 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Complexity of Plan Existence and Evaluation in Probabilistic Domains
Feb 06, 2013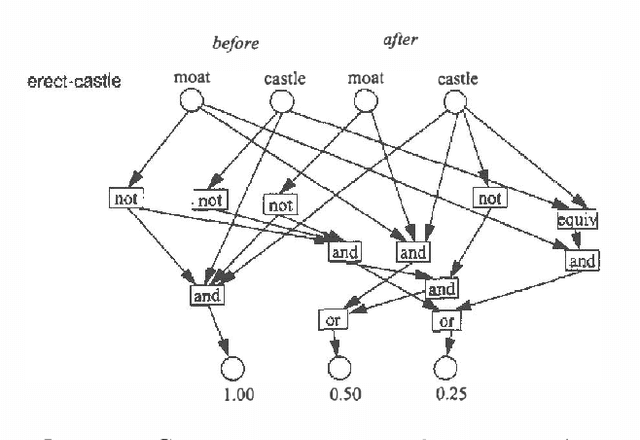

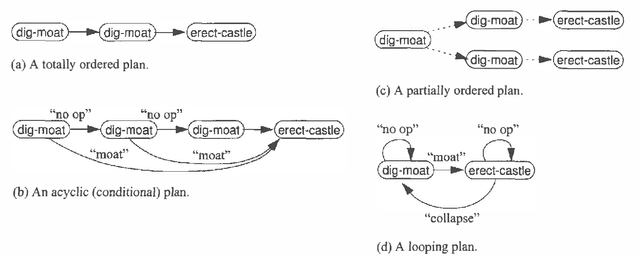

We examine the computational complexity of testing and finding small plans in probabilistic planning domains with succinct representations. We find that many problems of interest are complete for a variety of complexity classes: NP, co-NP, PP, NP^PP, co-NP^PP, and PSPACE. Of these, the probabilistic classes PP and NP^PP are likely to be of special interest in the field of uncertainty in artificial intelligence and are deserving of additional study. These results suggest a fruitful direction of future algorithmic development.
Incremental Pruning: A Simple, Fast, Exact Method for Partially Observable Markov Decision Processes
Feb 06, 2013
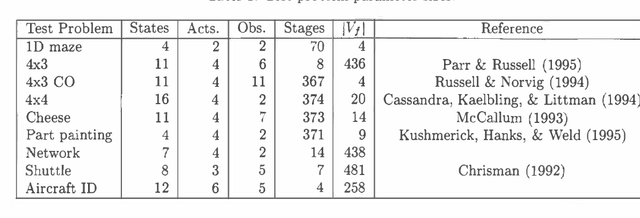
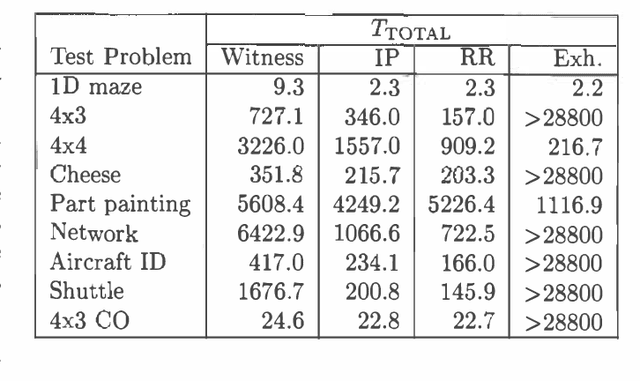
Most exact algorithms for general partially observable Markov decision processes (POMDPs) use a form of dynamic programming in which a piecewise-linear and convex representation of one value function is transformed into another. We examine variations of the "incremental pruning" method for solving this problem and compare them to earlier algorithms from theoretical and empirical perspectives. We find that incremental pruning is presently the most efficient exact method for solving POMDPs.
On the Computational Complexity of Stochastic Controller Optimization in POMDPs
Oct 04, 2012We show that the problem of finding an optimal stochastic 'blind' controller in a Markov decision process is an NP-hard problem. The corresponding decision problem is NP-hard, in PSPACE, and SQRT-SUM-hard, hence placing it in NP would imply breakthroughs in long-standing open problems in computer science. Our result establishes that the more general problem of stochastic controller optimization in POMDPs is also NP-hard. Nonetheless, we outline a special case that is convex and admits efficient global solutions.
