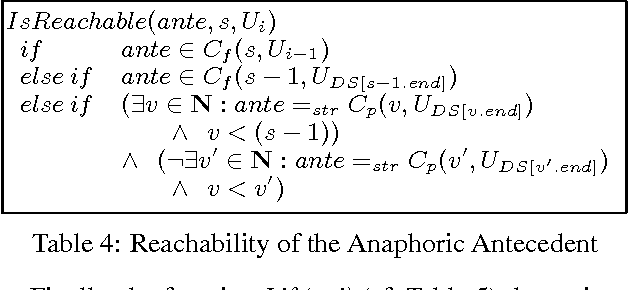
We specify an algorithm that builds up a hierarchy of referential discourse segments from local centering data. The spatial extension and nesting of these discourse segments constrain the reachability of potential antecedents of an anaphoric expression beyond the local level of adjacent center pairs. Thus, the centering model is scaled up to the level of the global referential structure of discourse. An empirical evaluation of the algorithm is supplied.
* LaTeX, 8 pages