 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Mechanical Turk to Build Machine Translation Evaluation Sets
Oct 20, 2014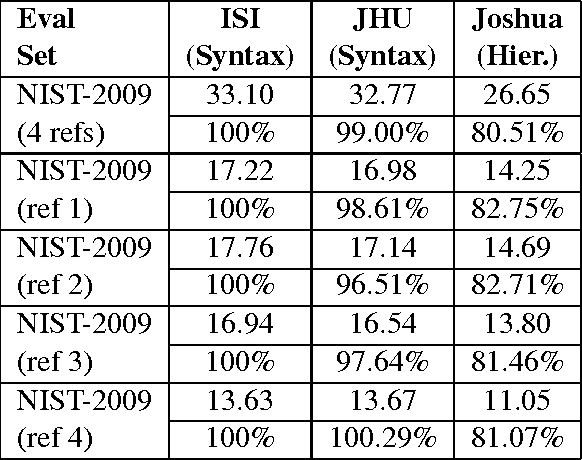
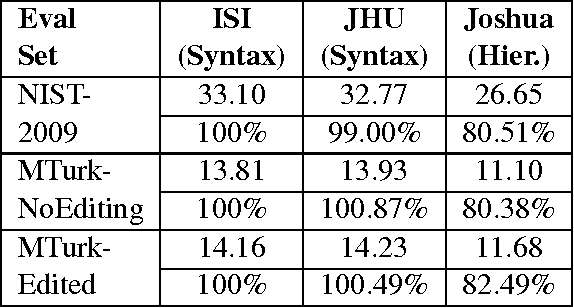
Building machine translation (MT) test sets is a relatively expensive task. As MT becomes increasingly desired for more and more language pairs and more and more domains, it becomes necessary to build test sets for each case. In this paper, we investigate using Amazon's Mechanical Turk (MTurk) to make MT test sets cheaply. We find that MTurk can be used to make test sets much cheaper than professionally-produced test sets. More importantly, in experiments with multiple MT systems, we find that the MTurk-produced test sets yield essentially the same conclusions regarding system performance as the professionally-produced test sets yield.
* 4 pages, 2 tables; appeared in Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon's Mechanical Turk, June 2010
A Modality Lexicon and its use in Automatic Tagging
Oct 17, 2014

This paper describes our resource-building results for an eight-week JHU Human Language Technology Center of Excellence Summer Camp for Applied Language Exploration (SCALE-2009) on Semantically-Informed Machine Translation. Specifically, we describe the construction of a modality annotation scheme, a modality lexicon, and two automated modality taggers that were built using the lexicon and annotation scheme. Our annotation scheme is based on identifying three components of modality: a trigger, a target and a holder. We describe how our modality lexicon was produced semi-automatically, expanding from an initial hand-selected list of modality trigger words and phrases. The resulting expanded modality lexicon is being made publicly available. We demonstrate that one tagger---a structure-based tagger---results in precision around 86% (depending on genre) for tagging of a standard LDC data set. In a machine translation application, using the structure-based tagger to annotate English modalities on an English-Urdu training corpus improved the translation quality score for Urdu by 0.3 Bleu points in the face of sparse training data.
