 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterim Report on Human-Guided Adaptive Hyperparameter Optimization with Multi-Fidelity Sprints
May 14, 2025This case study applies a phased hyperparameter optimization process to compare multitask natural language model variants that utilize multiphase learning rate scheduling and optimizer parameter grouping. We employ short, Bayesian optimization sessions that leverage multi-fidelity, hyperparameter space pruning, progressive halving, and a degree of human guidance. We utilize the Optuna TPE sampler and Hyperband pruner, as well as the Scikit-Learn Gaussian process minimization. Initially, we use efficient low-fidelity sprints to prune the hyperparameter space. Subsequent sprints progressively increase their model fidelity and employ hyperband pruning for efficiency. A second aspect of our approach is using a meta-learner to tune threshold values to resolve classification probabilities during inference. We demonstrate our method on a collection of variants of the 2021 Joint Entity and Relation Extraction model proposed by Eberts and Ulges.
Detecting Language Model Attacks with Perplexity
Aug 27, 2023A novel hack involving Large Language Models (LLMs) has emerged, leveraging adversarial suffixes to trick models into generating perilous responses. This method has garnered considerable attention from reputable media outlets such as the New York Times and Wired, thereby influencing public perception regarding the security and safety of LLMs. In this study, we advocate the utilization of perplexity as one of the means to recognize such potential attacks. The underlying concept behind these hacks revolves around appending an unusually constructed string of text to a harmful query that would otherwise be blocked. This maneuver confuses the protective mechanisms and tricks the model into generating a forbidden response. Such scenarios could result in providing detailed instructions to a malicious user for constructing explosives or orchestrating a bank heist. Our investigation demonstrates the feasibility of employing perplexity, a prevalent natural language processing metric, to detect these adversarial tactics before generating a forbidden response. By evaluating the perplexity of queries with and without such adversarial suffixes using an open-source LLM, we discovered that nearly 90 percent were above a perplexity of 1000. This contrast underscores the efficacy of perplexity for detecting this type of exploit.
What Can Secondary Predictions Tell Us? An Exploration on Question-Answering with SQuAD-v2.0
Jun 29, 2022
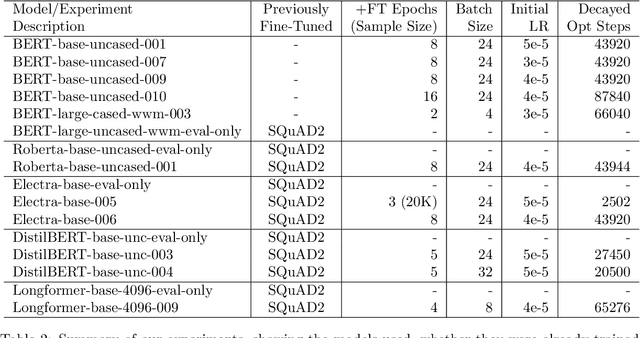


Performance in natural language processing, and specifically for the question-answer task, is typically measured by comparing a model\'s most confident (primary) prediction to golden answers (the ground truth). We are making the case that it is also useful to quantify how close a model came to predicting a correct answer even for examples that failed. We define the Golden Rank (GR) of an example as the rank of its most confident prediction that exactly matches a ground truth, and show why such a match always exists. For the 16 transformer models we analyzed, the majority of exactly matched golden answers in secondary prediction space hover very close to the top rank. We refer to secondary predictions as those ranking above 0 in descending confidence probability order. We demonstrate how the GR can be used to classify questions and visualize their spectrum of difficulty, from persistent near successes to persistent extreme failures. We derive a new aggregate statistic over entire test sets, named the Golden Rank Interpolated Median (GRIM) that quantifies the proximity of failed predictions to the top choice made by the model. To develop some intuition and explore the applicability of these metrics we use the Stanford Question Answering Dataset (SQuAD-2) and a few popular transformer models from the Hugging Face hub. We first demonstrate that the GRIM is not directly correlated with the F1 and exact match (EM) scores. We then calculate and visualize these scores for various transformer architectures, probe their applicability in error analysis by clustering failed predictions, and compare how they relate to other training diagnostics such as the EM and F1 scores. We finally suggest various research goals, such as broadening data collection for these metrics and their possible use in adversarial training.