 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Iterative Motion Learning (AI-MOLE) of a SCARA Robot for Automated Myocardial Injection
Sep 10, 2024Stem cell therapy is a promising approach to treat heart insufficiency and benefits from automated myocardial injection which requires highly precise motion of a robotic manipulator that is equipped with a syringe. This work investigates whether sufficiently precise motion can be achieved by combining a SCARA robot and learning control methods. For this purpose, the method Autonomous Iterative Motion Learning (AI-MOLE) is extended to be applicable to multi-input/multi-output systems. The proposed learning method solves reference tracking tasks in systems with unknown, nonlinear, multi-input/multi-output dynamics by iteratively updating an input trajectory in a plug-and-play fashion and without requiring manual parameter tuning. The proposed learning method is validated in a preliminary simulation study of a simplified SCARA robot that has to perform three desired motions. The results demonstrate that the proposed learning method achieves highly precise reference tracking without requiring any a priori model information or manual parameter tuning in as little as 15 trials per motion. The results further indicate that the combination of a SCARA robot and learning method achieves sufficiently precise motion to potentially enable automatic myocardial injection if similar results can be obtained in a real-world setting.
AI-MOLE: Autonomous Iterative Motion Learning for Unknown Nonlinear Dynamics with Extensive Experimental Validation
Apr 09, 2024



This work proposes Autonomous Iterative Motion Learning (AI-MOLE), a method that enables systems with unknown, nonlinear dynamics to autonomously learn to solve reference tracking tasks. The method iteratively applies an input trajectory to the unknown dynamics, trains a Gaussian process model based on the experimental data, and utilizes the model to update the input trajectory until desired tracking performance is achieved. Unlike existing approaches, the proposed method determines necessary parameters automatically, i.e., AI-MOLE works plug-and-play and without manual parameter tuning. Furthermore, AI-MOLE only requires input/output information, but can also exploit available state information to accelerate learning. While other approaches are typically only validated in simulation or on a single real-world testbed using manually tuned parameters, we present the unprecedented result of validating the proposed method on three different real-world robots and a total of nine different reference tracking tasks without requiring any a priori model information or manual parameter tuning. Over all systems and tasks, AI-MOLE rapidly learns to track the references without requiring any manual parameter tuning at all, even if only input/output information is available.
* 9 pages, 6 figures, journal article
Collective Iterative Learning Control: Exploiting Diversity in Multi-Agent Systems for Reference Tracking Tasks
Apr 15, 2021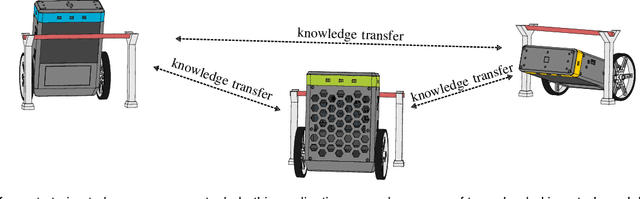
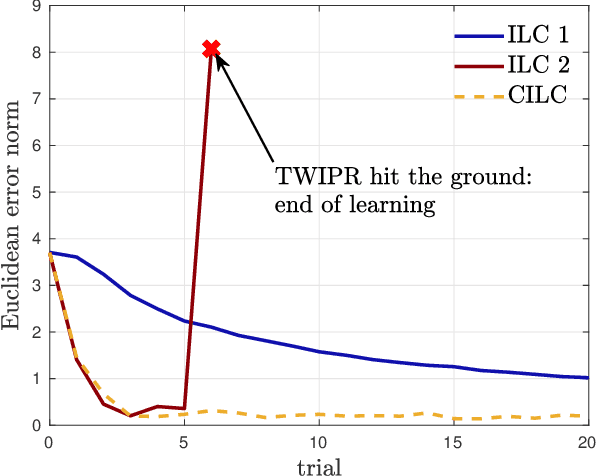
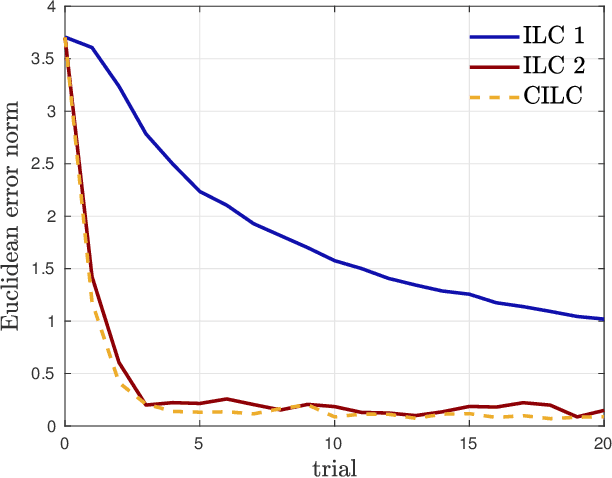
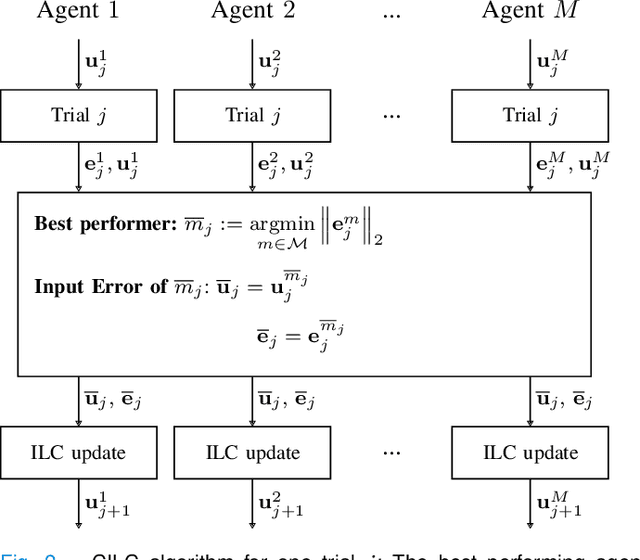
This paper considers a group of autonomous agents learning to track the same given reference trajectory in a possibly small number of trials. We propose a novel collective learning control method (namely, CILC) that combines Iterative Learning Control (ILC) with a collective input update strategy. We derive conditions for desirable convergence properties of such systems. We show that the proposed method allows the collective to combine the advantages of the agents' individual learning strategies and thereby overcomes trade-offs and limitations of single-agent ILC. This benefit is leveraged by designing a heterogeneous collective, i.e., a different learning law is assigned to each agent. All theoretical results are confirmed in simulations and experiments with two-wheeled-inverted-pendulums robots (TWIPRs) that jointly learn to perform a desired maneuver.