Incremental Model-based Learners With Formal Learning-Time Guarantees
Jun 27, 2012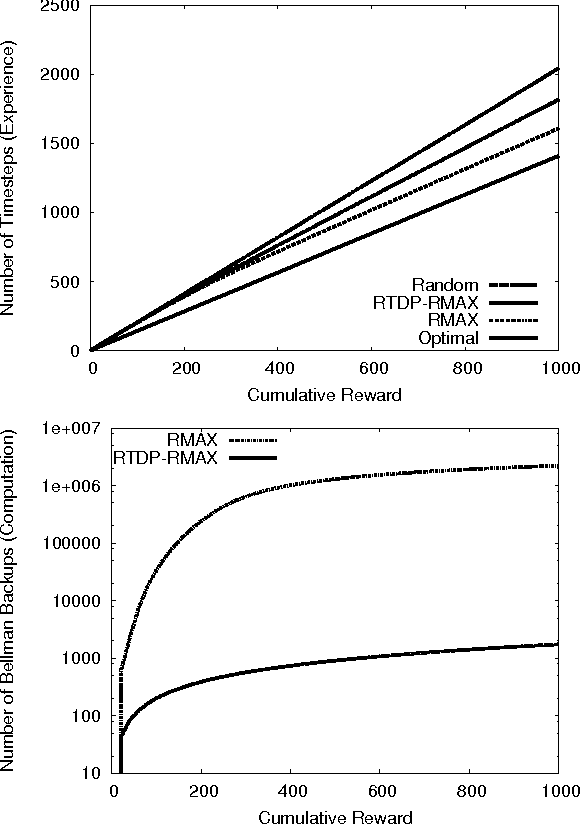
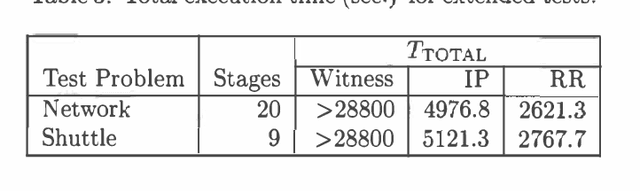
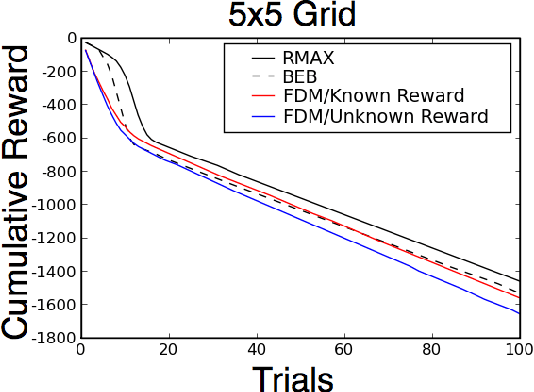
Model-based learning algorithms have been shown to use experience efficiently when learning to solve Markov Decision Processes (MDPs) with finite state and action spaces. However, their high computational cost due to repeatedly solving an internal model inhibits their use in large-scale problems. We propose a method based on real-time dynamic programming (RTDP) to speed up two model-based algorithms, RMAX and MBIE (model-based interval estimation), resulting in computationally much faster algorithms with little loss compared to existing bounds. Specifically, our two new learning algorithms, RTDP-RMAX and RTDP-IE, have considerably smaller computational demands than RMAX and MBIE. We develop a general theoretical framework that allows us to prove that both are efficient learners in a PAC (probably approximately correct) sense. We also present an experimental evaluation of these new algorithms that helps quantify the tradeoff between computational and experience demands.