* 6 pages, 5 figures; appeared in Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC'10), May 2010
Semantically-Informed Syntactic Machine Translation: A Tree-Grafting Approach
Sep 24, 2014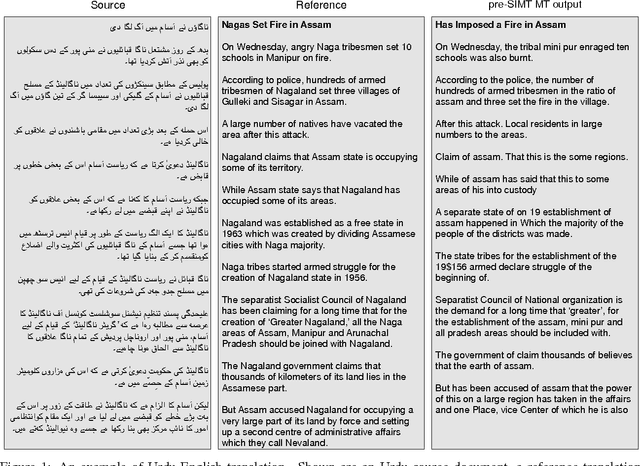
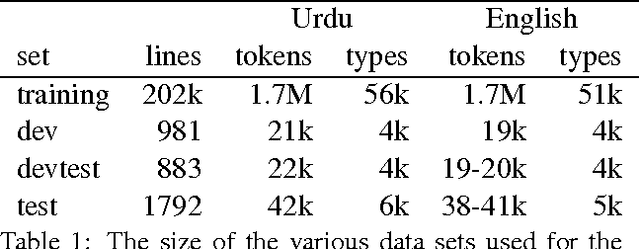
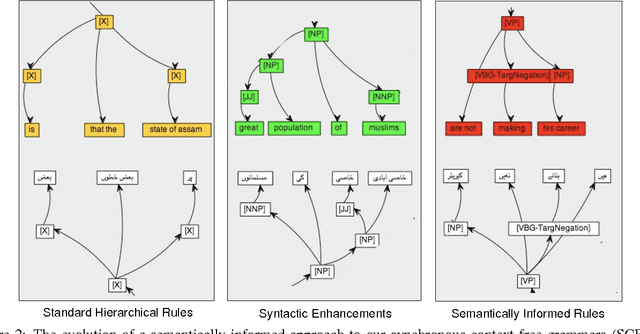

We describe a unified and coherent syntactic framework for supporting a semantically-informed syntactic approach to statistical machine translation. Semantically enriched syntactic tags assigned to the target-language training texts improved translation quality. The resulting system significantly outperformed a linguistically naive baseline model (Hiero), and reached the highest scores yet reported on the NIST 2009 Urdu-English translation task. This finding supports the hypothesis (posed by many researchers in the MT community, e.g., in DARPA GALE) that both syntactic and semantic information are critical for improving translation quality---and further demonstrates that large gains can be achieved for low-resource languages with different word order than English.
* 10 pages, 7 figures, 3 tables; appeared in Proceedings of the Ninth Conference of the Association for Machine Translation in the Americas (AMTA), October 2010
A Method for Stopping Active Learning Based on Stabilizing Predictions and the Need for User-Adjustable Stopping
Sep 17, 2014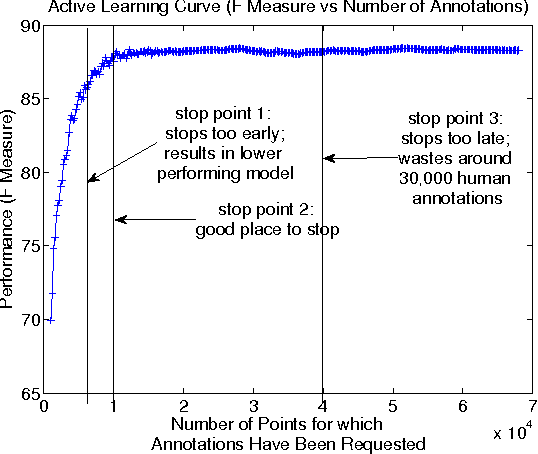
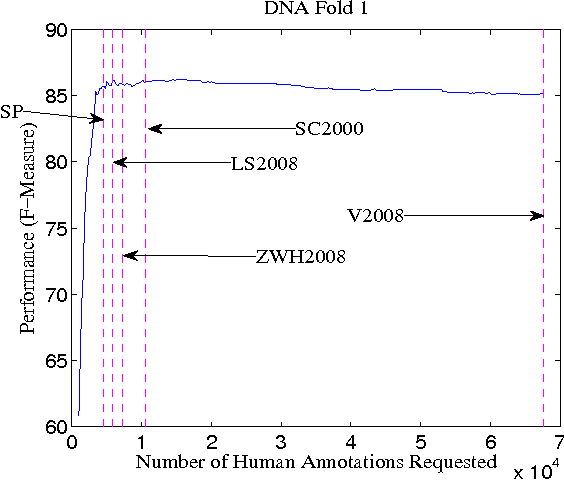
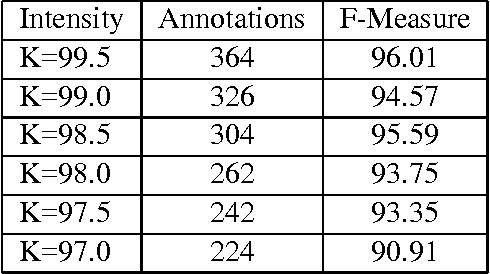
A survey of existing methods for stopping active learning (AL) reveals the needs for methods that are: more widely applicable; more aggressive in saving annotations; and more stable across changing datasets. A new method for stopping AL based on stabilizing predictions is presented that addresses these needs. Furthermore, stopping methods are required to handle a broad range of different annotation/performance tradeoff valuations. Despite this, the existing body of work is dominated by conservative methods with little (if any) attention paid to providing users with control over the behavior of stopping methods. The proposed method is shown to fill a gap in the level of aggressiveness available for stopping AL and supports providing users with control over stopping behavior.
