Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBPEmb: Tokenization-free Pre-trained Subword Embeddings in 275 Languages
Paper and Code
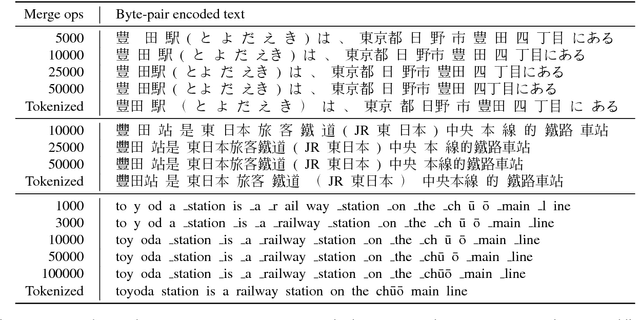
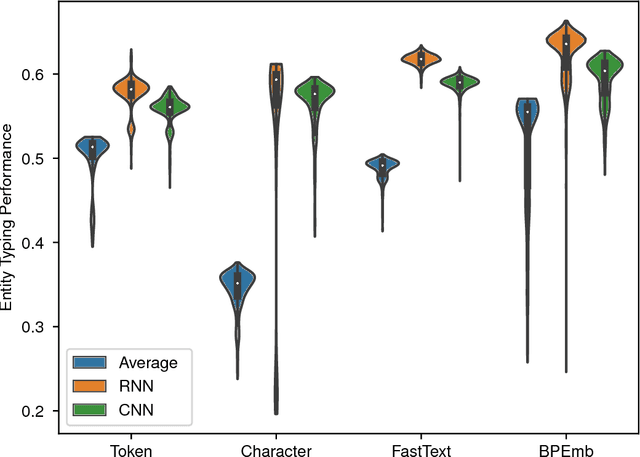
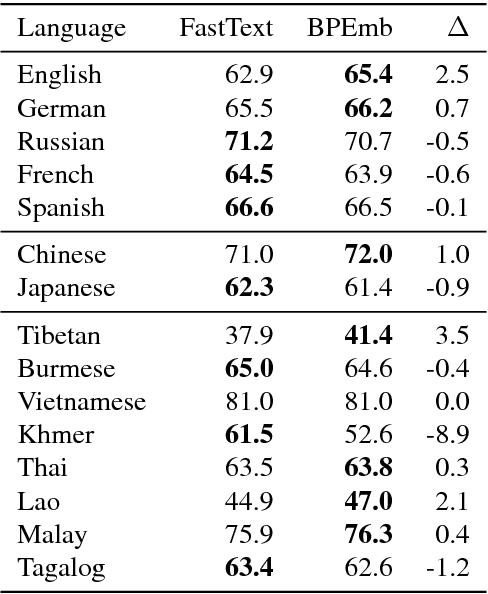
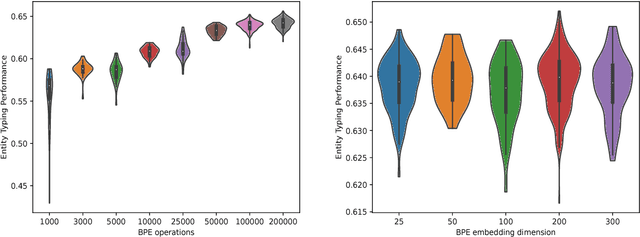
We present BPEmb, a collection of pre-trained subword unit embeddings in 275 languages, based on Byte-Pair Encoding (BPE). In an evaluation using fine-grained entity typing as testbed, BPEmb performs competitively, and for some languages bet- ter than alternative subword approaches, while requiring vastly fewer resources and no tokenization. BPEmb is available at https://github.com/bheinzerling/bpemb
View paper on