CORL: A Continuous-state Offset-dynamics Reinforcement Learner
Jun 13, 2012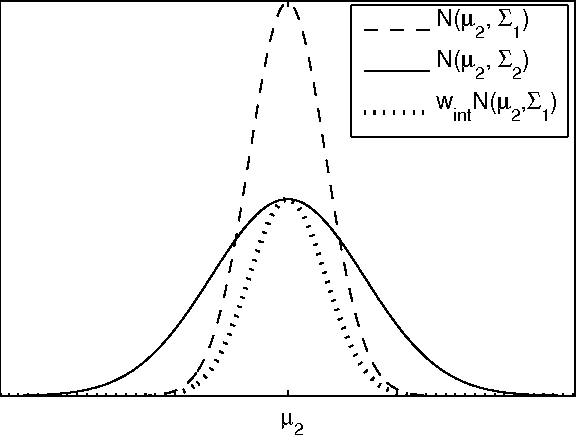

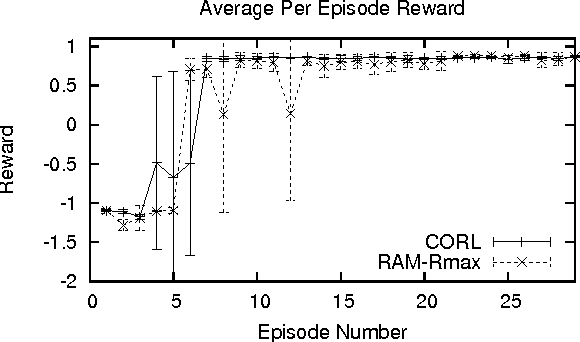
Continuous state spaces and stochastic, switching dynamics characterize a number of rich, realworld domains, such as robot navigation across varying terrain. We describe a reinforcementlearning algorithm for learning in these domains and prove for certain environments the algorithm is probably approximately correct with a sample complexity that scales polynomially with the state-space dimension. Unfortunately, no optimal planning techniques exist in general for such problems; instead we use fitted value iteration to solve the learned MDP, and include the error due to approximate planning in our bounds. Finally, we report an experiment using a robotic car driving over varying terrain to demonstrate that these dynamics representations adequately capture real-world dynamics and that our algorithm can be used to efficiently solve such problems.
Exploring compact reinforcement-learning representations with linear regression
May 09, 2012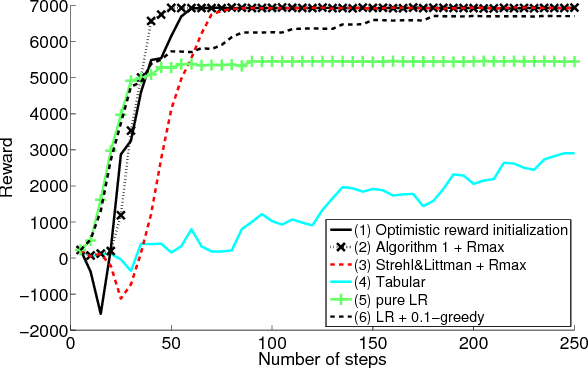

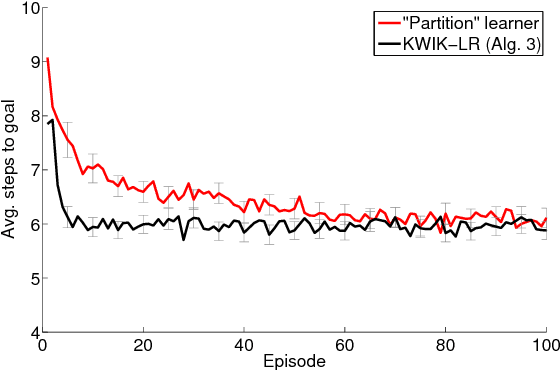
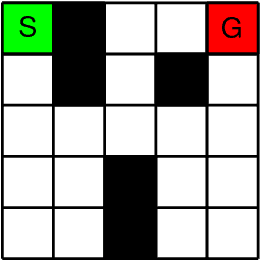
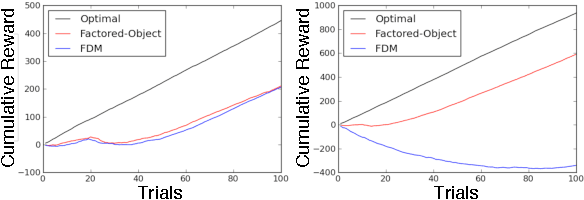
This paper presents a new algorithm for online linear regression whose efficiency guarantees satisfy the requirements of the KWIK (Knows What It Knows) framework. The algorithm improves on the complexity bounds of the current state-of-the-art procedure in this setting. We explore several applications of this algorithm for learning compact reinforcement-learning representations. We show that KWIK linear regression can be used to learn the reward function of a factored MDP and the probabilities of action outcomes in Stochastic STRIPS and Object Oriented MDPs, none of which have been proven to be efficiently learnable in the RL setting before. We also combine KWIK linear regression with other KWIK learners to learn larger portions of these models, including experiments on learning factored MDP transition and reward functions together.