* 9 pages, 3 figures, 5 tables; appeared in Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL-2009), June 2009
Taking into Account the Differences between Actively and Passively Acquired Data: The Case of Active Learning with Support Vector Machines for Imbalanced Datasets
Sep 17, 2014
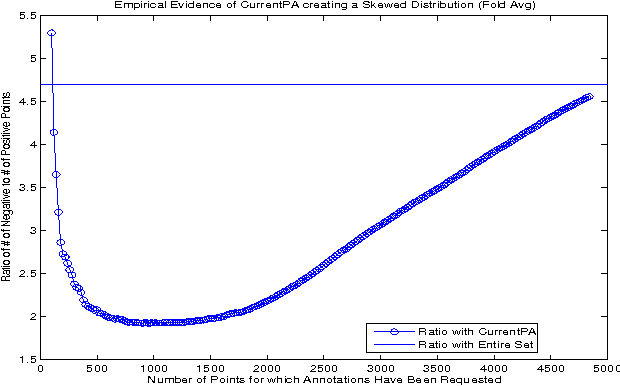
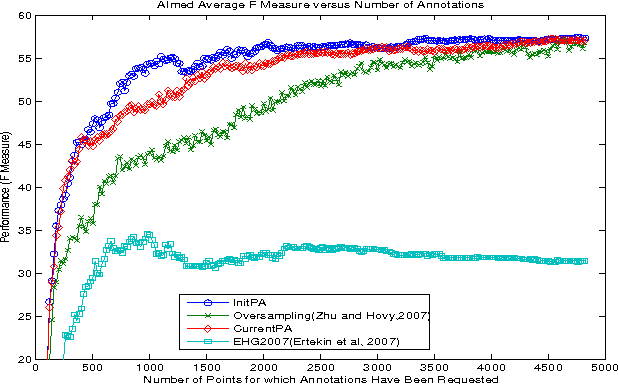
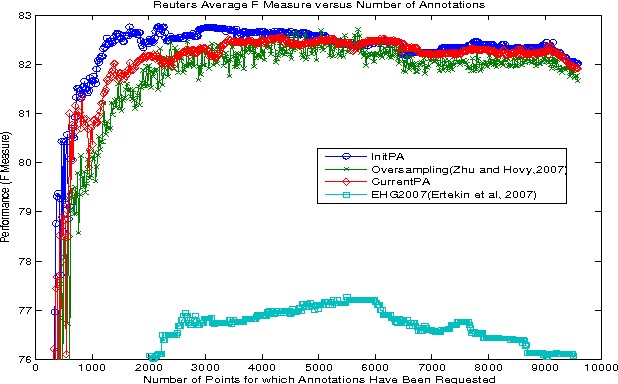
Actively sampled data can have very different characteristics than passively sampled data. Therefore, it's promising to investigate using different inference procedures during AL than are used during passive learning (PL). This general idea is explored in detail for the focused case of AL with cost-weighted SVMs for imbalanced data, a situation that arises for many HLT tasks. The key idea behind the proposed InitPA method for addressing imbalance is to base cost models during AL on an estimate of overall corpus imbalance computed via a small unbiased sample rather than the imbalance in the labeled training data, which is the leading method used during PL.
