 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe KL3M Data Project: Copyright-Clean Training Resources for Large Language Models
Apr 10, 2025Practically all large language models have been pre-trained on data that is subject to global uncertainty related to copyright infringement and breach of contract. This creates potential risk for users and developers due to this uncertain legal status. The KL3M Data Project directly confronts this critical issue by introducing the largest comprehensive training data pipeline that minimizes risks related to copyright or breach of contract. The foundation of this project is a corpus of over 132 million documents and trillions of tokens spanning 16 different sources that have been verified to meet the strict copyright and licensing protocol detailed herein. We are releasing the entire pipeline, including 1) the source code to acquire and process these documents, 2) the original document formats with associated provenance and metadata, 3) extracted content in a standardized format, 4) pre-tokenized representations of the documents, and 5) various mid- and post-train resources such as question-answer, summarization, conversion, drafting, classification, prediction, and conversational data. All of these resources are freely available to the public on S3, Hugging Face, and GitHub under CC-BY terms. We are committed to continuing this project in furtherance of a more ethical, legal, and sustainable approach to the development and use of AI models.
OpenEDGAR: Open Source Software for SEC EDGAR Analysis
Jun 13, 2018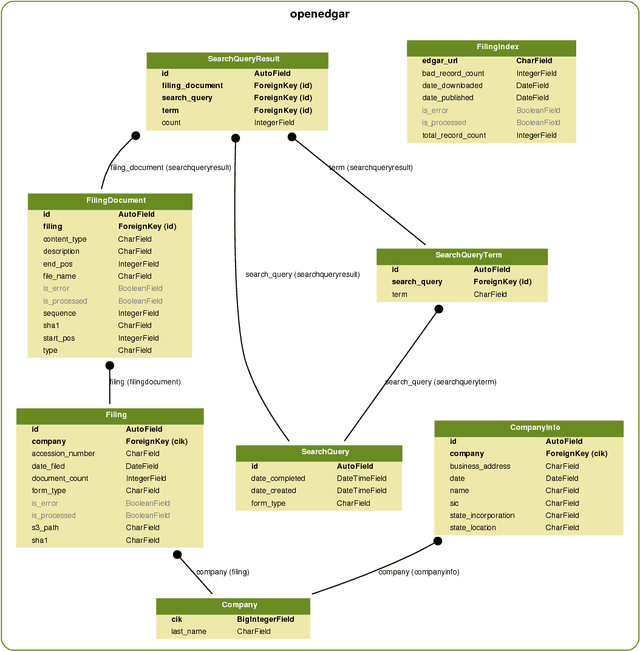
OpenEDGAR is an open source Python framework designed to rapidly construct research databases based on the Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system operated by the US Securities and Exchange Commission (SEC). OpenEDGAR is built on the Django application framework, supports distributed compute across one or more servers, and includes functionality to (i) retrieve and parse index and filing data from EDGAR, (ii) build tables for key metadata like form type and filer, (iii) retrieve, parse, and update CIK to ticker and industry mappings, (iv) extract content and metadata from filing documents, and (v) search filing document contents. OpenEDGAR is designed for use in both academic research and industrial applications, and is distributed under MIT License at https://github.com/LexPredict/openedgar.
LexNLP: Natural language processing and information extraction for legal and regulatory texts
Jun 10, 2018LexNLP is an open source Python package focused on natural language processing and machine learning for legal and regulatory text. The package includes functionality to (i) segment documents, (ii) identify key text such as titles and section headings, (iii) extract over eighteen types of structured information like distances and dates, (iv) extract named entities such as companies and geopolitical entities, (v) transform text into features for model training, and (vi) build unsupervised and supervised models such as word embedding or tagging models. LexNLP includes pre-trained models based on thousands of unit tests drawn from real documents available from the SEC EDGAR database as well as various judicial and regulatory proceedings. LexNLP is designed for use in both academic research and industrial applications, and is distributed at https://github.com/LexPredict/lexpredict-lexnlp.