A Bayesian Sampling Approach to Exploration in Reinforcement Learning
May 09, 2012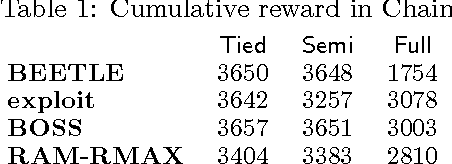
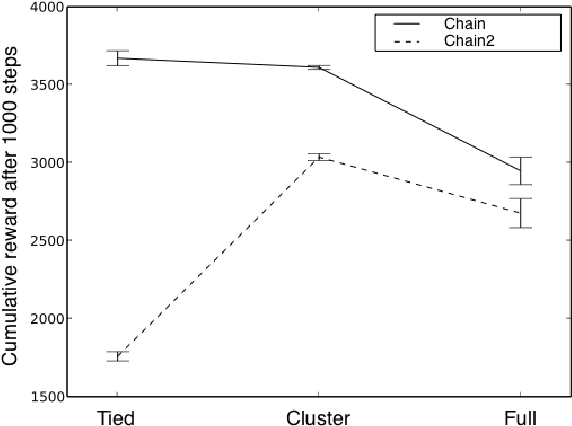
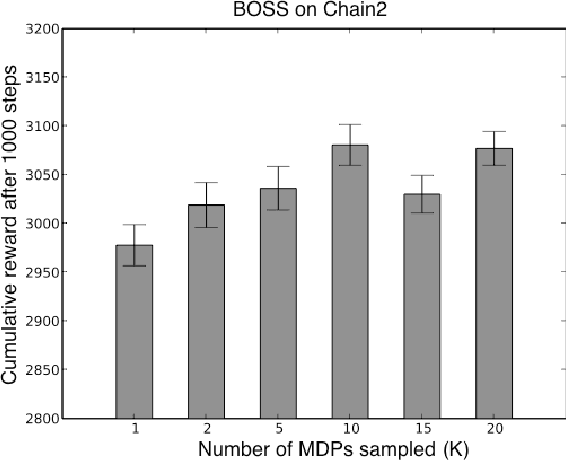
We present a modular approach to reinforcement learning that uses a Bayesian representation of the uncertainty over models. The approach, BOSS (Best of Sampled Set), drives exploration by sampling multiple models from the posterior and selecting actions optimistically. It extends previous work by providing a rule for deciding when to resample and how to combine the models. We show that our algorithm achieves nearoptimal reward with high probability with a sample complexity that is low relative to the speed at which the posterior distribution converges during learning. We demonstrate that BOSS performs quite favorably compared to state-of-the-art reinforcement-learning approaches and illustrate its flexibility by pairing it with a non-parametric model that generalizes across states.
Learning is planning: near Bayes-optimal reinforcement learning via Monte-Carlo tree search
Feb 14, 2012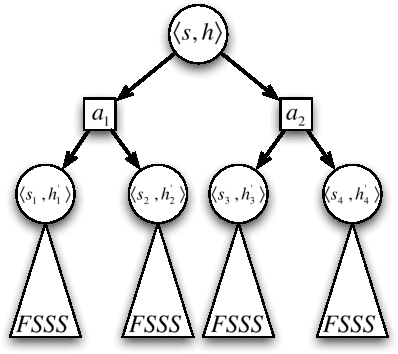
Bayes-optimal behavior, while well-defined, is often difficult to achieve. Recent advances in the use of Monte-Carlo tree search (MCTS) have shown that it is possible to act near-optimally in Markov Decision Processes (MDPs) with very large or infinite state spaces. Bayes-optimal behavior in an unknown MDP is equivalent to optimal behavior in the known belief-space MDP, although the size of this belief-space MDP grows exponentially with the amount of history retained, and is potentially infinite. We show how an agent can use one particular MCTS algorithm, Forward Search Sparse Sampling (FSSS), in an efficient way to act nearly Bayes-optimally for all but a polynomial number of steps, assuming that FSSS can be used to act efficiently in any possible underlying MDP.