* 4 pages, 5 figures; appeared in Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Companion Volume: Short Papers, pages 137-140, Boulder, Colorado, June 2009. Association for Computational Linguistics
An Approach to Reducing Annotation Costs for BioNLP
Sep 12, 2014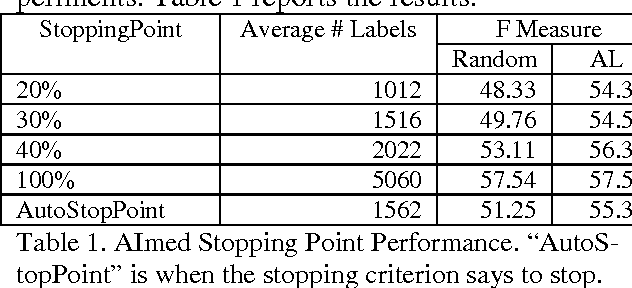
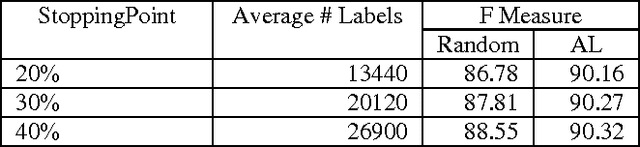

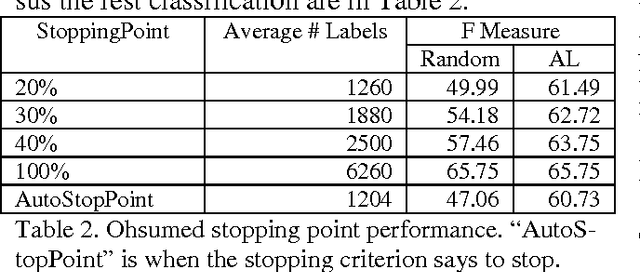
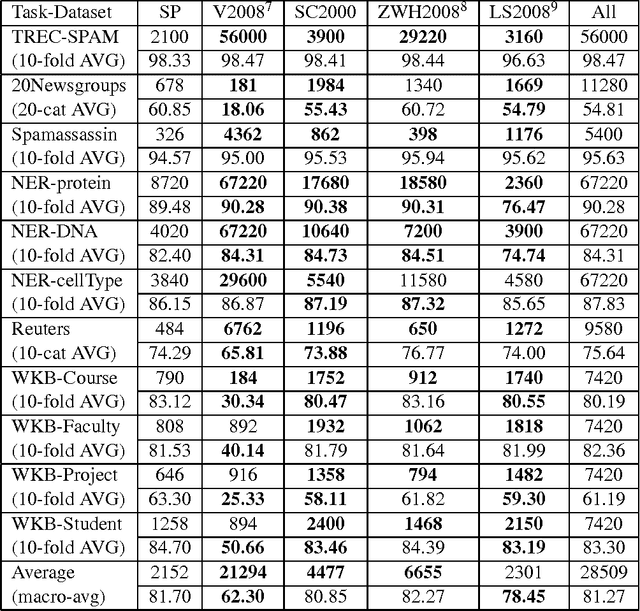
There is a broad range of BioNLP tasks for which active learning (AL) can significantly reduce annotation costs and a specific AL algorithm we have developed is particularly effective in reducing annotation costs for these tasks. We have previously developed an AL algorithm called ClosestInitPA that works best with tasks that have the following characteristics: redundancy in training material, burdensome annotation costs, Support Vector Machines (SVMs) work well for the task, and imbalanced datasets (i.e. when set up as a binary classification problem, one class is substantially rarer than the other). Many BioNLP tasks have these characteristics and thus our AL algorithm is a natural approach to apply to BioNLP tasks.
* 2 pages, 1 figure, 5 tables; appeared in Proceedings of the Workshop on Current Trends in Biomedical Natural Language Processing at ACL (Association for Computational Linguistics) 2008