Corpus-based Learning of Analogies and Semantic Relations
Aug 23, 2005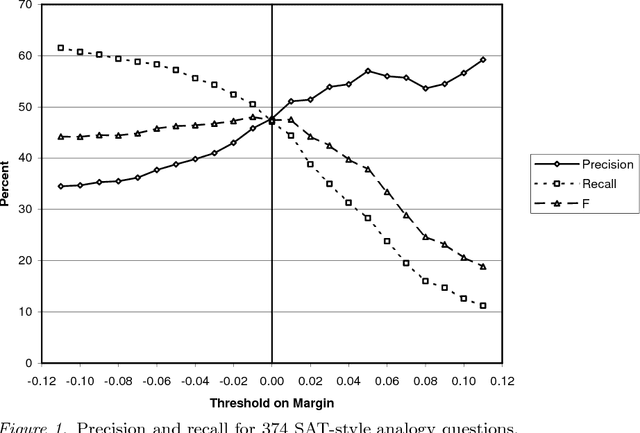
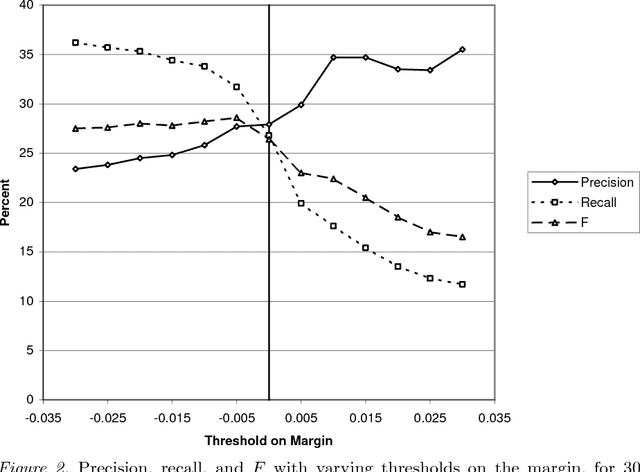
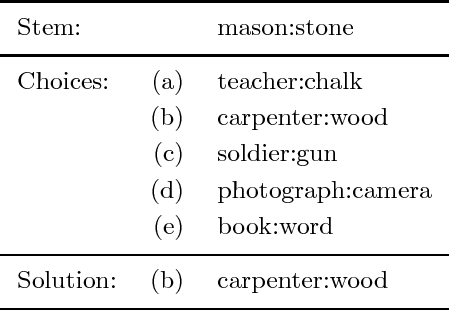
We present an algorithm for learning from unlabeled text, based on the Vector Space Model (VSM) of information retrieval, that can solve verbal analogy questions of the kind found in the SAT college entrance exam. A verbal analogy has the form A:B::C:D, meaning "A is to B as C is to D"; for example, mason:stone::carpenter:wood. SAT analogy questions provide a word pair, A:B, and the problem is to select the most analogous word pair, C:D, from a set of five choices. The VSM algorithm correctly answers 47% of a collection of 374 college-level analogy questions (random guessing would yield 20% correct; the average college-bound senior high school student answers about 57% correctly). We motivate this research by applying it to a difficult problem in natural language processing, determining semantic relations in noun-modifier pairs. The problem is to classify a noun-modifier pair, such as "laser printer", according to the semantic relation between the noun (printer) and the modifier (laser). We use a supervised nearest-neighbour algorithm that assigns a class to a given noun-modifier pair by finding the most analogous noun-modifier pair in the training data. With 30 classes of semantic relations, on a collection of 600 labeled noun-modifier pairs, the learning algorithm attains an F value of 26.5% (random guessing: 3.3%). With 5 classes of semantic relations, the F value is 43.2% (random: 20%). The performance is state-of-the-art for both verbal analogies and noun-modifier relations.
* related work available at http://purl.org/peter.turney/ and http://www.cs.rutgers.edu/~mlittman/
Combining Independent Modules in Lexical Multiple-Choice Problems
Jan 10, 2005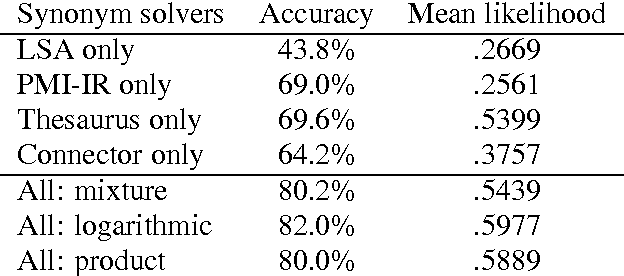
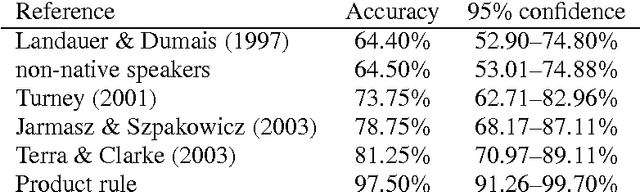
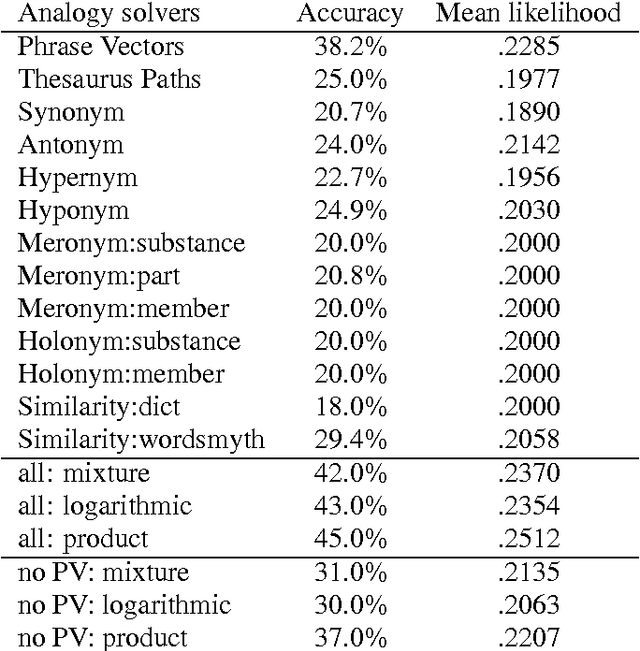
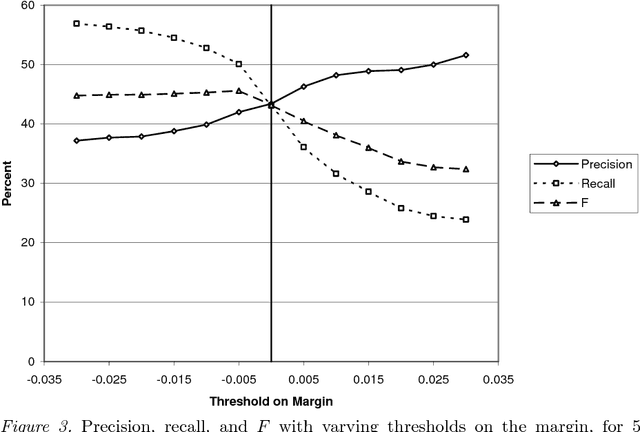
Existing statistical approaches to natural language problems are very coarse approximations to the true complexity of language processing. As such, no single technique will be best for all problem instances. Many researchers are examining ensemble methods that combine the output of multiple modules to create more accurate solutions. This paper examines three merging rules for combining probability distributions: the familiar mixture rule, the logarithmic rule, and a novel product rule. These rules were applied with state-of-the-art results to two problems used to assess human mastery of lexical semantics -- synonym questions and analogy questions. All three merging rules result in ensembles that are more accurate than any of their component modules. The differences among the three rules are not statistically significant, but it is suggestive that the popular mixture rule is not the best rule for either of the two problems.
* 10 pages, related work available at http://www.cs.rutgers.edu/~mlittman/ and http://purl.org/peter.turney/